Deep Learning 基本功:Gradient Descent 介紹

source: Pixabay
前言
在 Deep Learning 原理 : Neural Network 如何分類圖像一文中,我們以「手寫數字圖像」的分類問題為例,站在 Neural Network 的角度感受其如何理解圖像。接著,我們理解 Neural Network 如何透過以下 3 元素:
- 訓練資料集 (Training Dataset)
- 損失函數 (Cost Function)
- 最佳化演算法 (Optimizer)
調整 Neural Network 中的參數 (weight 與 bias) 使得 Neural Network 的輸出愈來愈準確。前兩個元素已在 Deep Learning 基本功:認識 MNIST 資料集與損失函數一文中介紹過,因此本文將介紹第三個元素 —— 最佳化演算法 (Optimizer)。
訓練 Neural Network 的意義
在開始本文之前,我們先好好釐清訓練 Neural Network 的意義是什麼。訓練 Neural Network 的意義無非是希望將 Neural Network 中的參數 (weight 與 bias) 調整好,使得 Neural Network 的輸出愈接近正確答案愈好。
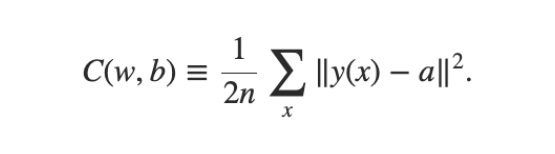
Cost Function
我們會透過 Cost Function 來衡量目前這組參數的好壞。換句話說,訓練 Neural Network 的過程,就是調整 w (weight) 與 b (bias) 使得 C (Cost Function) 的值最小。
簡單來說,訓練 Neural Network ⇒ 調整參數 (w 與 b),使得 Cost Function 變小。
那麼應該如何調整 w 與 b 才能使得 Cost Function 愈來愈小呢?我們會使用一種演算法,稱為 Gradient Descent 來達到這個目標。
理解 Gradient Descent 的概念
為了清楚的理解 Gradient Descent 的概念,我們將問題簡化。我們暫時忘記過去學到的許多名詞,包含 Neural Network、Cost Function 或是 Weight 與 Bias,等等。
目前我們有的就是一個函數 C(v),其中 v = v1, v2, … ,表示 C 這一個函式可以接受任意數量的參數。而我們的目標就是透過 Gradient Descent 演算法去調整每一個 v,使得 C(v) 的值可以愈來愈小。
為了方便視覺化,我們假設 C 可以接受兩個參數 v1 與 v2,即 C(v1, v2)。輸入不同的 v1 與 v2,可以產生不同的數值。如果我們將所有的 (v1, v2) ⇒ C(v1, v2) 的情況都點出來,所有的點可以在 3 維的空間中形成一個面:
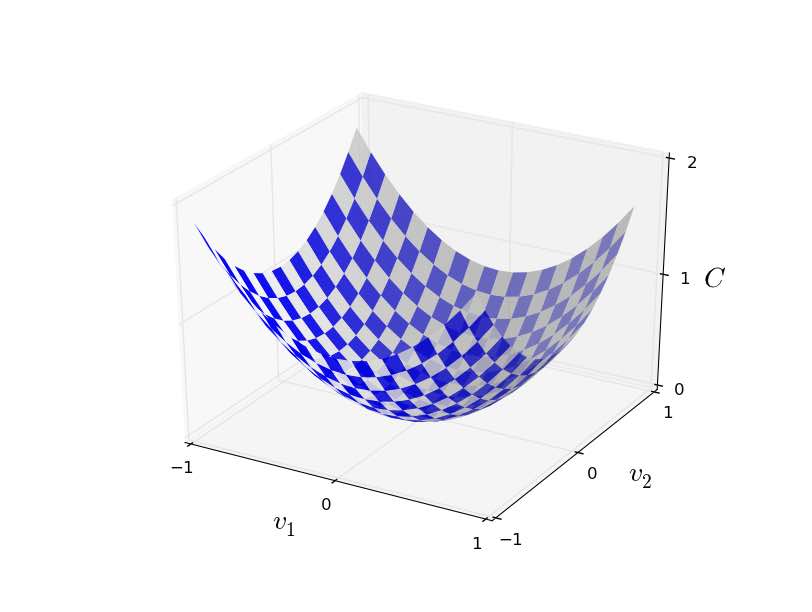
