[論文介紹] VIME: Extending the Success of Self- and Semi-supervised Learning to Tabular Domain

source: OpenAI Image Generator
前言
本篇文章要和讀者分享一篇發表於 NeurIPS 2020 的論文 —— VIME: Extending the Success of Self- and Semi-supervised Learning to Tabular Domain。如果你是 CV 或是 NLP 領域的研究者,那麼你對 Self-Supervised Learning 絕對不陌生。透過 Self-Supervised Learning,我們能夠更有效率的使用 Unlabeled Data 對模型進行「預訓練」,讓模型擁有好的初始參數,當模型進一步在下游任務(Downstream Task)中 Finetune 時,也能夠表現更好。
VIME 論文的目的是將 Self-Supervised Learning 的技術應用到 Tabular Data 的領域,使得當 Labeled Data 資料量較少時,仍然能夠有良好的預測能力。利用 VIME 的方法,模型能夠從 Unlabeled Data 中學習到 High-Level Representation,進而提高模型的性能。如果你正在尋找一種在 Tabular Data 領域中應用 Self-Supervised Learning 技術的方法,那麼 VIME 可能會是一個不錯的出發點!
VIME 的目標問題是什麼
首先,我們需要了解 VIME 希望解決的問題:當 Labeled Data 非常少,但 Unlabeled Data 卻非常豐富時,使用 Labeled Data 來訓練模型容易導致 Overfitting,這樣的情況該怎麼辦呢?
在這種情況下,如何有效利用 Unlabeled Data 來提高模型的性能是一個重要課題。如同前面所說的,VIME 的目標就是要解決這個問題,並且在 Tabular Data 領域中應用 Self-Supervised Learning 技術來實現更好的模型性能。因此,如果你目前的專案正好是 Tabular Data 且 Labeled Data 同樣短缺,那麼 VIME 的想法就值得參考!
VIME 的解決方法:Self-Supervised Learning 與 Semi-Supervised Learning
了解了 VIME 想要解決的問題後,讓我們一起看看 VIME 提出的解決方法吧!
在處理 Unlabeled Data 時,VIME 採用了 Self-Supervised Learning 和 Semi-Supervised Learning 這兩種方式。
透過 Self-Supervised Learning,VIME 設計了兩個 Pretext Task,分別為 Feature Vector Estimation 和 Mask Vector Estimation,讓 Encoder 從這些任務中學習到原始資料中的有意義資訊,進而產生較佳的 Representation,以協助 Predictor 進行預測。
另外,VIME 也針對 Semi-Supervised Learning 的部分提出了一種 Unsupervised Loss,讓 Predictor 能夠從 Supervised Loss 和 Unsupervised Loss 同時進行學習。具體而言,VIME 提出讓 Predictor 分別輸入 Original Sample 和 Corrupted Sample,並將其輸出進行比較,以增加模型的 Robustness。
簡單來說,VIME 的 Self-Supervised Learning 和 Semi-Supervised Learning 方法可以有效地利用 Unlabeled Data,提高模型在 Labeled Data 少、Unlabeled Data 多的情況下的預測準確度。
深入了解 VIME 中的 Self-Supervised Learning
VIME 中的 Self-Supervised Learning 是如何運作的呢?讓我們深入了解!
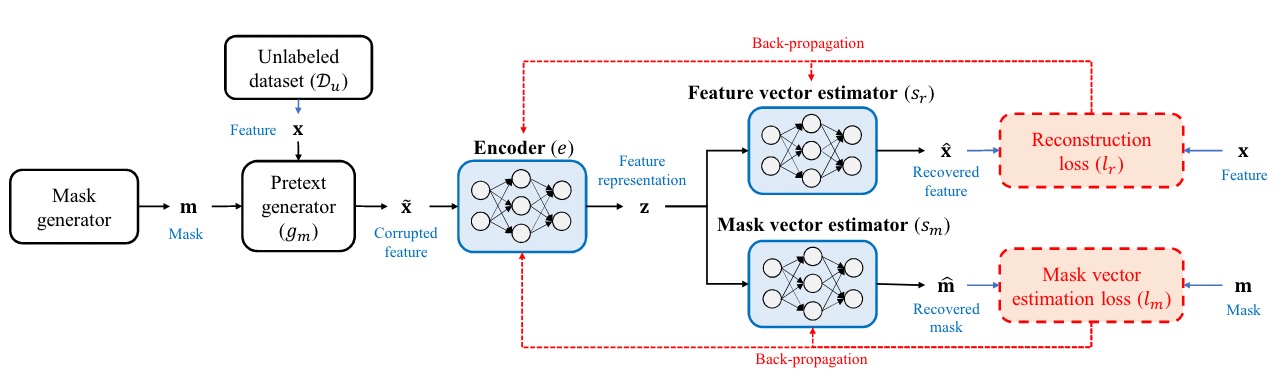
source: VIME
首先,從 Unlabeled Dataset 中取出一個 Raw Sample,假設其維度為 256 維。接下來,Mask Generator 會隨機產生一個維度相同的 Mask Vector,這個 Mask Vector 決定哪些元素要保留,哪些要被替換掉。接著,Pretext Generator 計算那些被替換掉的元素應該換成什麼數值。
