使用機器學習解決問題 : 房價預測

source: Pixabay
前言 & 概述
本篇為機器學習基礎觀念的第 8 篇文章。在前五篇文章中,我們依序了解機器學習五步驟 : 定義問題、建立資料集、模型訓練、模型評估與模型推論。在本篇文章中,將會重新應用這五步驟來解決「房價預測」的問題。
房價預測經常作為理解機器學習原理的例子,如果你已經具備機器學習的基本觀念,也可以參與 Kaggle 上的 House Prices – Advanced Regression Techniques 競賽,透過此競賽強化觀念。
Step 1 : 定義問題
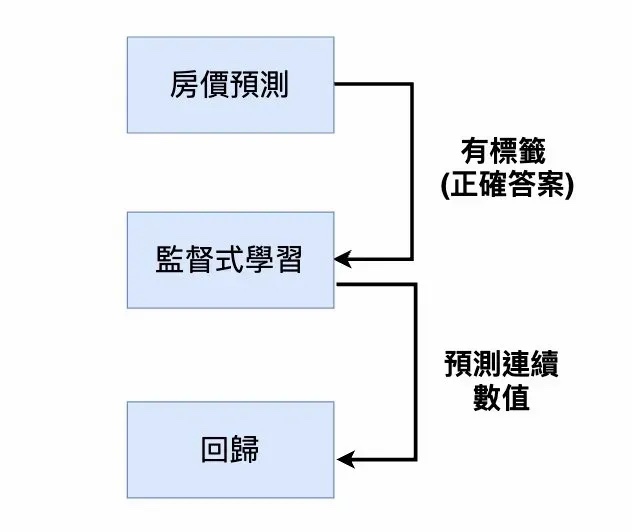
定義問題
在房價預測的任務中,我們希望模型可以觀察房子本身的「屬性」(房間數量、衛浴數量、坪數、地理位置) 來預測房子的價格。因此,我們會收集到許多樣本,每個樣本都代表著一間房子。樣本中紀錄著該房子的種種屬性以及目前的售價。如下圖所示 :
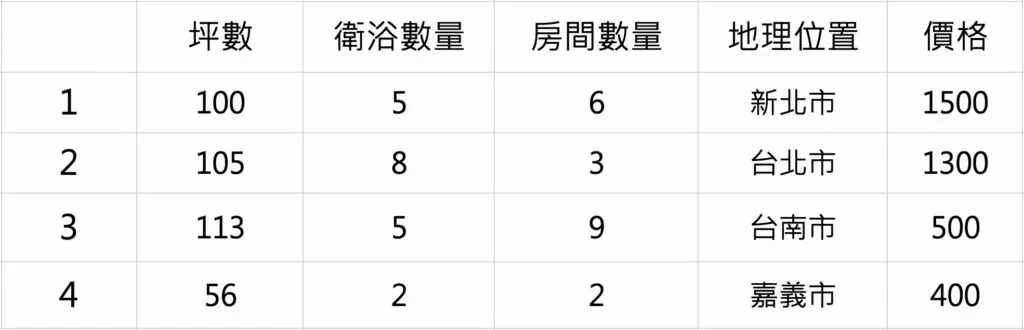
範例房價資料集
因為我們已經有了每一間房子的「價格」(正確答案),因此這個問題屬於「監督式學習」(Supervised Learning)。此外,模型的預測結果為「連續數值」而非類別,因此為「回歸」(Regression) 問題。
Step 2 : 建立資料集
建立資料集的過程主要包含以下步驟 :
- 收集資料 (Data Collection)
資料集的取得管道非常多元,最簡單的方式就是在網路上收集現成的。例如,在 Kaggle Dataset 中保存非常多的資料集,用於訓練機器學習模型。 - 資料探索 (Data Exploration / Data Inspection)
資料探索的目的在於更加了解資料內容。了解資料集中每一個屬性的類型,如果是字串類型則必須轉化為數字後,才能輸入模型中。 - 資料清理 (Data Cleaning)
在資料探索的過程中,我們可能會發現某些樣本的數值有缺失。例如,第 043 樣本缺乏「價格」資料、第 103 樣本缺乏「坪數」資料。我們可以透過一些統計的技術來填補這些缺失值,當然也可以直接將此樣本從資料集中刪除。 - 概述統計 (Summary Statistics) 與資料視覺化 (Data Visualization)
