使用機器學習解決問題 : 人臉辨識

source: Pixabay
前言 & 概述
本篇為機器學習基礎觀念的第 10 篇文章。在前幾篇文章中,我們介紹了機器學習的五步驟 (定義問題、建立資料集、模型訓練、模型評估與模型推論),並說明如何應用在「房價預測」(監督式學習) 與「探索書籍風格」(非監督式學習) 的問題上。
在上述兩個問題中,我們分別使用了 Linear Regression Model 與 K-Means Clustering Model,皆屬於傳統的機器學習模型。在本篇文章中,我們將學習更厲害與更現代的模型解決「人臉辨識」(Face Recognition) 問題。
Step 1 : 定義問題
「人臉辨識」(Face Recognition) 技術廣泛應用於生活中,從解鎖手機到進出社區大門,都因為這項技術而變得更加便利。
現在請想像一個情境,你是一個非常注重隱私的人,你希望在你去工作的這段時間,調皮的弟弟不得任意進出你的房間。你也懶得去打一把鑰匙,因為你覺得自己一定會把他弄丟。因此,你希望打造一個人臉辨識系統,只有辨識你的人臉時,電子門鎖才能開啟。
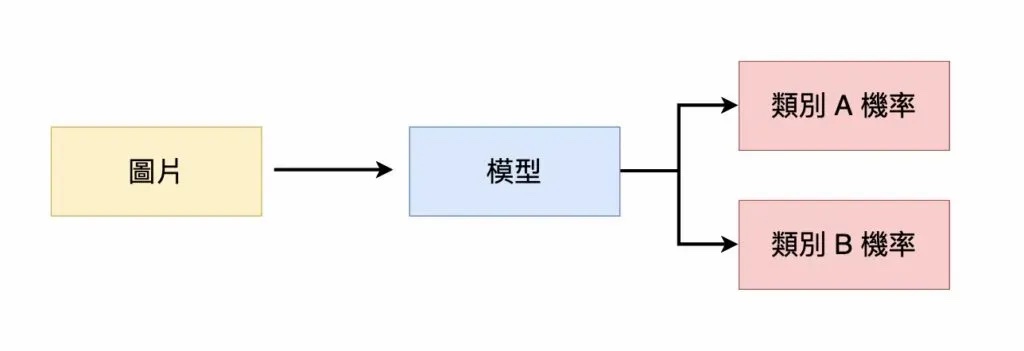
將圖片輸入到模型中,模型輸出兩個類別的機率
為了建立一個人臉辨識系統,必須訓練出一個能夠分辨「你的人臉」的模型。我們希望輸入「一張圖片」到模型中,模型會輸出這張圖片所屬的「類別」。我們事先定義好兩種類別:
- 類別 A:圖片中包含你的人臉
- 類別 B:圖片中不包含你的人臉
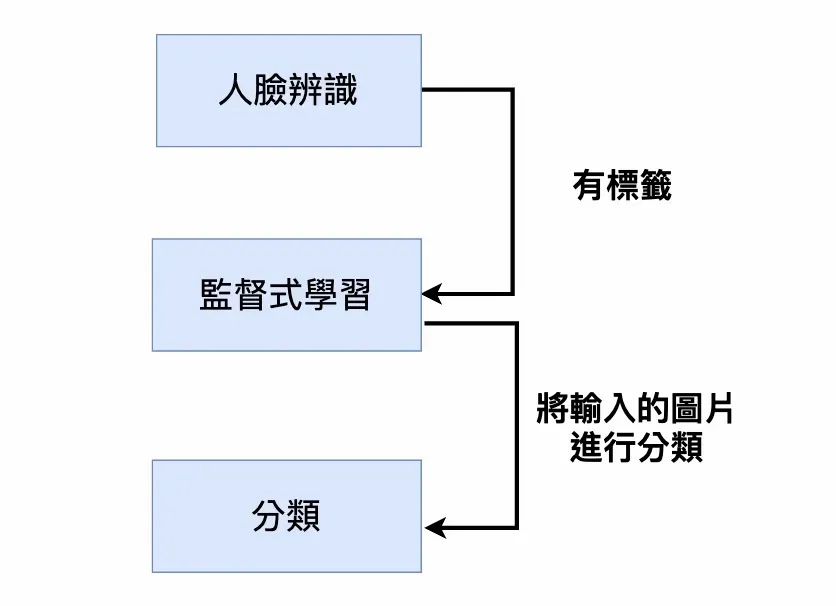
定義「人臉辨識」屬於什麼問題
為了建立這樣的模型,我們會準備大量的圖片,每張圖片有兩種可能:有你的人臉 (類別 A) 或是沒有你的人臉 (類別 B)。因為我們會事先將這些圖片標注好所屬的類別,因此屬於「監督式學習」(Supervised Learning)。此外,輸入圖片到模型後,模型會輸出該圖片的「類別」,因此屬於「分類」(Classification) 任務。
Step 2 : 建立資料集
建立資料集的過程主要可以分為以下階段:
- 收集資料 (Data Collection)
如果我們希望「從零」打造並訓練模型的話,我們必須準備大量的圖片。這些圖片必須已經標註好所屬的類別。如果我們準備的圖片數量不足的話,可能會導致模型在訓練過程中出現「過擬合」(Overfitting) 的情形。此時,就可以透過 Data Augmentation 技術來克服此問題。 - 資料探索 (Data Exploration) 與資料清理 (Data Cleaning)
資料集的品質將會大大影響模型的好壞,因此我們要盡可能提升圖片的品質與確保圖片的標注正確。例如,將模糊的圖片去除、檢查圖片的標籤是否正確。我們也可以透過程式將所有圖片的尺寸與格式統一,利於後續的模型訓練。 - 資料向量化 (Data Vectorization)
