Stochastic Gradient Descent 介紹

source: Pixabay
前言
在前一篇文章中,我們介紹到 Gradient Descent 的觀念,理解如何透過 Gradient Descent 更新參數 v 使得 Cost Function C(v1, v2, v3, …) 的數值不斷的下降。透過計算 Cost Function 的 Gradient 我們掌握了參數的「更新方向」,設定 Learning Rate 則是讓我們決定參數的「更新大小」。
然而,實際應用 Gradient Descent 在 Neural Network 參數的更新上卻有許多缺點,因此出現了 Gradient Descent 的改良版 —— Stochastic Gradient Descent。在本文中,我們將介紹什麼是 Stochastic Gradient Descent,與原來的 Gradient Descent 又有什麼不同。
利用 Gradient Descent 更新 Neural Network 中的參數
在開始介紹 Stochastic Gradient Descent 之前,讓我們再複習一下 Gradient Descent 的概念,了解 Gradient Descent 如何更新 Neural Network 中的參數。在 Deep Learning 基本功:認識 MNIST 資料集與損失函數一文中,我們介紹了 Cost Function 的目的就是要評估目前 Neural Network 中參數(包含 Weight 與 Bias)的好壞:
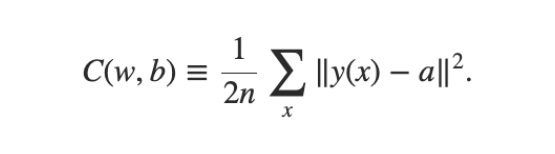
利用 Cost Function 評估 Neural Network 中參數的好壞
在介紹 Gradient Descent 一文中,我們了解如何更新參數 v 來使 Cost Function 數值下降。在這裡,我們只需要依樣畫葫蘆,將 v 換成 Neural Network 中的參數:Weight 與 Bias:
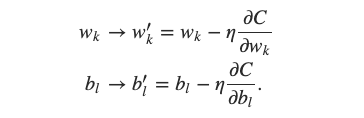
依樣畫葫蘆,更新 Neural Network 中的 weight 與 bias
利用這個規則更新 Weight 與 Bias,使得 Cost Function 的數值愈來愈小。
Gradient Descent 的缺點
即使 Gradient Descent 都已經那麼棒了,它還是存在一些缺點。我們先來看看上方提到 Cost Function,其形式為 C = (1/n) × ∑x Cx。其中 Cx 表示模型針對一筆訓練資料所計算出來的 Cost(也就是模型的這一筆輸出與正確答案的誤差),我們會將每一個訓練資料的 Cost 加總再除以訓練資料的數目,得到平均每一筆訓練資料的 Cost。
在利用 Gradient Descent 更新模型中的參數時,我們一樣會利用一筆訓練資料的 Cost 計算出一個 Gradient(∇Cx),再將所有訓練資料的 Gradient 加總後再除以訓練資料的數量,得到平均每一筆訓練資料的 Gradient:∇C = (1/n) × ∑x ∇Cx。
然而,這樣就代表模型必須看過所有的訓練資料後,才能計算出一個 Gradient,才能更新一次參數。使得模型中的參數,久久才能更新一次參數,增加了模型訓練的困難度。
Stochastic Gradient Descent 是什麼
Stochastic Gradient Descent 的出現正是為了加速模型的訓練,讓模型中的參數更新頻率可以更高一些。當我們利用 Stochastic Gradient Descent 更新模型中的參數時,模型不需要看完整個訓練資料集中的所有樣本才計算一次 Gradient(才更新一次參數),而是可以看訓練資料集中「部分樣本」就計算一次 Gradient (就更新一次參數)。
更精確來說,假設訓練資料集中現在有 100 筆資料:在 Gradient Descent 中,模型會看完 100 筆訓練資料後,才計算出一個平均的 Gradient ,但是在 Stochastic Gradient Descent 中,模型可能只會看 10 筆訓練資料,就計算出一個平均的 Gradient,並更新模型中的參數。如此一來,同樣讓模型看了 100 筆訓練資料,利用 Gradient Descent 我們只能更新模型一次,利用 Stochastic Gradient Descent 我們則能夠更新模型十次。
你可能會說一定是 10 筆訓練資料嗎?可不可以 20 筆或是 5 筆就好?
當然可以!在 Stochastic Gradient Descent 中,我們會稱「部分資料」為 Mini-Batch,這個 Mini-Batch 中訓練資料的數量則稱為 Batch Size。Batch Size 和我們介紹 Gradient Descent 一文中所提到的 Learning Rate 都屬於 Hyperparameter,都是需要由我們(人類)手動設定,而沒有辦法像模型中的參數一樣自動更新。
在本文中我們先不討論 Batch Size 應該多大多小,但是我們應該掌握一個原則:我們之所以隨機從訓練資料集中抽取一部份的資(Mini-Batch)是為了讓模型中的參數被更新更多次,加速模型的訓練。然而,如果參數「更新的方向」不正確,即使參數更新再多次,模型也沒辦法收斂(也就是 Cost Function 的數值還是降不下來)。因此,Batch Size 應該要夠大,讓我們可以僅僅用這一個 Mini-Batch 的訓練資料,計算出來的平均 Gradient,可以愈近似整個訓練資料集計算出來的平均 Gradient:
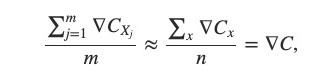
左式為 m 筆訓練資料計算出來的平均 Gradient,右式為所有訓練資料計算出來的平均 Gradient。左式應該愈接近右式愈好
利用 Stochastic Gradient Descent 更新 Neural Network 中的參數
當我們利用 Stochastic Gradient Descent 更新 Neural Network 中的參數時,Weight 與 Bias 的更新方式為:
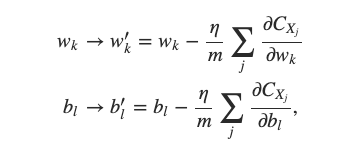
利用 Stochastic Gradient Descent 更新 Neural Network 中的參數
也就是説,我們每一次都會從整個訓練資料集中「隨機」抓出一個 Mini-Batch 的資料,假設 Batch Size 為 m,那就是 m 筆資料。將這 m 筆資料的 Gradient 加總後再除以 m,得到平均的 Gradient。從這個平均的 Gradient,我們知道參數的更新方向,再透過 Learning Rate 調整更新的大小。
完成這一次 Weight 與 Bias 的更新後,我們再從整個訓練資料集中「隨機」抓出另一個 Mini-Batch 的資料,利用同樣的方式更新參數。直到整個訓練資料集中的所有資料都被模型看過後,則表示模型完成了一個 Epoch 的訓練。
結語
在本篇文章中,我們介紹了什麼是 Stochastic Gradient Descent,以及 Mini-Batch、Batch Size 與 Epoch 的概念。當我們利用 Stochastic Gradient Descent 更新模型中的參數時,模型不需要看完整個訓練資料集中的所有樣本才計算一次 Gradient(才更新一次參數),而是可以看訓練資料集中「部分樣本」就計算一次 Gradient (就更新一次參數)。