[論文介紹] RAFT: Adapting Language Model to Domain Specific RAG

source: https://pixabay.com/users/pedro_torres-1049378/
前言
在 LLM 的熱潮開始沒多久,Retrieval-Augmented Generation (RAG) 的技術也跟著火熱了起來。因為透過 RAG 我們可以讓 LLM 在回答使用者的問題時,也能夠參考它在 Pre-Training 或 Fine-Tuning 階段沒有看過得資料,而提昇 LLM 回答的品質。在前一篇文章中,我們分享了 REPLUG: Retrieval-Augmented Black-Box Language Models,它的定位是針對 Black-Box LLM 所設計的 RAG 方法,因此聚焦在訓練 Retriever,而不是 LLM 本身。
而今天想要和大家分享的論文是 RAFT: Adapting Language Model to Domain Specific RAG,是一篇發表於 COLM 2024 的會議論文。恰恰與 REPLUG 相反,由於 RAFT 是定位在將 RAG 應用到 Specific Domain 上,因此 RAFT 主要是針對 LLM 本身進行訓練。
我認為 RAFT 與 REPLUG 一樣都是非常簡單易懂的論文,如果你是剛進入 RAG 領域的初學者,那我覺得本篇文章也會非常適合你!
RAFT 想解決的問題
RAFT 想解決的問題就是怎麼把既有的 LLM 搭配 RAG 方法應用在 Specific Domain 上。為了要讓 Retrieval-Augmented LLM 可以理解 Domain Knowledge,作者考慮兩種方法:
- In-Context Learning + RAG:其實就是一般的 RAG,透過 Retriever 根據 Query 從 External Database 取出相關的 Document,並且將這些 Document 作為 Demonstration 放在 LLM 的 Context 中,讓 LLM 根據這些額外的 Domain-Specific Document 來回答 Query
- Supervised Fine-Tuning:直接將 LLM 訓練在 Domain-Specific 的資料集上,相當於讓 LLM 記住這些 Domain-Specific Knowledge
但是作者認為上述兩種方法都有一些缺點,並且用「考試」的例子來說明:
- In-Context Learning + RAG : 像是在考試的時候帶著一本參考書,根據考題現場翻書找答案,但是在考前都沒讀過書中的內容
- Supervised Fine-Tuning : 像是在考試前都把參考書的內容背下來了,但是考試的時候沒有帶任何參考書進去翻
其實我覺得這個比喻還蠻有趣的!為了再更清楚的描述 RAFT 想要處理的問題,作者透過「考試」來舉例:
- Closed-Book Exam:像是我們一般在使用一個不具有 RAG 功能的 LLM,LLM 僅能根據它內部的知識來回答 Query,而沒有辦法參考其他 External Document
- Opened-Book Exam:像是在 LLM 加上 RAG 的技巧,讓它可以存取到 External Document
- Domain-Specific Opened-Book Exam:則是指 LLM 一樣有 RAG 可以使用,可以存取到 External Document,但是不管是 User 的 Query 或是 External Document 都是針對某一個 Specific Domain (ex. 企業中的資料)
而本篇論文所提出的方法 RAFT 也是針對 Domain-Specific Opened-Book Exam 的任務!
