使用機器學習解決問題的五步驟 : 建立資料集

source: Pixabay
前言 & 概述
本篇為機器學習入門觀念的第四篇文章。在前一篇文章中,我們了解到如果要使用機器學習解決問題,所經過的五個步驟。也說明了第一個步驟「定義問題」的意義。本篇文章中,我們將會學習第二步驟「建立資料集」的概念。
建立資料集的意義
用機器學習解決問題的第二步驟:建立資料集
「建立資料集」可以說是五個步驟中最重要的一步,因為當我們想透過機器學習的技術解決問題時,「資料」是一定需要準備的,且資料品質的好壞也會大大影響最後訓練出來的模型。

資料集準備與前處理佔據機器學習專案的大量時間
根據統計,利用機器學習解決任務時,「資料準備」花了將近 80% 的時間,「其他步驟」則總共使用 20% 的時間。可見資料準備的過程其實相當的重要也不簡單!
建立資料集的步驟
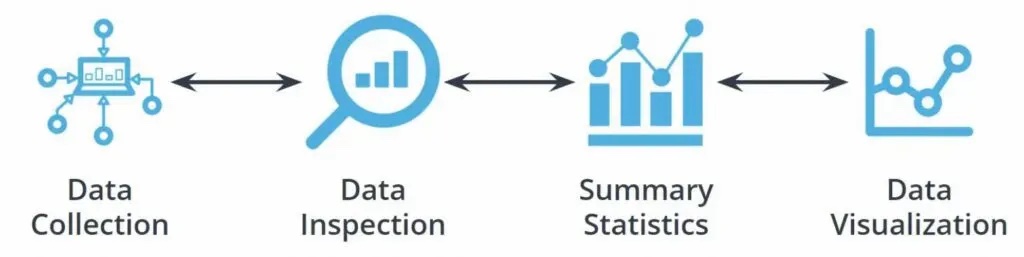
機器學習中資料集的準備包含四個步驟
建立資料集的過程又可以拆分成以下 4 個步驟:
- Data Collection
- Data Inspection
- Summary Statistics
- Data Visualization
想要訓練出一個高品質的機器學習模型,資料數據的好壞相當重要,接下來我們依序說明每一個步驟的意義。
Data Collection
Data Collection 顧名思義即是「收集資料」。收集資料可能很容易也可能很困難。舉例來說,根據不同的機器學習任務,網路上多可以找到已經整理好的資料集。但是若找不到現成的資料集,可能就要自己寫一個「爬蟲程式」在網路上爬取大量的資料。
這個步驟的關鍵在於:收集到的資料是否符合上一步驟中定義的機器學習任務 ?
Data Inspection
Data Inspection 即是「檢查資料」。如同上述所言,想要訓練出高品質的機器學習模型,資料的品質相當重要。網路上開源的資料集的品質參差不齊,因此必須先經過檢查後才拿來訓練模型。
資料檢查可以朝以下三個方向前進:
- 資料集中的離群值 (Outlier)
- 資料集中的缺失數據 (Missing Value)
- 資料是否需進行預處理 (Preprocessed) 才能輸入模型
在不同的任務中,對於上述三種問題也有相對應的解決方法,將會在未來的文章中介紹。
Summary Statistics
Summary Statistics 的概念為:對我們手上已經處理過的資料進行統計分析。透過一些統計指標,我們可以對資料集有初步的認知。例如,了解資料集的平均值 (Mean)、中位數 (Median)、最大與最小值 (Max & Min) 與標準差 (Standard Deviation)。上述僅為統計中的基本指標,讓我們對於資料集數值的分佈有初步理解。
Data Visualization
透過多種圖表進行資料視覺化 [source: FineReport]
Data Visualization 也就是「資料視覺化」。透過各種類型的圖表將資料「視覺化」,也就是資料不再是生硬的數字,而是一張張有意義的圖表。將資料視覺化後,我們可以更容易找到離群值 (Outlier) 或是趨勢 (Trend)。
結語
在本篇文章中,我們介紹了使用「機器學習解決問題五步驟」中的第二個步驟——「建立資料集」,也了解到資料集的準備是最重要的步驟。資料品質的好壞將大大影響訓練出來的模型!在下一篇文章中,將會介紹第三步驟——「模型訓練」。