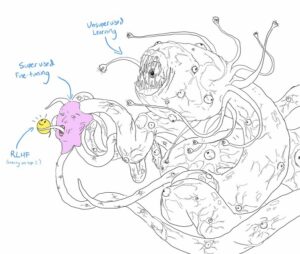
LLM Fine-Tuning: Reinforcement Learning from Human Feedback 理解 ChatGPT 的關鍵訓練階段:RLHF Feb 27.20 min read.深度學習核心觀念