C(v1, v2) 在三維空間中形成的面 [source: Neural Networks and Deep Learning]
如果單從上圖來看,相信你可以很快地找到 C(v) 函數的最小值。然而,通常一個 Neural Network 中所包含的參數都是好幾千萬個參數,勢必不可能那麼簡單就看出最小值的位置。此時,正是 Gradient Descent 的厲害之處!在開始介紹 Gradient Descent 演算法的數學之前,我們先用更貼近我們真實世界的角度,理解 Gradient Descent 如何找到一個函數的最小值。
首先,我們將上圖的 C(v) 函數想成一個「山谷」,我們則是這座山谷上的一顆「球」。可想而知,我們勢必會「沿著山壁」慢慢的向下滾,直到抵達山谷好後才停止。
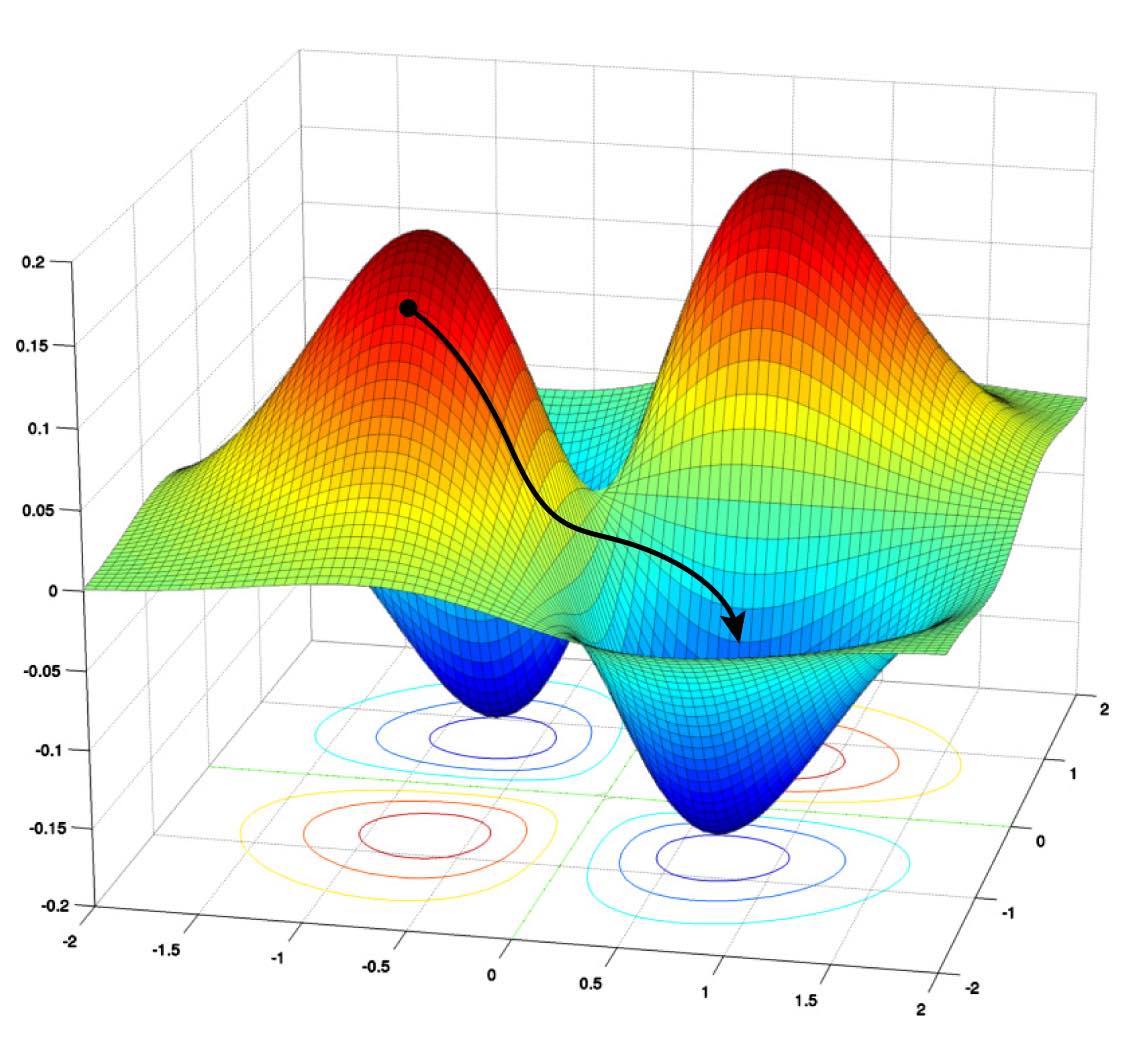
在一座地勢錯綜複雜的山谷上,我們是一顆球 [source: sciencesprings.wordpress.com]
等等!我們再稍微將步調放慢。因為我們現在是一顆停在山壁上的球,又因為這座山谷地勢錯綜複雜(如上圖所示),我們看不到山谷究竟在哪兒,我們只知道我們目前所在區域的地勢變化如何。為了能抵達山谷,我們勢必要朝著「下坡」的方向前進。因此,我們會感受一下四面八方哪一個方向是「下坡」,然後朝著那一個方向前進一步;來到新的位置後,再感受一下四面八方哪一個方向是「下坡」,然後再朝著那一個方向前進一步・・・直到抵達山谷。當我們(是一顆球)抵達山谷之後,會發現四面八方都是「平地」,找不到下坡的方向。
理解 Gradient Descent 的數學
透過「山谷」與「球」的比喻,相信你已經對於 Gradient Descent 的概念有些了解,接著我們加入一些數學元素,理解 Gradient Descent 的數學意義。如果你天生討厭數學也不要擔心,我們不是數學專家,我們不會非常深入的介紹 Gradient Descent 的數學。
C(v1, v2) 在三維空間中形成的面 [source: Neural Networks and Deep Learning]
讓我們再回到前面所提到的 C(v) = C(v1, v2) 函數。套用我們前面的比喻,我們一樣把 C(v1, v2) 函數視為一個山谷,我們則是山谷上面的一顆球,相當於 C(v1, v2) 上的一個點。球的起始位置會落在哪裡,取決於 v1 與 v2 的初始數值。
如同上面所述,因為我們是把自己當成一顆球,所以我們看不到整個山谷的全貌,也就是我們看不到 C(v1, v2) 的最低點在哪裡,只能看到我們所處位置的狀態。假設我們已經決定好要往某一個方向前進(用向量 △v 表示),我們可以想成先朝 v1 前進(用向量 △v1 表示)再朝 v2 前進(用向量 △v2 表示)。
也就是説,△v ≡ ( △v1 , △v2 )T。(T 為 Transpose 的意思)
當我們朝著 △v方向前進後,C(v1, v2) 函數數值的變化量稱為 △C,△C 又可以表示成下方的算式:
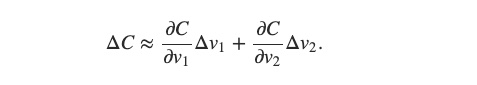
