LLM Fine-Tuning: Reinforcement Learning from Human Feedback
source: twitter.com/anthrupad
前言
2023 可說是 Generative AI 的元年,尤其是大型語言模型 (Large Language Model, LLM) 更是開始融入大家的日常生活中。本篇文章簡介 LLM 的訓練過程,尤其針對第三階段 Reinforcement Learning from Human Feedback (RLHF) 這個部分。
小提醒:本篇文章中會有比較多看起來很專業但其實沒什麼的名詞,因此可能比較適合對於 LLM 有基礎概念的讀者!
LLM 訓練的 3 個階段
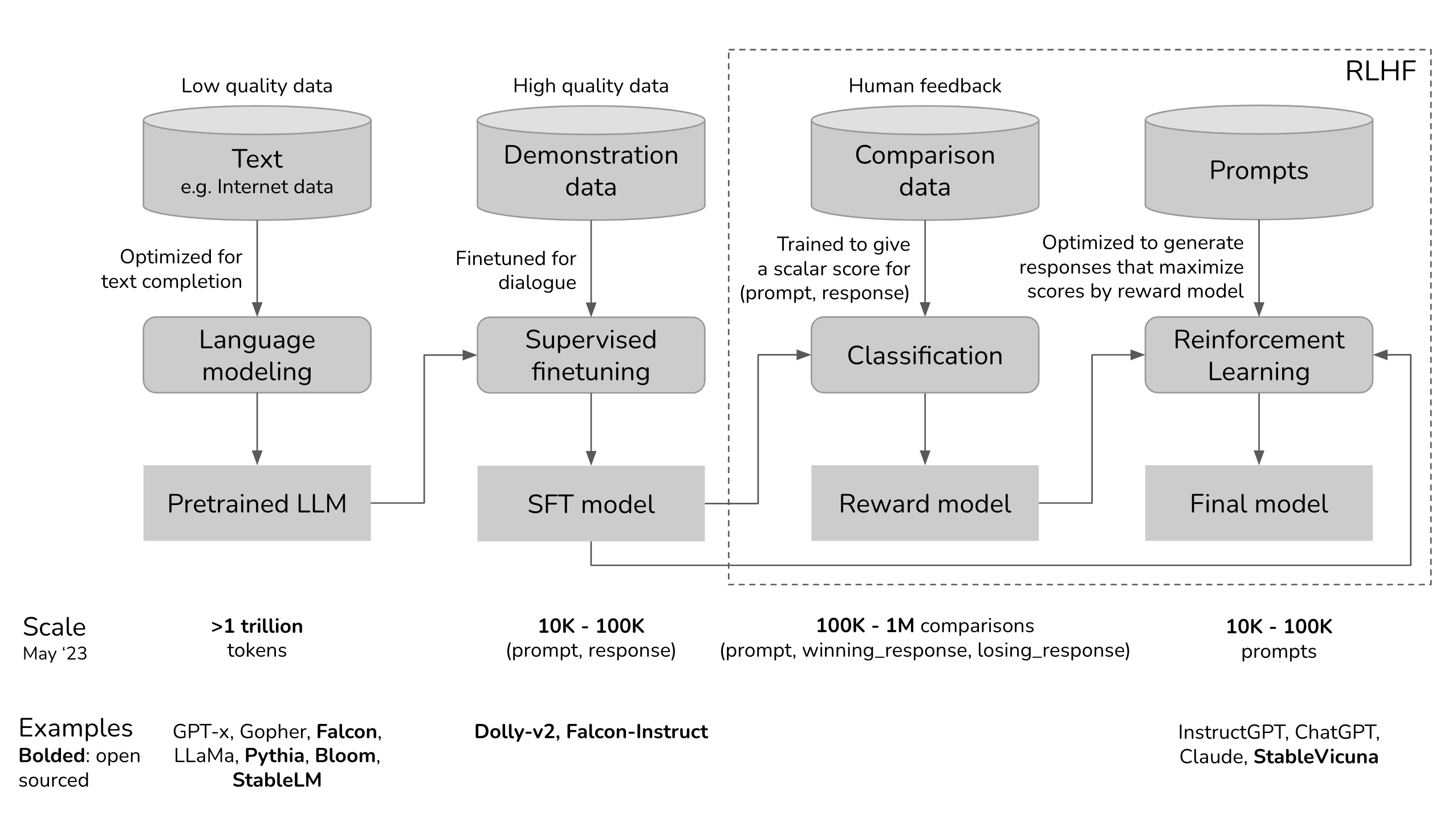
(Chat-Based) LLM 訓練的三個步驟:Self-Supervised Pre-Training、Supervised Fine-Tuning 與 Reinforcement Learning from Human Feedback [source: https://huyenchip.com/2023/05/02/rlhf.html]
如上圖所示,一個 Chat-Based LLM 的完整訓練流程通常會經過以上 3 個步驟:Self-Supervised Pre-Training、Supervised Fine-Tuning 與 Reinforcement Learning from Human Feedback。在每一個階段中都有一些需要特別留意的名詞:
- 第一階段 (Self-Supervised Pre-Training):Pre-trained LLM
- 第二階段 (Supervised Fine-Tuning):SFT LLM
- 第三階段 (Reinforcement Learning from Human Feedback):Reward Model 與 Final Model
第一階段訓練:Self-Supervised Pre-Training
