[論文介紹] REPLUG: Retrieval-Augmented Black-Box Language Models

source: https://pixabay.com/users/jarmoluk-143740/
前言
Retrieval-Augmented Generation (RAG) 的技術在最近幾年可以說是超級熱門,因為這個技術可以讓 LLM 根據最新的(在 Pre-Training Stage)沒有看過得資料來回答使用者的 Query,降低 LLM Hallucination 的現象。本篇文章想和大家介紹一篇 NAACL 2024 的 RAG 論文 — REPLUG: Retrieval-Augmented Black-Box Language Models。 這篇論文其實早在 2023 年 1 月就發表 Arxiv 上了,不算是非常新的論文,但是論文中所提出的方法也在後續的許多 RAG 相關論文中出現,因此也還值得我們學習!此外,REPLUG 所提出的 RAG 方法也相當簡單易懂,非常適合剛接觸 RAG 領域讀者學習!
REPLUG 想解決的問題
一般的 LLM 經常會遇到的問題是,當 User 詢問一些 LLM 在 Pre-Training 或 Fine-Tuning 階段不曾學習過得知識時,LLM 很有可能會用瞎掰的方式來回答(Halluciantion)。因為要讓 LLM 學習知道自己所不知道的事情,其實不太容易。相反的,透過 RAG 的技巧,LLM 可以透過外部資料庫,得到這個問題的相關資料,來減少 Hallucination。
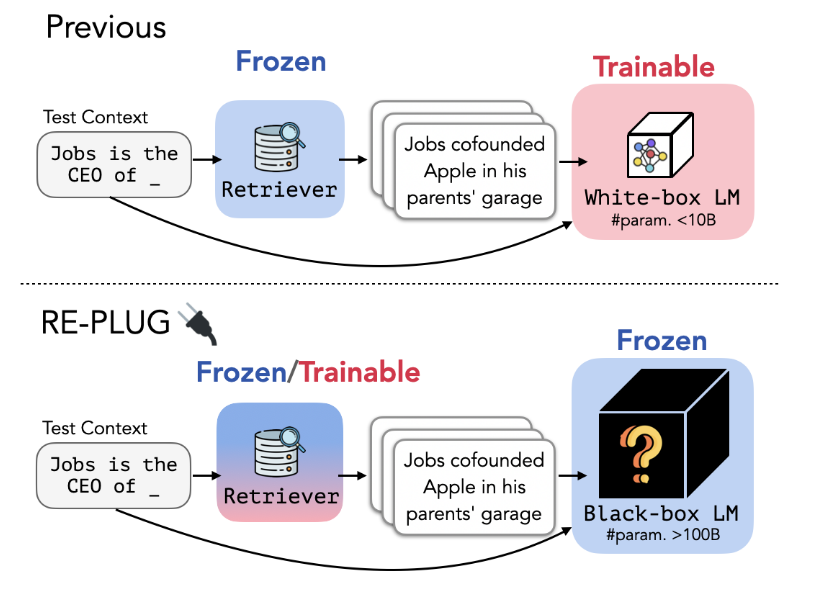
[Figure 1] Different from previous retrieval-augmented approaches that enhance a language model with retrieval by updating the LM’s parameters, REPLUG treats the language model as a black box and augments it with a frozen or tunable retriever. This black-box assumption makes REPLUG applicable to large LMs (i.e., >100B parameters), which are often served via APIs.
從上圖的 Figure 1 可以發現,過去的 RAG 的方法,大多是使用 Freeze 住(不能被訓練)的 Retriever 搭配一個可以訓練的 LLM,讓 LLM 學習根據 Retriever 所提供的 Document 生成輸出。這樣的作法有以下缺點:
- Retriever 沒有學習如何 Retrieve 出好的 Document
- Fine-Tune LLM 本身是一件高成本的事情,若要降低成本可能就必須使用較小的 LLM,然後較小的 LLM 又會降低表現
此外,現有的 State-Of-The-Art LLM 大多是 Black-Box Model,我們只能呼叫 API 的方式,提供輸入然後得到輸出,更不用說要去 Fine-Tune 它。因此,本篇論文所提出的 RAG 方法主要是聚焦在 Block-Box LLM 上!