往 △v 前進一步,對 △C 造成的影響
有關偏微分的概念,我們在 Perceptron 的改良版 : 了解什麼是 Sigmoid Neuron 一文中有介紹過,我們可以簡單地將偏微分視為:一個多變數函數對於某一個獨立變數的「改變率」。也就是說,當 v1 加上 5 時 (Δv1 = 5),對 C 的影響不一定是直接加上 5 (ΔC 不一定等於 5),而是需要再乘以 C 對於 v1 的改變率 (當 v1 變動 1 時,C 變動多少)。
基於 ΔC 的算式,我們將偏微分的部分取出來,並給他一個新的符號 ∇C 稱為「Gradient of C」:
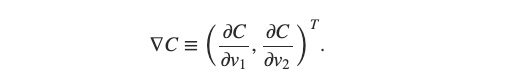
將偏微分部分取出,並給他一個新的定義
第一次看到 ∇ 符號也不需要害怕,我們通常用 ∇ 來表示 Gradient Vector。Gradient Vector 也不是多了不起的東西,就是一個 Vector 裡頭的每一個元素就是偏微分(一個函數對於特定參數的微分)。
有了 △v 與 ∇C,我們可以將原來的 △C 算式改寫為:
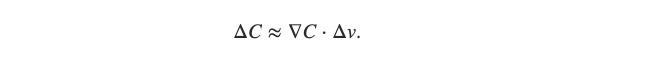
將 △C 改寫
由此算式我們可以更清楚的了解到 △C (C(v1, v2) 函數的變化量)取決於 △v(每一個參數的變動量)與 ∇C(每一個參數變動一單位時對 △C 造成的影響)的相乘。
別忘了!我們現在是一顆球,我們希望移動 △v 後,C(v1, v2) 函數的數值減小,也就是 △C ≤ 0 。我們可以設定 Δv = −η ∇C,在此情況下 ΔC ≈ −η ∇C ⋅ ∇C = −η |∇C|2。又因為 |∇C|2 一定是大於等於 0 的數字,使得 ΔC 一定會小於等於 0。
到目前為止,我們已經知道 Δv = −η ∇C,也就是我們知道每一步應該怎麼移動,來讓 C(v1, v2) 函數值愈來愈小。當我們(是一顆球)現在位於 v 要移動到 v‘:
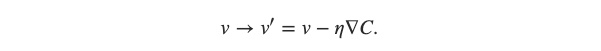
我們知道每一步應該怎麼走
透過這樣的規則,每次要移動一步時,就計算一次 ∇C(Gradient Vector)。每次移動過後 C(v1, v2) 函數值就會變小。就這樣一步一步的前進,直到抵達山谷的最低點,也就是 C(v1, v2) 函數的最小值,這樣的過程就稱為 Gradient Descent。
η (Learning Rate) 是什麼
在上文中,η 這一個符號我們沒有介紹到。η 在機器學習中代表的是 Learning Rate。理解 Learning Rate 的意義之前,我們再回顧 ∇C(Gradient Vector)的概念。
在 ∇C 中,記錄著函數對其參數的偏微分,在 C 函數中只有一個參數 v 的情況下,其實就是在計算切線斜率,我們可以知道每一個參數的「移動方向」。舉例來說,如果現在 C 函數對 v 的偏微分為「負值」,表示切線斜率為「負值」,表示當 v 變大時,C 函數的數值會「減少」;如果現在 C 函數對 v 的偏微分為「正值」,表示切線斜率為「正值」,表示當 v 變大時,C 函數的數值會「增加」。