RAFT 所提出方法
RAFT 的概念在於:將「In-Context Learning + RAG」與「Supervised Fine-Tuning」的概念結合在一起,讓 LLM 在考試前學習根據問題從外部知識中找到答案或是記住答案;而在考試時,也一樣可以透過 RAG 技術取得外部的知識從中找到答案,或者是根據自己的記憶回答問題。
在 RAFT 中,訓練資料集中的一個訓練樣本包含以下元素:
- Question
- A Set of Document:可以分為 Golden Document (一定可以推導出答案) 或是 Distractor Document (不包含答案相關的資訊)
- Answer:可以從 Golden Document 得到,且 Answer 是以 Chain-of-Thought Style 方式呈現,也就是它不單單只是一個 Answer 還包含了怎麼得到這個 Answer 的 Reasoning 過程
針對訓練資料集中 P% 的 Question,其 K 個 Document 中定會有一個 Golden Document,其餘都是 Distractor Document;而針對 Fraction (1 – P)% 的 Question,其 K 個 Document 全部都是 Distractor Document。 RAFT 就使用這樣的訓練資料集,透過 Supervised Fine-Tuning 的方式訓練模型。
看到這裡,我的第一個想法是:「天阿!RAFT 方法也未免太簡單了吧」,但是也覺得蠻有趣的。畢竟很多 RAG 的方法本來就會同時把 Golden 和 Distractor Document 提供給 LLM,讓 LLM 可以學習從這麼多 Document 中找到重要的資訊,同時不被其他的 Distractor Document 所影響。而 RAFT 做得更極端,是直接只提供 Distractor Document,連一個 Golden Document 都沒有!
作者強調之所以要有一部分的 Question 全都搭配 Distractor Document,是為了讓模型學會「記住」答案,而不是所有問題都從 Document 中找答案。此外,作者也特別強調,在訓練資料集中,針對 Answer 有提供 Reasoning 過程 (Chain-of-Thought Style),且還有 Cite 到 Document 中的一些內容,可以明顯提昇模型的表現。而現在因為有很強的 LLM 要生成這些 Chain-of-Thought Style 的 Answer 其實也不難!
最後,RAFT 訓練後的模型,就遵照一般 RAG 的方式對進行 Inference。
RAFT 的實驗結果
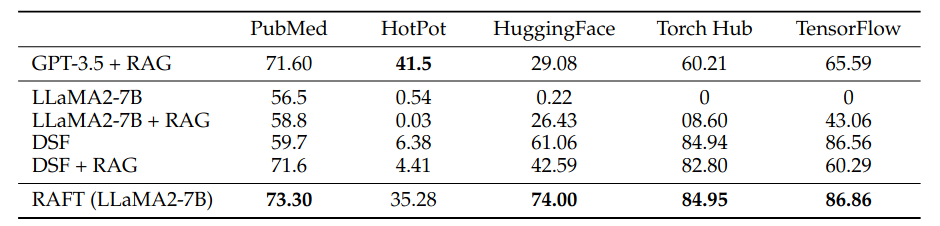
[Table 1] RAFT improves RAG performance for all specialized domains: Across PubMed, HotPot, HuggingFace, Torch Hub, and Tensorflow Hub, we see that Domain-specific Finetuning improves significantly of the performance of the base model, RAFT consistently outperforms the existing domain-specific finetuning method with or without RAG. This suggests the need to train the model with context. We compare our model with LLaMA finetuning receipes, and provide GPT-3.5 for reference.
從 Table 1 可以發現到,原始的 Llama 2-7B 不管有沒有使用 RAG (LLaMA2-7B or LLaMA2-7B+RAG) 在一些 Benchmark 上的表現都不是太好。主要是因為 Llama2-7B 的輸出沒有辦法 Align 一些 Benchmark 的格式。因此,將 Llama2-7B 做 Domain-Specific Fine-Tuning 後 (DSF or DSF+RAG),它的表現就明顯提昇許多。
但是比較神奇的是,如果把經過 Domain-Specific Fine-tuning 的 Llama2 (DSF) 搭配 RAG 的話 (DSF+RAG),他的表現反而又變差。作者認為這是因為在 Fine-Tuning 過程中,模型是直接訓練在 Domain-Specific 的 Instruction-Following Data,也就是模型學習的是看到什麼 Question 應該要輸出什麼 Answer。在這過程中,都沒有學習從 Context 中取出有用的資訊,導致模型在 Inference 即使加上 RAG 也不會從 Document 中取出有價值的資訊。
這樣的實驗結果也讓我們知道,當我們要把 RAG 的方法 Adapt 到 Specific Domain 時,不可以只單獨訓練 LLM 學習 Question-Answer 的 Mapping,而是也要加入 Retriever,讓 LLM 學習從 Retrieved Document 中取出重要的資訊來回答問題。

[Table 2] Ablation on Chain-of-Thought: The numbers of RAFT and RAFT without CoT. Results on various datasets show that adding CoT can significantly improve the performance of the finetuned model. With a gains of 9.66% and 14.93% in the Hotpot QA and HuggingFace datasets respectively.