REPLUG 所提出的方法 (1):Inference Time
REPLUG 所提出的方法可以分為兩個部份,分別是 Inference Time 以及 Training Time。這個部份會先介紹 Inference Time 如何透過 Ensemble 的技巧來提昇 LLM 的輸出品質。
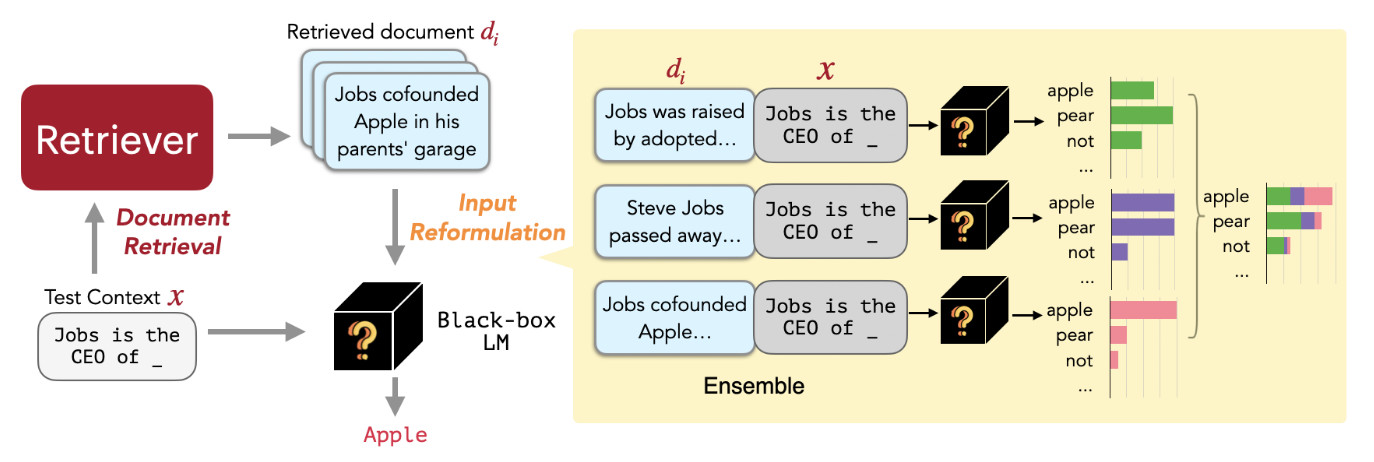
[Figure 2] Given an input context, REPLUG first retrieves a small set of relevant documents from an external corpus using a retriever. Then it prepends each document separately to the input context and ensembles output probabilities from different passes.
如上圖 Figure 2 所示,給定一個 Query(希望 LLM 回答 “Job is the CEO of ???”),Retriever 會去 External Database 中取出與這個 Query 最相似的 Document。這邊的作法其實就是一般 RAG 的方法:將 Query 與 External Database 中所有的 Document 都個別通過一個 Sentence Embedding Model 得到自己的 Embedding。接著,計算 Query 的 Embedding 與所有 Document 的 Embedding 之間的 Cosine Similarity。取出 Top-K 最相似的 Document!