透過 ∇C 我們可以知道每一個參數的「移動方向」,透過 η (Learning Rate) 則是讓我們決定「移動的大小」。
η (Learning Rate) 在 Deep Learning 中屬於一種超參數 (Hyperparameter),也就是説這一個參數需要我們自己設定自己調整,無法透過 Neural Network 的學習過程自動調整。
我們知道每一步應該怎麼走
設定 Learning Rate 的數值也是一門學問。如上圖所示,如果 Learning Rate 太大可能會使得 v 改變太多,某些情況下會使得 ΔC 大於 0,導致 C 函數數值變得愈來愈大;如果 Learning Rate 太小可能會使得 v 改變太少,就需要花更多時間才能走到 C 函數的最小值。
Gradient Descent:從兩個變數到多個變數
在前面的說明中,我們已經透過兩個變數的 Cost Function C(v1, v2) 說明 Gradient Descent 的概念。實際上,如果你搞懂了上文的所有內容,你也已經可以明白 Gradient Descent 如何應用在 Deep Learning 上。
透過 Gradient Descent 調整 Neural Network 中的參數時,只是將剛剛的兩個變數的 Cost Function 變成多個變數的 Cost Function:C(v1, v2, v3, v4, …)。當我們移動 △v 後,一樣會產生 ΔC 的改變,兩者的關係也符合我們上述所說的:
在多變數的情況下,ΔC 與 Δv 的關係仍舊相同
只不過現在的 △v 包含了更多元素:△v ≡ ( △v1 , △v2 , △v3 , △v4 , … )T,∇C 也同樣由兩個變成了多個:
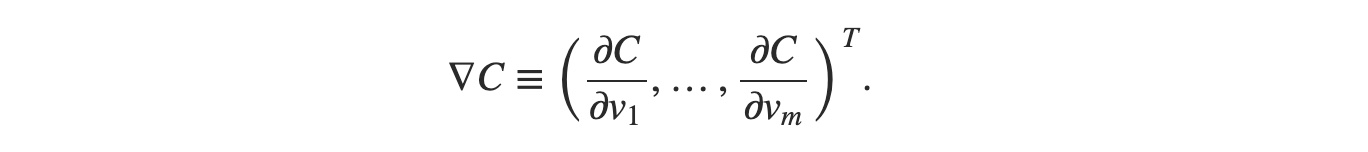
Gradient Vector 中包含了 Cost Function 對所有變數的偏微分
在兩個變數的例子中,每一次都會選擇 Δv = −η ∇C;在多個變數的例子中,我們一樣可以這樣選擇,用同樣的方式更新 v:
我們知道每一步應該怎麼走
使得 Cost Function 的數值愈來愈小。
結語
在本篇文章中,我們介紹了 Gradient Descent 的觀念,其實 Gradient Descent 就是透過計算一個函數的 Gradient Vector,得知參數更新的方向,使得函數的數值愈來愈小。此外,我們也介紹到關於 Learning Rate 的觀念,Learning Rate 是一種超參數 (Hyperparameter) 必須事先設定好。透過計算 Gradient 我們掌握了參數的「更新方向」,Learning Rate 則是讓我們決定參數的「更新大小」。
理解了 Gradient Descent 的觀念後,在下一篇文章我們將說明什麼 Stochastic Gradient Descent。