第一階段的訓練是 Self-Supervised Pre-Training,目的在於透過大量的 Unlabeled Data(通常是散播在網路上的這些文字)來訓練 LLM。訓練方式通常有兩種,一種稱為 Masked Language Modeling (MLM),另一種稱為 Causal Language Modeling (CLM)。
MLM 任務其實就是「填空題」,我們會將一段句子中的某些 Token 遮蓋 (Mask) 掉,然後把這個句子輸入到 LLM 中,讓他去預測這些被遮蓋掉的 Token 是什麼。在 MLM 的過程中,LLM 將會學習理解句子中其他沒有被遮蓋的 Token 的意義,來預測被遮蓋掉的 Token。另一方面,CLM 任務其實是「文字接龍」,我們給 LLM 看一段句子中的前 N 個 Token,然後希望他去預測第 N+1 個 Token。在這過程中,LLM 將會學習前 N 個 Token 的意義,然後預測第 N+1 個 Token 應該是什麼比較適合。
在上圖的 Self-Supervised Pre-Training 中,其實就是讓 LLM 透過大量的文本資料學習「文字接龍」(CLM),經過第一階段訓練後的模型我們稱為 Pre-trained LLM。
第二階段訓練:Supervised Fine-Tuning
第二階段的訓練是 Supervised Fine-Tuning,既然是「Supervised」就可以知道這個階段的訓練需要用到「標籤」。在這個階段所使用的資料集,通常稱為 Instruction-Following Data 或是 Demonstration Data,格式通常為 [Prompt, Response]。我們輸入 Prompt 到 LLM 中,訓練 LLM 輸出 Response。有些時候,這些 [Prompt, Response] 的訓練資料並沒有辦法單純從網路上爬取,就需要聘請人類來做標記,因此資料集的成本相對第一階段來得更高。
為什麼 Pre-trained LLM 需要 Supervised Fine-Tune 在這些 [Prompt, Response] 的資料上呢?