從 Table 2 也可以明顯發現到,在訓練 LLM 進行 QA 任務時,Answer 如果有包含 Reasoning Step 則更能夠提昇 LLM 的表現。其實這個現象應該在很多 Paper 都有被提到過了!

[Figure 3] RAFT prompt to help LLM evaluate its own generated reasoning and answers, contrasting them with the correct reasoning and answers. The LLM is prompted to identify errors in its reasoning and extract key insights for improvement. This figure specifically represents the ‘GenerateExplanation‘ step in the RAFT algorithm
而要準備 Chain-of-Thought Style 的 Answer 也不難!如 Figure 3 所示,提供 Question 以及 Document,透過 Prompting 的方式讓 SOTA LLM 先產生 Reasoning Step 再產生 Answer。也有其他 Paper (ex. LongCite) 僅根據 Document,就 Prompt LLM 去生成 Query 以及 Answer,也可以再進一步 Prompt LLM 根據 Query, Answer 與 Document 去生成中間的 Reasoning Step。
![[Figure 5] How many golden documents to involve? We study the hyperparameter P% where it indicates how much portion of training data is with golden document. Results on NQ, TQA and HotpotQA suggest that mixing some amount of data that the golden document is not put in the context is helpful for in-domain RAG.](https://datasciocean.tech/wp-content/uploads/2024/10/Screenshot-from-2024-10-31-17-37-03.png)
[Figure 5] How many golden documents to involve? We study the hyperparameter P% where it indicates how much portion of training data is with golden document. Results on NQ, TQA and HotpotQA suggest that mixing some amount of data that the golden document is not put in the context is helpful for in-domain RAG.
在訓練 RAG 中的 LLM 時,故意放入一些 Distractor Document 在 Context 中,讓 LLM 學習不受到 Distractor Document 的影響,這是很常見訓練方法 (ex. RA-DIT)。但是在 RAFT 中,比較有趣的是它故意針對訓練資料集中一部分的 Question,都給他們搭配 Distractor Document。也就是說,當 LLM 在學習回答這個 Query 時,其 Context 中都沒有包含任何有用的資訊。而從 Figure 5 可以發現,在一些 Benchmark 上,模型最佳的表現不是在 100% 的 Question 都搭配 Golden Document 的情況,表示作者那樣的設計確實可以幫助模型學習得更好。
結語
本篇文章分享了 COLM 2024 的一篇論文 — RAFT: Adapting Language Model to Domain Specific RAG,RAFT 論文相當簡單易讀,非常適合剛接觸 RAG 領域的讀者!以下是 RAFT 論文的一些 Insight:
- 在訓練 RAG 中的 LLM 時,不應該只讓 LLM 學習 Question-Answer Pair 的 Mapping,而也應該要提供 Context,讓 LLM 學習從中找到重要的資訊。如此一來,在 Inference Time 時,LLM 搭配 RAG 才能有更好的表現
- 在訓練 RAG 中的 LLM 時,所提供的 Answer 如果是包含 Reasoning Step,且也有引用 Context 中的內容,更能夠提昇 LLM 的表現
- 在訓練 RAG 中的 LLM 時,放在 Context 中的 Document 並不一定要包含 Golden/Relevant Document,也可以全部都是 Irrelevant Document,這樣不僅訓練 LLM 要記住這個 Query 的 Answer(而不是學習從 Context 中找答案),也可以訓練 LLM 避免受到 Irrelevant Document 的影響