[論文介紹] DPO:Direct Preference Optimization

DPO: Direct Preference Optimization
前言
在 LLM Fine-Tuning: Reinforcement Learning from Human Feedback 一文中,我們介紹了大型語言模型 (Large Language Model, LLM) 訓練的三個步驟:Self-Supervised Pre-Training、Supervised Fine-Tuning 和 Reinforcement Learning from Human Feedback (RLHF)。本篇文章所要分享的論文 DPO (Direct Preference Optimization) 是一篇被收錄於 NeurIPS 2023 的論文,主要針對第三階段 RLHF 的訓練流程進行改善,提出一個更有效率的訓練方法。
小提醒:在閱讀本篇文章之前,請先務必完全了解 RLHF 的概念!
為什麼需要 RLHF?
在說明 RLHF 的問題之前,我們先複習一下,為什麼 LLM 的訓練還需要經過 RLHF 呢?
主要是因為 LLM 經過 Self-Supervised Pre-Training 之後,他成為了一個名副其實的「接龍大師」,給定一個 Prompt 它的輸出會有千千萬萬種。當我們問 LLM 一個問題時,即使他知道所有可能的答案,他也不知道人類 Prefer 的是哪一種。換句話說,根據不同的情境我們會希望 LLM 輸出其中一種滿足人類偏好 (Preference) 的答案,因此我們會需要對 Pre-trained LLM 進行 Preference Learning!
目前主流的 LLM Preference Learning 主要是第二階段的 Supervised Fine-Tuning 再加上第三階段的 RLHF,然而 RLHF 訓練的複雜性與不穩定性,使得一般人很難有效率的對 LLM 進行 RLHF 訓練。因此,本篇論文主要是針對 RLHF 訓練階段的問題,提出一種新的訓練方法「DPO」。
RLHF 有什麼問題?
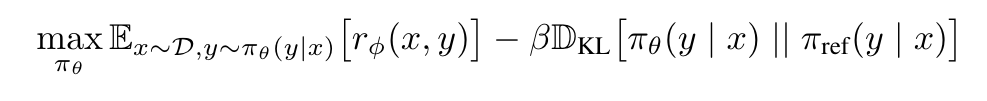
RLHF 中的最佳化問題
接著,我們來聊聊 RLHF 訓練階段中的問題。上圖呈現的是 RLHF 階段,需要處理的最佳化問題。在這個階段其實就是要訓練 LLM「最大化 Reward」且同時受到「KL Divergence 的限制」。可以發現兩個問題:
- 我需要透過事先收集好的 Preference Dataset 訓練一個 Reward Model
- 我們需要透過 RL 演算法(例如:Proximal Policy Optimization, PPO)讓 LLM 透過最大化 Reward 的過程來學習正確的輸出
DPO:Direct Preference Optimization
在 DPO 的方法中其實就是試圖解決上述兩個問題:
- 我們可不可以省去建立 Reward Model 的步驟,直接利用 Preference Dataset 訓練 LLM,讓訓練過程更有效率?
- 我們可不可以使用 Supervised Learning 方法而非 Reinforcement Learning,來降低模型訓練過程的不穩定性?
而提出了一個新的 Loss Function:
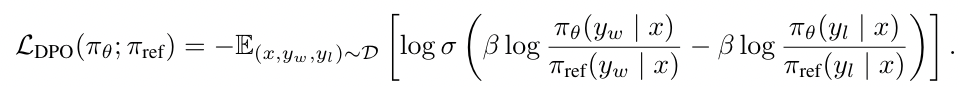
DPO Loss Function
從 DPO Loss Function 可以發現,給定一個 Preference Dataset 並抽樣出一個 Sample 包含 Prompt (x)、Winning Response (y_w) 與 Losing Response (y_l);基於 Prompt (x),模型 (PI_Theta) 必須學習讓 Winning Response (y_w) 出現的機率愈高,並讓 Losing Response (y_l) 出現的機率愈小。這個過程其實就相當於在原來的 RLHF 中,模型要學習輸出 Winning Response 來得到比較大的 Reward(避免輸出 Losing Response 因為得到的 Reward 也會比較小)。
此外,你還可以看到減號的前項與後項都分別除以參考模型 (PI_Ref) 生成相對應的 Response 的機率,這呼應了原來的 RLHF 中的 KL-Divergence 限制(不希望模型(PI_Theta)在學習的過程中,和原來的自己(PI_Ref)差異太大)。
最後,也可以發現在 DPO 的訓練過程,模型做的是 Supervised Learning 而非 Reinforcement Learning,也不需要 Reward Model 的輔助,這不僅能夠提升模型訓練時的穩定性,也能夠降低訓練過程所需要的算力。
在 DPO 的原始論文中,作者有清楚的說明如何從原來的 RLHF 最佳化過程推導出 DPO 的最佳化方式,有興趣的讀者務必讀一讀這篇論文。此外,從論文的實驗上以及 Hugging Face 中都可以看到 DPO 方法的有效性,這邊也就不再贅述。
結語
在本篇文章中,我們簡單介紹了 DPO:Direct Preference Optimization 的概念,說明他如何兼顧 RLHF 的優勢,並且改善了 RLHF 訓練的不穩定性與低效率的問題。理解了 DPO 後,不知道你心中有沒有這樣的疑問:雖然 DPO 不用建立 Reward Model,也可以透過 Supervised Learning 方式來直接優化模型,但是仍然需事先建立 Preference Dataset。我們都知道 RLHF 中用來訓練 Reward Model 的 Preference Dataset 是需要投入很多人力與時間來建立的高成本資料集,我們有沒有可能進一步改善 DPO,避免 Preference Dataset 的建立呢?
是的!在 2024 年 1 月份,就有許多論文(Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models、Self-Rewarding Language Models)被上傳到 Arxiv 上,正是希望透過一些技巧避免 Preference Dataset 的建立。