主要是因為 Pre-trained LLM 是一個「文字接龍」大師,給定一個 Prompt,它的回答可以有非常多種可能,因為以文字接龍的角度,這些 Response 都可以接在我們所給定的 Prompt 後面。舉例來說,假設我們給 Pre-trained LLM 看的 Prompt 是「如何製作一塊披薩」,它的 Response 可能是「for 生日宴會」、「以及一份蛋糕」或是「第一步:你需要…」。
我們可以清楚地發現第三種回答方式才是我們「Prefer」的!因此,在這個階段的訓練中,我們就是透過很多 [Prompt, Response] 的資料,來告訴 Pre-trained LLM 在這種 Prompt 底下,我們會比較「Prefer」什麼樣的 Response。
這邊特別強調「Prefer」是因為在這個階段以及下一個階段 (Reinforcement Learning from Human Feedback) 的初衷都比較像是 Preference Learning,訓練 LLM 輸出一個人類 Preferred 的 Response,而不是要讓它學習新的 Knowledge(可以想成 LLM 該有的 Knowledge 在 Pre-training 階段已經學到了)。
經過這個階段訓練過後的 LLM,我們通常稱其為 SFT LLM。
第三階段訓練:Reinforcement Learning from Human Feedback
第三階段的訓練是 Reinforcement Learning from Human Feedback 簡稱 RLHF。
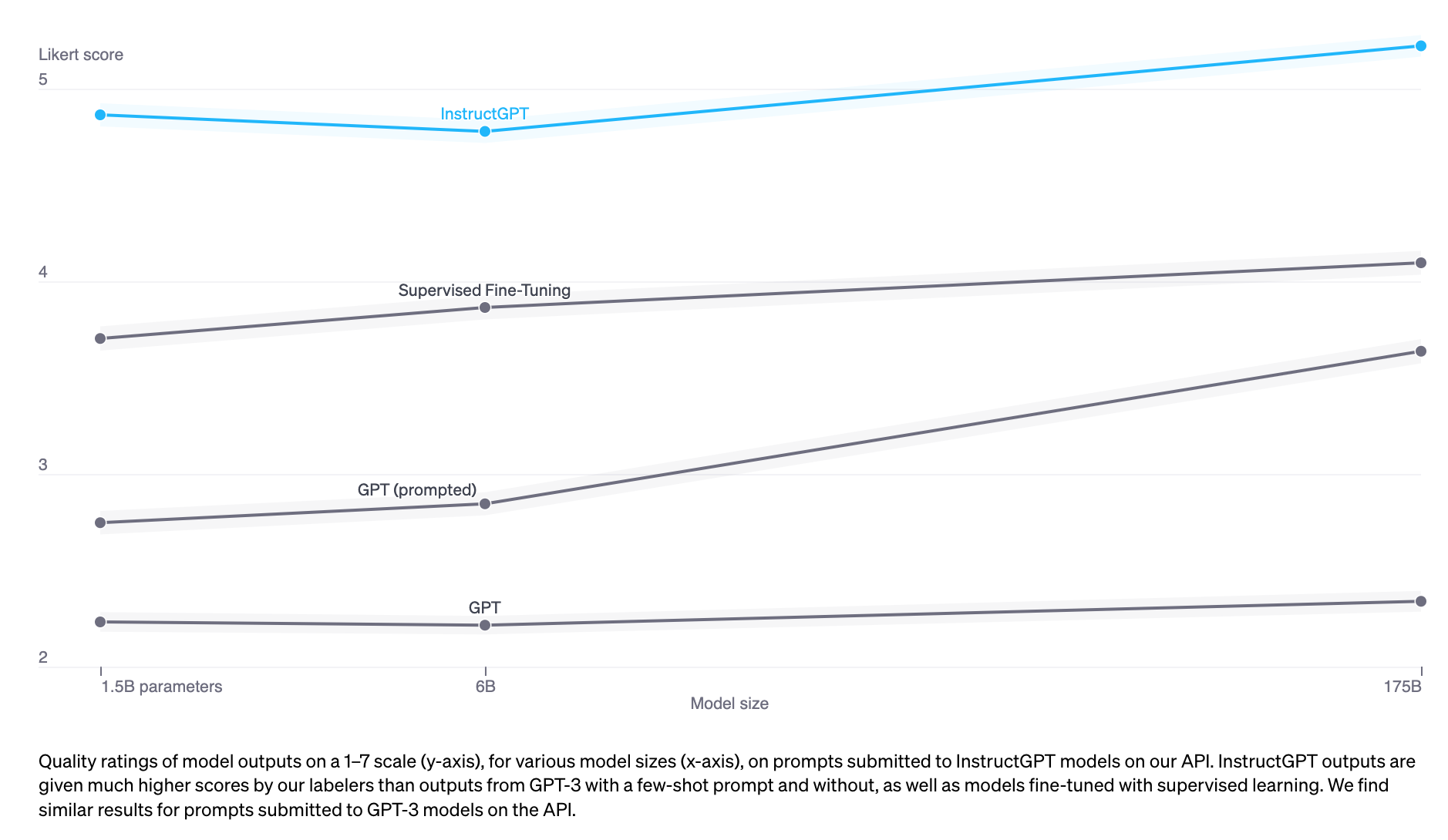
InstructGPT (SFT+RLHF) 的表現勝過 SFT Model [source: https://arxiv.org/abs/2204.05862]
由上圖可以發現,若單從實驗結果來說的話,有經過的 RLHF 訓練的模型 (InstructGPT) 會比只有經過 Supervised Fine-Tuning 或 Self-Supervised Pre-training 的模型有更好的表現。
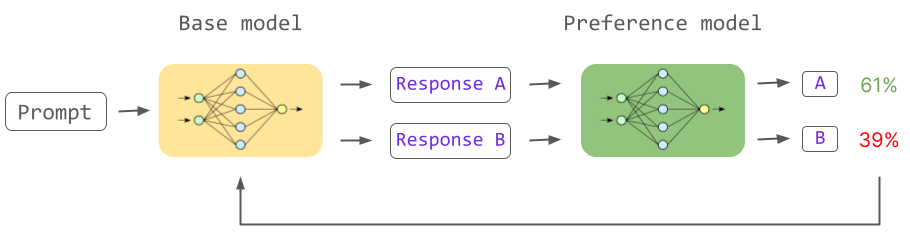
RLHF 概念 [source: assemblyai]
上圖呈現的是用 RLHF 來訓練 LLM 的示意圖:Base Model 就是經過第二階段訓練得到的 SFT LLM,而 Preference Model 就是 Reward Model。給予 SFT LLM 一個 Prompt,透過 Sampling 的方式得到多個不同的 Response。將這些 Response 輸入到 Reward Model,來為每一個 Response 評分(給予每一個 Response 一個 Reward)。 在 RLHF 中,我們希望透過 RL 演算法 (例如:Proximal Policy Optimization, PPO) 訓練 SFT Model 最大化其所獲得的 Reward。
你可以發現,在這個過程中 Reward Model 可以說是扮演著一個非常重要的角色,因為他會替 SFT LLM 的 Response 進行評分,而 SFT LLM 又會根據這些評分來更新自己,讓自己能夠得到最好的分數。換句話說,如果 Reward Model 品質不好,那可以想像最後訓練出來的 LLM 勢必也會很糟。