完成資料的清理後,我們可以透過許多統計指標,總結資料集的整體屬性,或是透過圖表將資料集中樣本的分布繪製出來。
Step 3 : 模型訓練
建立資料集後,我們可以建立模型,並進行模型的訓練。在開始訓練之前,我們通常會將整個資料集拆分成「訓練資料集」(80%) 與「測試資料集」(20%)。這是為了確保模型在訓練過後,我們還可以利用一些模型沒有看過的資料,評估模型的預測品質。
在定義問題階段中,我們已經確認「房價預測」屬於「回歸」問題。因此,我們當然會選用回歸模型 (Regression Model) 進行訓練。
建立一個 Regression Model 的工具非常多,如果希望以傳統的機器學習技術來建立,則可以使用 scikit-learn;如果希望以深度學習技術來建立,則可以使用 TensorFlow 或是 PyTorch。
Step 4 : 模型評估
模型訓練完成後,我們可以透過「測試資料集」(Testing Dataset) 評估模型的好壞。在使用機器學習解決問題的五步驟 : 模型評估中,我們提到「分類模型」與「回歸模型」分別都有許多評估指標可以使用。
針對回歸模型,常見的評估指標有 MAE (Mean Absolute Error)、MSE (Mean Squared Error) 與 RMSE (Root Mean Squared Error)。
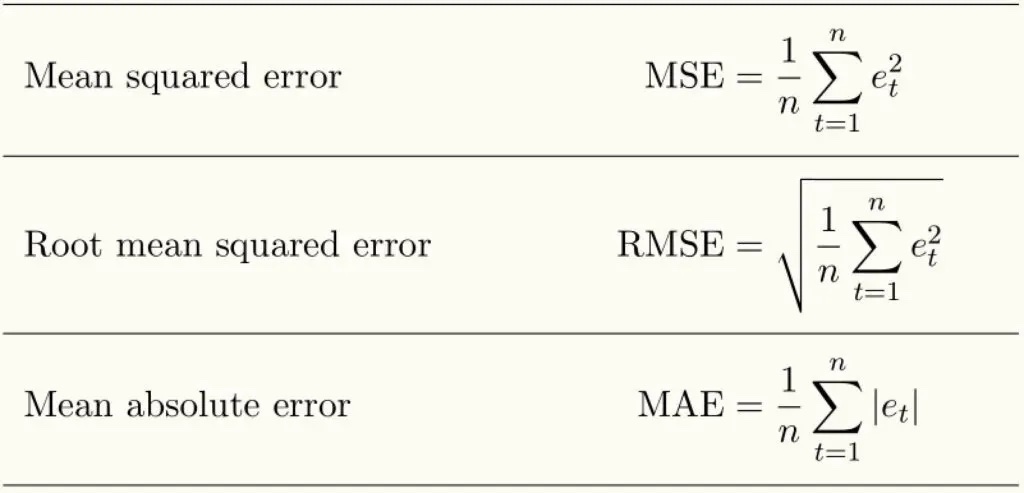
Regression 問題中常見的 Loss Function
在機器學習基礎觀念系列的文章中,我們不會深入探討社學的部分,然而我可以理解不管是 MAE、MSE 或是 RMSE,他們的目的都是要計算模型的「預測值」與實際的「正確數值」差的有多遠。
Step 5 : 模型推論
當模型經過評估確認品質過後,我們可以實際使用模型進行房價的預測。輸入模型在訓練階段沒有見過的樣本,並得到模型輸出的預測值。
結語
在本篇文章中,我們透過「房價預測」的例子,再一次複習了機器學習五步驟,了解每一個步驟在實際解決問題時所扮演的角色。在下一篇文章中,我們會再利用機器學習五步驟,解決生活中「非監督式學習」的例子。