有了 K 個與 Query 相關的 Document,一個簡單的做法就是將這些 Document 全部都作為 Context,與 Query 一起輸入到 LLM 中。但是這樣的做法可能會使得 Input Sequence 長度超過 LLM 的 Context Window Size。
因此,本篇論文提出一種 Ensemble 的方法:分別將每一篇 Document 與 Query 連接在一起,分別輸入到 LLM 中。每一次都會得到一個 Next Token 的 Distribution。最後將這 K 個 Next Token 的 Distribution Ensemble 在一起。
在 Ensemble 的過程中,勢必要給每一個 Distribution 一個 Weight,而這個 Weight 其實就是從這份 Document 與 Query 的 Similarity 計算而來。換句話說,如果這個 Document 與 Query 愈相似,那它的 Weight 就會愈高。
透過這樣的方法,LLM 的輸出不再只是依靠一份 Document,而是可以參考多個 Document,同時又不需要一次提供很多 Context。
備註:我的想法是,由於現在 SOTA LLM 的 Context Window Limit 不斷的擴大,也有各種 Inference Optimization 的技巧被提出來,因此這樣的作法我覺得效益可能不大。在可以負擔的 Context Size 下,一次提供所有 Document 其實也可以讓 LLM 得到更加 Global 的 Information 進而可能有更好的 Reasoning 而得到更好的輸出。
REPLUG 所提出的方法 (2):Training Time
REPLUG 所提出的第二種方法,是在 Training Stage 中針對 Retriever 進行訓練。換句話說,因為是聚焦在 Block-Box LLM,所以不可能訓練 LLM,但是應該要如何訓練 Retriever,使其 Retrieve 出能夠提昇 LLM 輸出品質的 Document。
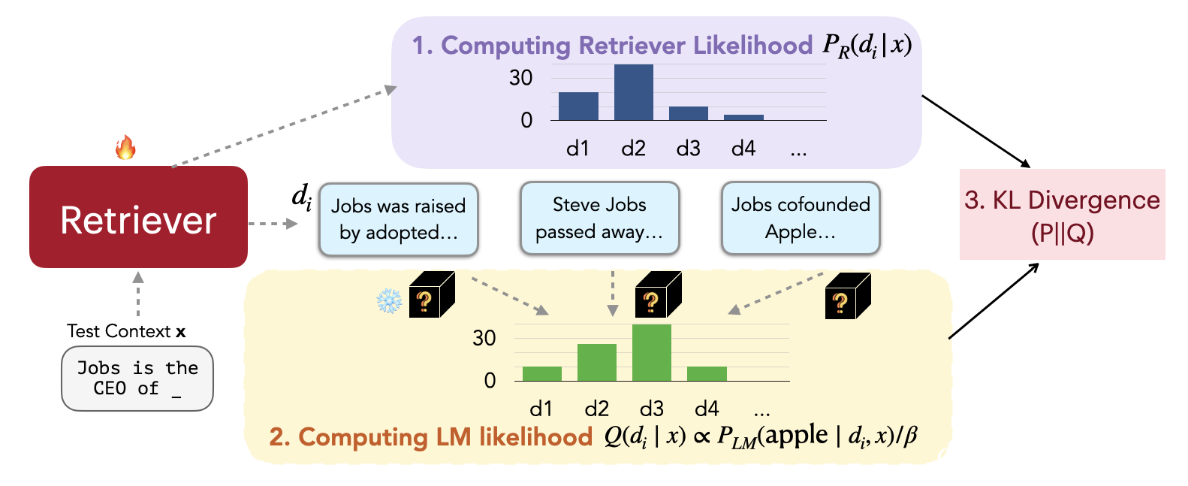
[Figure 3] The retriever is trained using the output of a frozen language model as supervision signals.
從上圖 Figure 3 可以發現到,遵循一般 RAG 的作法,首先基於目前的 Query (“Job is the CEO of ???”),Retriever 可以從 External Database 中取出 K 個 Document。透過這 K 個 Document 與 Query 的 Similarity,可以計算出這 K 個 Document 被選擇的機率值,稱為 Retrieval Likelihood。具體做法其實就是將這 K 個 Similarity 做 Softmax。
接著,將這 K 個 Document 分別與 Query 連接在一起輸入到 LLM。從 LLM 的 Output Distribution 中,將正確的那一個 Token 的機率值取出來。舉例來說,按照目前的 Query,LLM 下一個要輸出的正確 Token 應該是 “Apple”。而在這個步驟中,我們就可以得到 LLM 在看了每一個不同的 Document 後,對於 “Apple” 這個 Token 的預測機率是多少。
如果 #2 Document 與 Query 連接在一起後,能夠讓 LLM 在預測 “Apple” 這個 Token 的機率最高,那麼我們就可以想像 #2 Document 是最適合目前的 Query!透過這樣的方法,我們就可以計算每個 Document 對於正確的 Token 的機率值,稱為 LM Likelihood。
而我們最終會希望 Retrieval Likelihood 可以和 LM Likelihood 愈接近愈好,因此這兩個 Likelihood 之間的 KL Divergence 就可以當作更新 Retriever 的 Loss。
一旦 Retriever 被更新後,原先我們存在 External Database 中預先算好的每一篇 Document 的 Embedding 就會過期。因此,作者選擇每次更新 Retriever T 次後,就去更新 External Database 中所有 Document 的 Embedding!