所以說,Reward Model 是怎麼訓練的呢?我們首先釐清 Reward Model 的 Input、Output 與 Objective:
- Input:一段文字(Prompt 和 Response 組成)
- Output:一個數字(給予 LLM 的 Reward,就是這個 Response 的評分)
- Objective:愈好的(Human Preferred) Response 就要給予愈大的 Reward;相反的,愈差的(Human Dispreferred) Response 就要給予愈小的 Reward
為了訓練出這樣的 Reward Model,我們需要建立一個 Preference Dataset:

Preference Dataset 範例 [source: huyenchip.com/2023/05/02/rlhf.html]
上圖呈現的 Preference Dataset 中的一個樣本:根據一個 Prompt,我們會準備一個好的(Human Preferred 的) Response(winning_response)與差的(Human Dispreferred 的) Response(losing_response)。我們會對 Reward Model 進行兩次輸入:第一次輸入是 Prompt 與 winning_response 組成的文字,而我們得到一個 Reward (winning_reward);第二次輸入是 Prompt 與 losing_response 組成的文字,而我們得到另一個 Reward (losing_reward)。我們希望 Reward Model 輸出的 winning_reward 愈大愈好,而 losing_reward 愈小愈好!具體來說,就是希望 Minimize 以下這個 Loss Function:
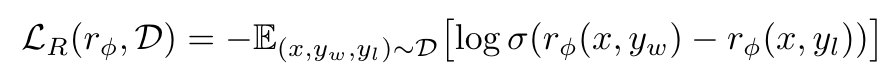
Reward Model 的 Loss Function [source: https://arxiv.org/abs/2305.18290]
因為最前面有一個負號的關係,當 Reward Model 在 Minimize 這個 Loss Function 時,其實就是在 Maximize Sigmoid Function 中 winning_reward 與 losing_reward 的差值,進而讓 winning_reward 更大、讓 losing_reward 更小。
最後,因為 Reward Model 的品質相當重要,我們必須確保他至少有和 SFT LLM 一樣對文字的理解能力,因此通常會把原來的 SFT LLM 複製一份作為 Reward Model 的初始參數。
到這裡,相信你已經大致上明白 Reward Model 所扮演的角色以及他是如何被訓練出來的!有了 Reward Model,我們才可以對 SFT LLM 進行 RLHF 的訓練。在 RLHF 的訓練中,我們希望解決以下最佳化的問題:
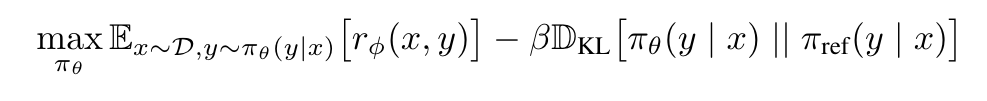
