[論文介紹] Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM

source: Pixabay
前言
今天要和大家分享一篇觀念簡單又有趣的論文 —— Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM!這篇論文是由 Meta FAIR 於 2024 年 3 月發表的論文。也是繼 Sparse Upcycling 後,第二篇和大家分享的 Mixture of Expert (MoE) 論文。Branch-Train-MiX 簡稱 BTX,之所以想分享這篇論文的原因,除了它使用了當今熱門的 MoE 技術外,它還展示了如何將多個不同領域的專家(Domain Expert)整合在一起,覺得相當有趣!
本篇論文的觀念也簡單好理解,讀起來沒什麼負擔~就用茶餘飯後的 10 分鐘來學習一個新知識吧!
Branch-Train-MiX 想解決什麼問題
想快速理解一篇論文的概念,我們一定先從它想要解決的「問題」開始理解!簡單來說,Branch-Train-MiX 想解決 Large Language Model (LLM) 在「分散式訓練」的過程中所帶來的問題。
為了加速模型的訓練,掌握很多 GPU 的企業(EX. Meta)就會透過分散式訓練(Distributed Training)來增加模型訓練時的 Throughput 進而減少訓練所需要的時間。分散式訓練主要又分為兩種方法:Data Parallelism 與 Model Parallelism。下圖呈現的是 Data Parallelism 的方法,可以發現主要是把同一個模型複製到多個 Node(配有 GPU 的裝置)上,然後將所有的訓練資料集切分為多個 Subset 分別放到每一個 Node 上。
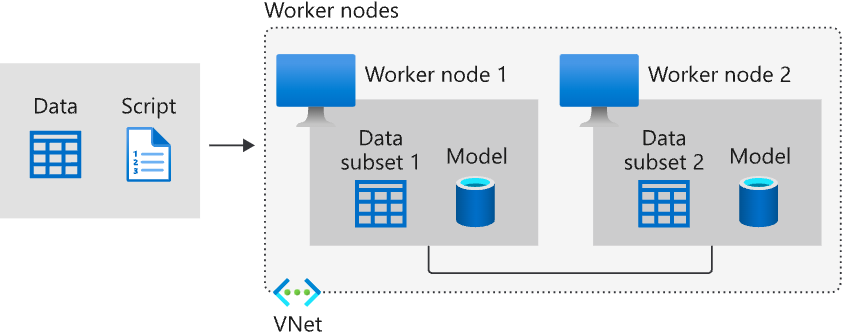
分散式訓練示意圖 [source: https://learn.microsoft.com/en-us/azure/machine-learning/concept-distributed-training?view=azureml-api-2#data-parallelism]
通常在進行分散式訓練時,每一個模型透過不同的 Batch 的訓練資料得到不同的 Gradient。這些 Gradient 就需要以某種方式 Aggregate 在一起(EX. 取平均),然後用這一個 Gradient 更新模型參數,再將更新後的模型參數分配到所有的 Node 上。
你發現了嗎!!!分散式訓練會有一個大問題:雖然模型在不同的 Node 上被訓練,但是這些 Node 經常需要「同步」以及「溝通」,Node 之間頻繁的同步與溝通(EX. 傳遞新更新好的參數)就會導致效能的瓶頸(Bottleneck):我們即使用更多的 GPU 也沒辦法再顯著的提升訓練速度。此外,假使有一顆 GPU 突然故障,也會導致整個 Training 受到影響。
如果不想要 Node 之間的頻繁的同步,那就要讓 Node 分別訓練自己的模型,最後再將多個不同的模型想辦法合併在一起。
過去就有論文提出 Branch-Train-Merge (BTM) 方法:就是在訓練階段,把多個 LLM (複製自同一個 Seed LLM) 放在不同的 GPU 上訓練,每個 LLM 只會看到自己訓練資料 Subset,這樣訓練出來的 LLM 就會是一個 Domain Expert。在推論階段時,再用 Router 決定目前的 Input 要由哪些 Expert 處理,然後把這些 Expert 的 Output Distribution 合併起來,進行 Next Token Prediction。但是 Branch-Train-Merge 雖然讓多個 GPU 的訓練可以「非同步」進行,但是訓練完的東西卻是「多個模型」。這樣會導致我們沒辦法再進行後續的訓練(例如:SFT 或 RLHF)。
因此,Meta 所提出的 Branch-Train-MiX 就是希望可以讓模型在多個 GPU 上「非同步」、「獨立」的訓練,但是最後又只會得到一個模型而非多個模型!