這樣加工後的 Raw Sample 就成為了 Corrupted Sample,進入 Encoder 產生 Feature Representation,並進一步輸入到兩個參數不同的 MLP:Feature Vector Estimator 和 Mask Vector Estimator。
Feature Vector Estimator 進行 Feature Vector Estimation,根據 Feature Representation 要還原出原始的 Raw Sample;Mask Vector Estimator 則進行 Mask Vector Estimation,根據同一個 Feature Representation 還原 Mask Vector。
通過這樣的 Self-Supervised Learning,Encoder 可以學習到一個 Sample 中 Feature 之間的交互作用,並且生成一個良好的 Representation,其中包含關鍵資訊如:
- 哪些元素被 Mask、哪些沒有:有助於 Mask Vector Estimator 預測
- 被 Mask 的元素與沒被 Mask 的元素之間的關係:有助於 Feature Vector Estimator 還原原始的 Sample
透過這樣的 Pretext Task 訓練,VIME 實現了有效利用 Unlabeled Data 的目標。
深入了解 VIME 中的 Semi-Supervised Learning
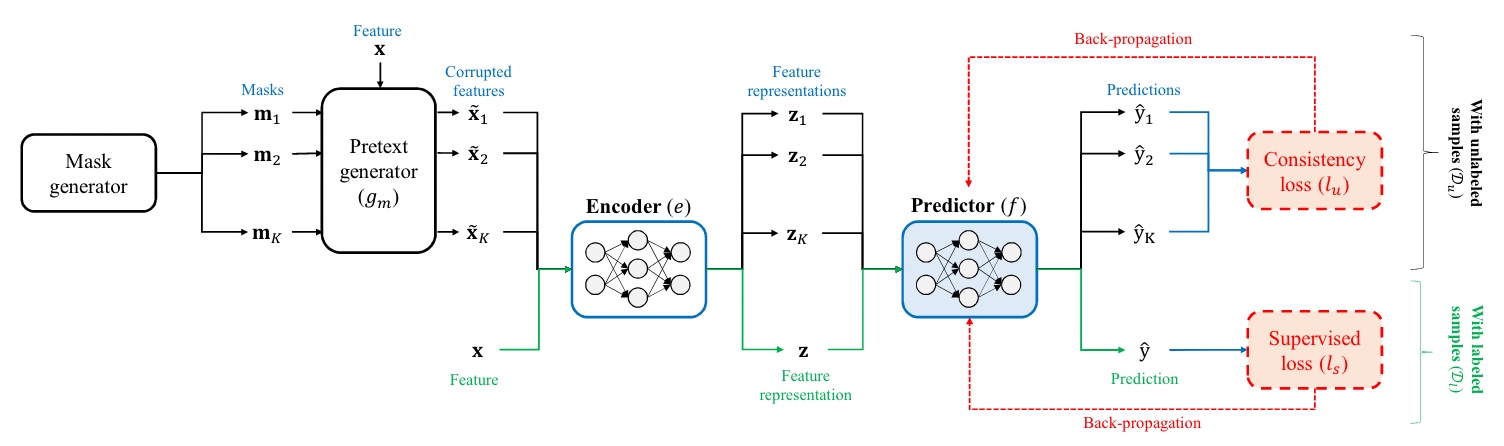
source: VIME
最後一部份,讓我們理解 VIME 中 Semi-Supervised Learning 的運作方式!
在 VIME 中,Semi-Supervised Learning 主要是用來訓練 Predictor。Predictor 不僅可以從 Supervised Loss 中學習,也可以從 Consistency (Unsupervised) Loss 中學習。透過 Raw Sample 的 Encoder 輸入,產生「良好」的 Feature Representation,然後 Predictor 進行預測,使得輸出越接近 Label 越好。
由於 Labeled Data 的數量非常少,若僅使用這些 Labeled Data 訓練 Predictor,會導致過度擬合。因此,Consistency (Unsupervised) Loss 派上用場:將 Raw Sample 經過 Mask Generator 與 Pretext Generator 加工,轉換成 Corrupted Sample。
值得注意的是,每個 Raw Sample 會搭配 K 種不同的 Mask Vector 得到 K 個 Corrupted Sample。這 K 個 Corrupted Sample 會分別輸入 Encoder,產生 K 個 Feature Representation,接著 Predictor 進行 K 個預測,Unsupervised Loss 則是計算這 K 個預測和原來的預測差距。
Predictor 需要學習的是,即使是 Corrupted Sample 的 Feature Representation 也要能夠產生相似的預測結果。這樣,VIME 中的 Semi-Supervised Learning 就能夠透過少量的 Labeled Data,有效地提高模型的泛化能力。
結論
VIME 將 Self-Supervised Learning 與 Semi-Supervised Learning 應用在 Tabular Data 領域,目的是更有效的利用 Unlabeled Data。在 Self-Supervised Learning 中,VIME 設計兩種 Pretext Task:Feature Vector Estimation 與 Mask Vector Estimation。Mask Generator 和 Pretext Generator 會對 Unlabeled Data 進行加工,產生 Corrupted Sample,進而透過 Encoder 提取關鍵的 Feature Representation。
在 Semi-Supervised Learning 中,VIME 設計了一種 Unsupervised Loss 讓 Predictor 除了可以利用 Corrupted Sample 進行學習,避免 Predictor Overfit 在少量的 Labeled Data 上。