RLHF 中的最佳化問題 [source: https://arxiv.org/abs/2305.18290]
從這個數學式子中,我們可以知道這個最佳化問題是希望找到一組 LLM 的參數(PI_theta),給定一個從 Dataset(D)抽樣出來的 Prompt(x),LLM(PI_theta)會輸出一個 Response(y):
- 第一項:而這組 [Prompt(x), Response(y)] 能夠讓 Reward Model 的輸出(r(x, y))愈大愈好
- 第二項:此外,這個 LLM 的參數(PI_theta)還要與 Reference LLM(PI_ref)的 KL Divergence 愈小愈好
第一項應該沒什麼問題,就是最大化所獲得的 Reward,然而第二項是什麼意思呢?實際上,第二項的 KL Divergence 在 RLHF 這個階段扮演很重要的功能!透過 KL Divergence,計算正在被訓練的 LLM 的參數(PI_theta)與 Reference LLM 的參數(PI_ref)的距離,而在 KL Divergence 前面加上一個負號,就是希望 PI_theta 與 PI_ref 的距離不能差得太遠。所謂的 Reference LLM(PI_ref)其實就是經過第二階段 Supervised Fine-Tuning 後得到的 SFT LLM。
換句話說,KL Divergence 的引入正是為了避免 LLM(PI_theta)為了 Maximize Reward 而去學到 Reward Hacking 的技巧(例如:固定輸出某一種模式的 Response 都可以讓 Reward Model 輸出較大的 Reward,而沒有真的了解 Human Preferred 的 Response 是什麼),使得參數(PI_theta)不斷地被大幅度更新,而和原來的參數(PI_ref)有了太大的差異。
Reinforcement Learning from Human Feedback 為什麼能夠提升 Supervised Fine-tuned LLM 的表現?
為什麼 RLHF 能夠讓 LLM 有更好的表現?目前可能還沒有一個理論上的證明,但是從一個比較直觀的角度來解釋的話,你可以發現第三階段的 RLHF 和第二階段的 SFT 有一個很大的差異:
- SFT:透過 Demonstration Data 告訴 LLM,看到目前這個 Prompt,輸出這個 Response 「才是正確」
- RLHF:透過 Reward Model 告訴 LLM,看到目前這個 Prompt,輸出這個 Response「有多正確」
此外,在 RLHF 中,LLM 還會有機會輸出比較差的 Response,然後透過 Reward Model 得到比較差的 Reward,告訴 LLM 這個 Response 有多差。藉此,讓 LLM 有機會去學習什麼樣的 Response 是好的什麼樣是不好的。
最後,再補充說明 RLHF 中的 HF (Human Feedback),正是用來表示 LLM 所得到的 Feedback 也就是 Reward 其實是來自 Human 的!因為訓練 Reward Model 的 Preference Dataset,正是根據 Human 的 Preference 而建立的。