Branch-Train-MiX 方法介紹:Branch ⭢ Train ⭢ MiX
Branch-Train-MiX (BTX) 這個方法就如同它的名稱所示,主要可以分為三個階段:
- Branch:將一個模型 (Seed LLM) 複製多份分別放到不同的 Node 上。每一個 Node 也會有自己特定領域的訓練資料集
- Train:每一個 Node 獨立訓練自己的 LLM
- MiX:透過 Weight Average 與 Mixture-of-Expert 的概念將所有 LLM 整合在一起
具體來說,BTX 的第一步與第二步(Branch-Train)就是把 Seed LLM 複製 N 個然後分別訓練在 N 個 Domain Dataset 上。因為這 N 個 LLM 完全不相關,因此可以做到完全的平行化訓練:GPU 之間沒有同步問題,且一個 GPU 故障也不會影響到其他的 GPU。每個 LLM 會 Specialize 在自己的 Domain 上成為 Domain Expert。
BTX 的第三步(MiX)就是會把所有 Domain Expert 的 FFN 合併成一個 MoE Layer(如下圖右下角所示)。例如,所有 Domain Expert 的第 k 層 FFN,合併成一個第 k 層 MoE Layer。至於其他 Layer (EX. Self-Attention, Embedding),就透過 Weight Average 的方式整合多個 Domain Expert(如下圖右上角所示)。作者的想法是他認為 FFN 是比較 Domain-Specialized 的 Layer,為了保留每一個 Expert 的 Domain Knowledge,透過 MoE Layer 保留每一個 FFN。至於其他 Layer,作者則認為比較沒有那麼 Domain-Specialized,因此就直接將他們的參數取平均。
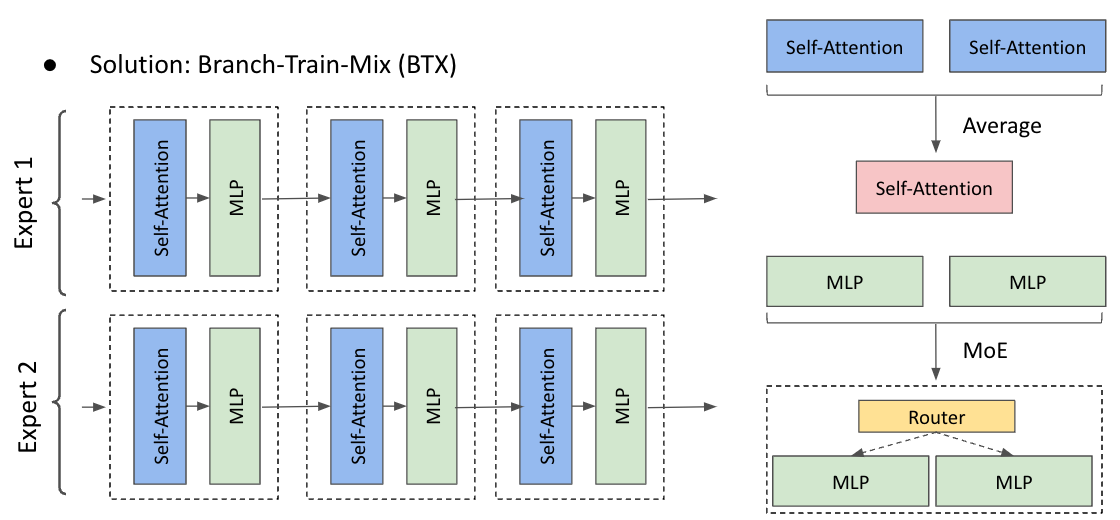
多個 Domain Expert 的合併方式