備註:我覺得這樣的訓練方式其實蠻直觀又有效。由於 Retriever 的訓練方向是由 LLM 決定的,因此在後續的一些 RAG 方法中,經常稱這樣的訓練方法為 LLM-Supervised!
REPLUG 實驗結果
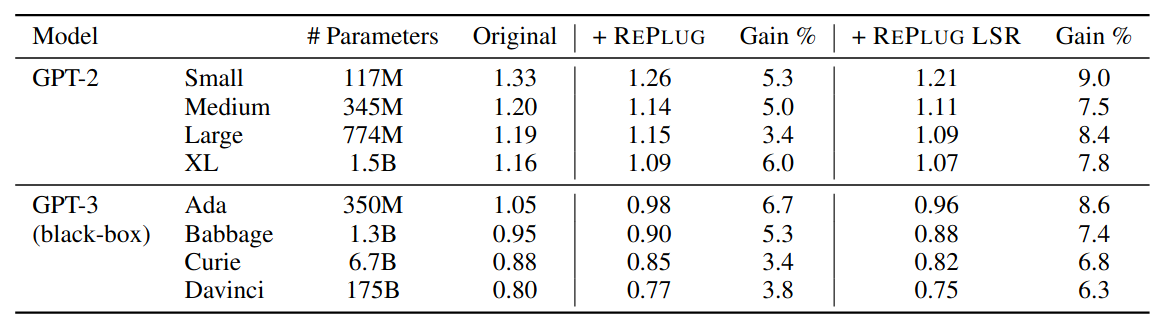
[Table 1] Both REPLUG and REPLUG LSR consistently enhanced the performance of different language models.
從 Table 1 實驗結果可以看到,不管是哪一種版本的 GPT2 or GPT3,在搭配 REPLUG 的 Inference Time 技巧後表現都提升(+ REPLUG)。如果進一步對 Retriever 做訓練,表現又會更好(+ REPLUG LSR)。
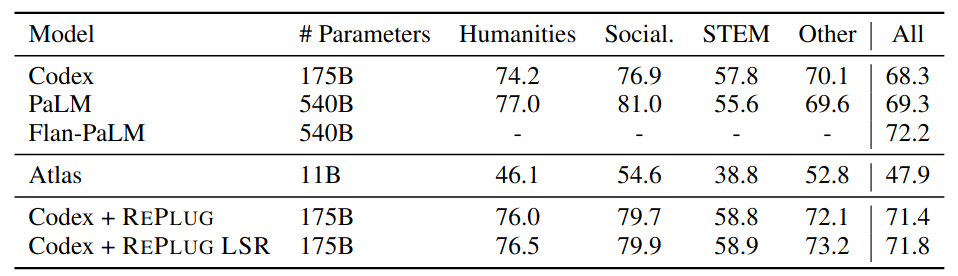
[Table 2] REPLUG and REPLUG LSR improves Codex by 4.5% and 5.1% respectively. Performance on MMLU broken down into 4 categories. The last column averages the performance over these categories. All models are evaluated based on 5-shot in-context learning with direct prompting.
在 Table 2 實驗中,作者使用 MMLU Dataset,這個資料集又分為 4 個類別。其中 Codex, PaLM 與 Flan-PaLM 是 MMLU Dataset 的 Leaderboard 中表現最好的三個 Baseline。Atlas 則是作為 RAG 方法的 Baseline。可以發現將 Codex 加上本篇論文所提出的技巧後,皆能提升其表現。
結語
本篇文章簡介了 NAACL 2024 的 RAG 論文 — REPLUG: Retrieval-Augmented Black-Box Language Models,主要針對 Block-box LLM 在 Inference Stage 透過 Ensemble Output Distribution 的技巧讓 LLM 的輸出可以同時考慮多個不同的 Document;也在 Training Stage 提出 LLM-Supervised 的方式,來訓練 Retriever 取出適合 LLM 的 Document,提昇 LLM 的輸出品質。