模型接受的輸入為「數值」而非「圖片」,因此我們會透過程式將圖片轉為矩陣的形式,才能輸入模型中。以下圖為例,左邊是一張黑白圖片,右邊則是表示這張圖片的矩陣。矩陣中的 0 表示該 Pixel 為「黑」、1 表示該 Pixel 為「白」。若為彩色圖片,因為是由 RGB 3 個 Channel 所組成,因此可以透過 3 個矩陣來表示彩色圖片。

將圖片以矩陣來表示
- 分割資料 (Split Data)
為了在模型訓練過後,能夠使用模型不曾看過的資料來評估模型的品質,我們會事先將整個 Dataset 拆分為 Training Dataset 與 Testing Dataset,通常比例為 80% : 20%。透過 Training Dataset 訓練模型,再透過 Testing Dataset 評估模型。
Step 3 : 模型訓練
不同於前兩篇文章,我們使用傳統的機器學習模型 (Linear Regression Model、K-Means Clustering Model),在人臉辨識 (Face Recognition) 的問題中,我們使用神經網路模型 (Neurak Network) 來解決此問題。
相較於傳統的機器學習模型,神經網路模型能夠處理的問題更多也更困難。在本文中,我們將不會深入的介紹神經網路模型。
神經網路模型中又包含了非常多種類的模型,每種模型適合處理不同的任務。在定義問題中,我們已經將「人臉辨識」視為「圖像分類」(Image Classification) 的問題。針對「圖像」這種輸入資料,神經網路模型中的「卷積神經網路」 (Convolutional neural network, CNN) 是第一首選,CNN 善於將圖像中重要的特徵萃取出來,進而提升圖像分類模型的預測準確度。
Step 4 : 模型評估
模型訓練完畢後,我們會使用 Testing Dataset 搭配一些統計指標 (Statistical Metrics) 衡量模型的品質。最直覺的 Metrics 為 Accuracy,單純計算模型的準確率。然而,根據問題本身的特性,僅用 Accuracy 並沒有辦法有效評估模型,因而出現了 Confusion Matrix、Precision、Recall 與 ROC Curve 等指標。我們將會在未來的文章中和大家介紹。
Step 5 : 模型推論
模型經過評估通過後,我們可以開始使用模型作為你的「房間守衛」。每次攝影機拍攝一張圖片後,就可以輸入至模型中,由模型預測該圖片的類別,並採取相對應的措施。
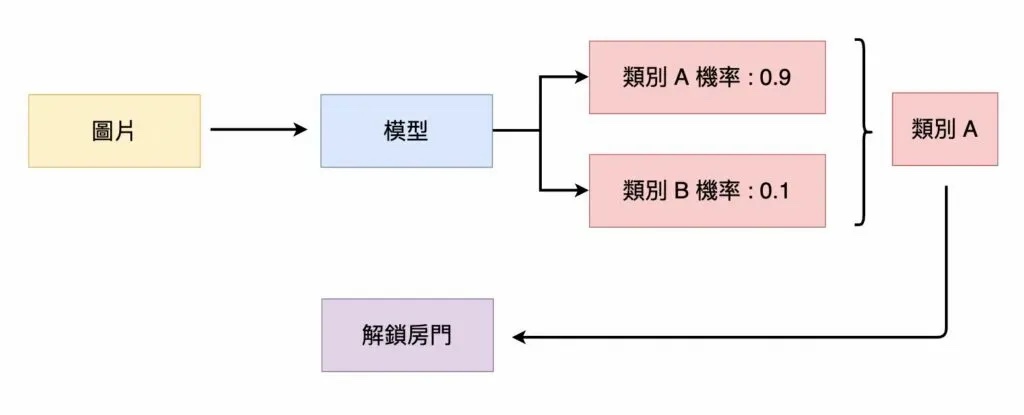
輸入圖片至模型中,如果該圖片屬於類別 A 的機率較高,則「解鎖房門」
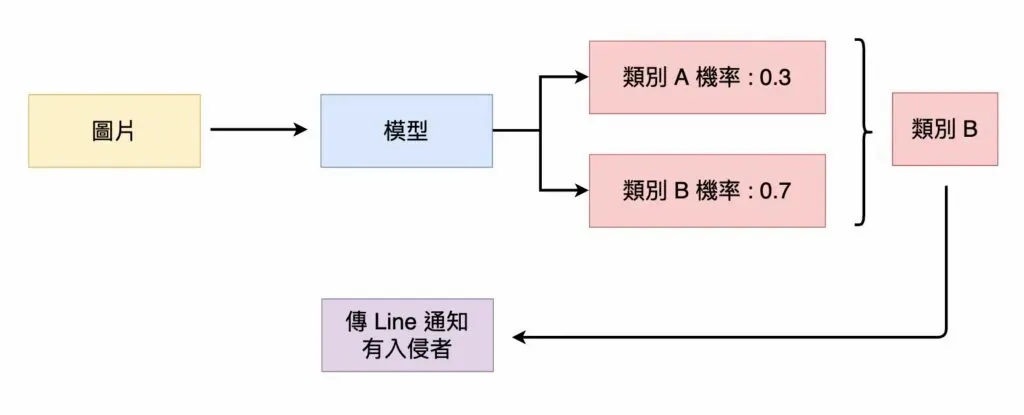
輸入圖片至模型中,如果該圖片屬於類別 B 的機率較高,則「發出警報」
結語
在本文中,我們再次歷經機器學習五步驟解決「人臉辨識」的問題。人臉辨識 (Face Recognition) 對於電腦而言算是相當困難的任務,透過神經網路 (Neural Network) 的技術,大幅提升電腦在此任務的準確度,使得人臉辨識的技術廣泛應用於日常生活中,讓我們的生活更加便利。