MoE Layer 中的 Router 是使用 Token Choice Routing。Token Choice Routing 就必須處理 Expert Load Balancing 問題,避免 Token 都傾向選擇某些特定的 Expert。針對 Expert Load Balancing 問題最常見的作法就是替每一個 Router 都加上一個 Auxiliary Loss:
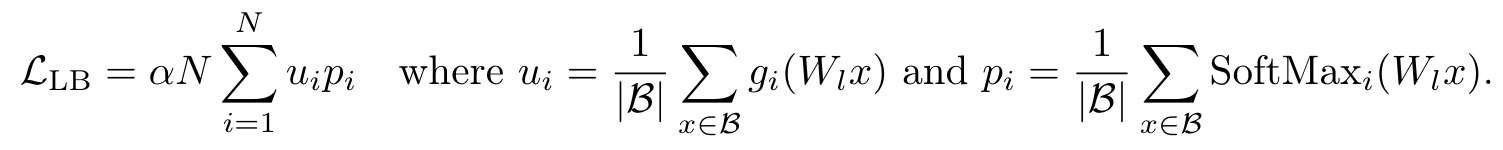
Auxiliary Loss for Load balancing Problem
從上圖可以發現,Auxiliary Loss 其實就是這一個 MoE Layer 中每一個 Expert 的 u 與 p 乘積的總和。其中 u 就是一個 Batch 中,這個 Expert 被Router 選到的「平均次數」;而 p 就是一個 Batch 中,這個 Expert 被 Router 選到的「平均機率」。
Load Balancing Loss 會和 Language Modeling Loss 加總在一起變成 Total Loss 來更新整個模型。
實驗結果
實驗中,作者使用 Llama-2 7B 作為 Seed Model,並複製出 3 個 LLM 分別訓練在 Math、Code 和 Wikipedia 的資料集。
最後進行 Mix 時,作者把 3 個 Domain Expert 和原來的 Seed Model Mix 在一起,所以最後的模型中的每一個 MoE Layer 中會有 4 個 Expert。最後再把所有 Domain 的訓練資料集合在一起訓練這一個模型。
有趣的是,我們之前介紹過的 Google 發表的 Sparse Upcycling 方法,其實就是 BTX 的特殊情況,就是沒有經過 BT (Branch-Train) 只有經過 X (Mix) 的版本。
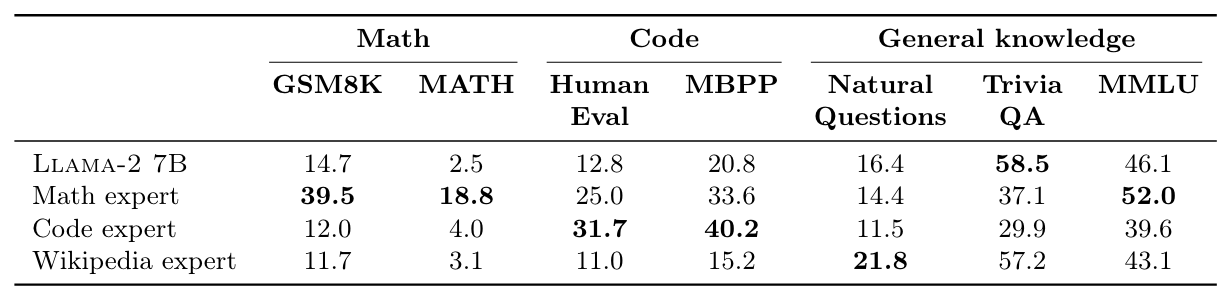
Branch-Train-MiX 實驗結果 (Table 1)
從上表(Table 1)中可以發現 BTX 中的每一個 Expert 基本上在自己的 Domain 都會有不錯的表現!但是也可以發現到一個有趣的現象:將一個具有 General Knowledge 的 LLM (Llama-2 7B) 訓練在 Domain Knowledge 上會出現「災難性遺忘」( Catastrophic Forgetting)的問題,也就是說 Math 和 Code Expert 在 General Knowledge 的表現都比原來的 Llama 更差。
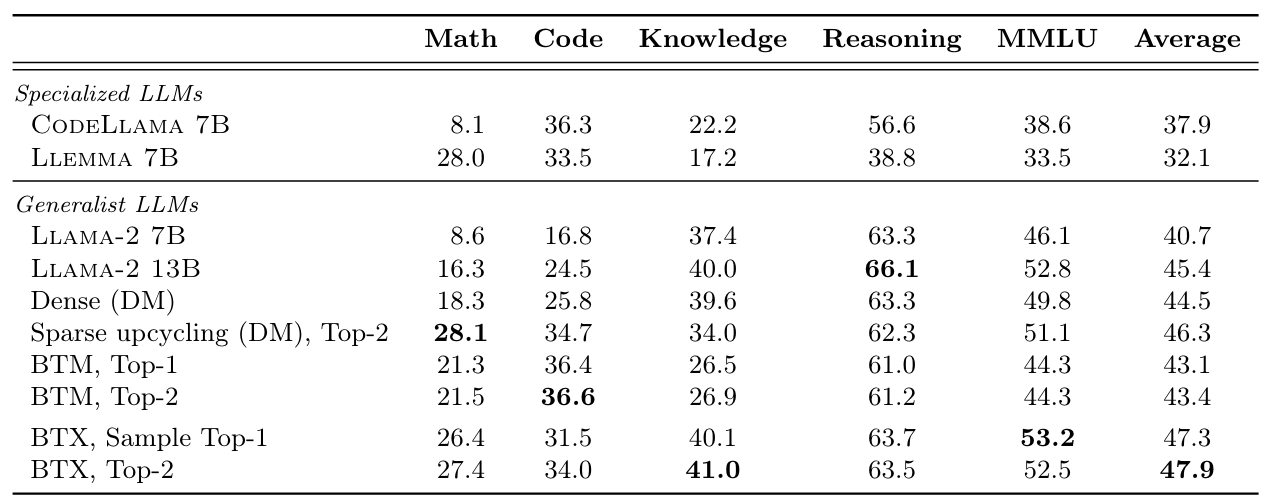
Branch-Train-MiX 實驗結果 (Table 2)
由最後的實驗數據中(Table 2)可以看到 BTX (最下面兩排)相較於原來的 Seed Model (Llama-2 7B) 不僅在 Domain Knowledge(Math 與 Code)上做得更好,原本的能力 (Knowledge, Reasoning, MMLU) 也沒有忘記!由此可以發現 Branch-Train-MiX 除了避免分散式訓練時 GPU 之間不斷同步所帶來的效能瓶頸外,可能還有另外一個使用情境:當我們有一個已經經過預訓練的 LLM,這個 LLM 對於每一個 Domain 都有一些 General Knowledge,但是都不精深。我們希望這個 LLM 可以在 N 個 Domain 上有更好的表現,就可以透過 Branch-Train-MiX 的訓練方法。
結語
在本篇文章中,我們介紹了 Meta FAIR 所發表的 Branch-Train-MiX 論文,Branch-Train-MiX 將一個 LLM 複製到多個 GPU 上獨立訓練在自己的領域的訓練資料集上,避免了分散式訓練時 GPU 之間頻繁的同步與溝通所帶來的效能瓶頸。此外,Branch-Train-MiX 最後透過 Sparse MoE 的技巧將多個 Domain Expert 整合成一個模型,讓這個單一模型可以再進行後續的訓練(EX. SFT 或 RLHF)進一步提升表現。從最後的實驗中也可以看到 Branch-Train-MiX 所訓練出來的模型也能夠避免 Catastrophic Forgetting 的問題。