[論文介紹] HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs

source: https://pixabay.com/users/darkostojanovic-638422/
前言
如何將 AI 技術 (ex. LLM, MLLM) 應用在 Medical Domain 一直以來都是研究者所重視的方向之一。在前一篇文章中,我們介紹了 EHRAgent (EMNLP 2024) 如何將 LLM 與 Medical Domain 的知識整合,並善用 LLM 的 Reasoning 以及 Coding 能力,來讓 LLM 能夠基於包含大量 Table 的 EHR Database 進行 Table QA 任務。此外,自從 2024/9/12 OpenAI 發布 o1 模型以來,許多研究被提出希望能夠復現 o1 模型的能力,釐清 o1 模型的訓練方法。
綜合上述兩點,本篇文章想和讀者分享 HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs (2024/12) — 一篇針對 Medical Domain 的 o1 模型。讀完 HuatuoGPT-o1 後,我們將能夠學習到如何在 Medical Domain 訓練出一個 o1 模型。然而,畢竟 OpenAI 沒有公開 o1 模型的訓練方法,因此 HuatuoGPT-o1 只是一個 o1-like 模型。為了減少冗言贅字,本篇文章仍以 o1 模型稱呼之。所謂的 o1 模型和過往模型最大的差別在於 Decoding 階段,o1 模型能夠產生 Long Chain-of-Thought Style 的回答,同時能夠在推理過程中能發現自己的錯誤然後進行修正,展現出更強大的推理能力;也因為如此,o1 類型的模型除了是個 Large Language Model 外,也經常被稱為 Large Reasoning Model。
HuatuoGPT-o1 方法簡介
HuatuoGPT-o1 的方法主要可以分為以下 4 個步驟:
- Medical Question-Answer Pair Collection
- Long Chain-of-Thought Style Rationale Generation
- Supervised Fine-Tuning
- Reinforcement Learning
接著,就讓我們來依序理解每一個步驟所代表的意義!
HuatuoGPT-o1 #1 Step: Medical Question-Answer Pair Collection
這個步驟的目的是要準備一個 Verifiable Dataset,也就是這個 Dataset 中的每一個 Data Sample 除了有 Question 之外還要有 Ground-truth Answer。
首先,作者先從既有的 Closed-Set Medical Exam Dataset (MedQA-USMLE, MedMcQA) 中收集 192k 的「選擇題」。接著,透過以下 3 個步驟將這 192k 個選擇題篩選出其中比較好的 40k:
- 只選擇具有挑戰性的 Question(如果這個問題透過 3 個 Small LM 可以回答出來,那這個 Question 就會被拿掉)
- 刪除有多個答案的 Question
- 將 Closed-Set Question 變成 Open-Ended Question(將答案從選擇題的選項形式變成簡答題的論述形式)
HuatuoGPT-o1 #2 Step: Long Chain-of-Thought Style Rationale Generation
這個步驟的目的是要針對 Verifiable Dataset 中的 Data Sample,產生 Question 到 Answer 中間所經過的 Rationale。
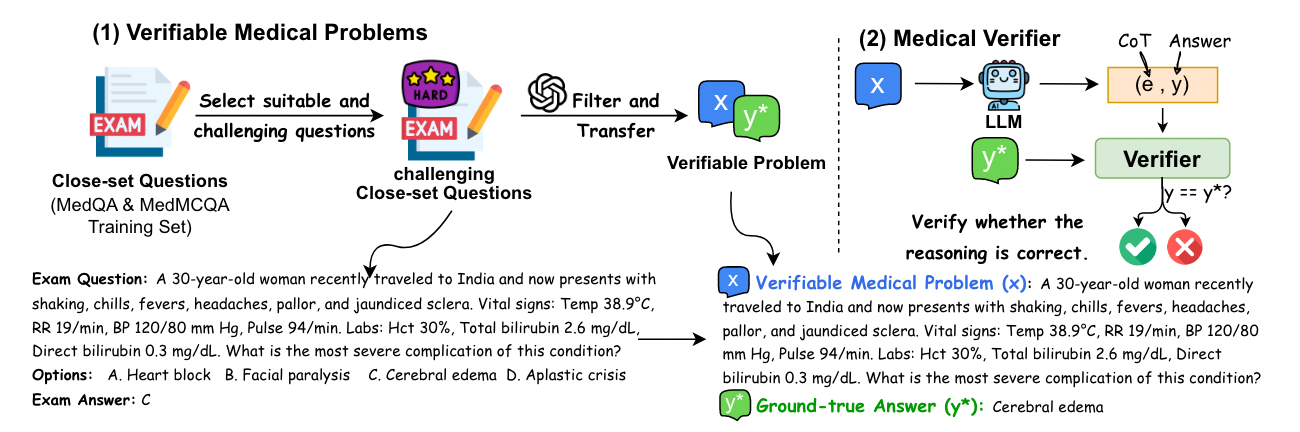
Figure 1: Left: Constructing verifiable medical problems using challenging close-set exam questions. Right: The verifier checks the model’s answer against the ground-truth answer.
如 Figure 1 所示,由於每一個 Question 都有一個已知的 Ground-truth Answer,因此當我們透過 Prompting 方式,讓 LLM 基於 Question 產生 Rationale 與 Answer 時,就可以去檢查 LLM 的 Answer 是否與 Ground-truth Answer 匹配,來確定這個 Rationale 是否正確。
當時我讀到這裡時,覺得這個步驟應該可以更簡單:單純的將 Question-Answer Pair 提供給 LLM,讓 LLM 自己產生中間的 Rationale,或是再加上一些 Prompting 的技術,使得這個 Rationale 可以比較詳細。讀完整篇論文後,我就意識到雖然這樣的作法很簡單直覺,但是這樣做法所產生的 Rationale 其實也會比較單純,這個 Rationale 彷彿只表示 Question 到 Answer 之間的 1 條 Reasoning Path。
然而,如果仔細看看 OpenAI o1 的 Response,就會發現到它花費了很多時間在 Thinking 上。在 Thinking 的過程,o1 會去探索不同的 Reasoning Path (Search),當它發現目前的 Reasoning Path 不正確時 (Self-Verification),也會再試試其他 Reasoning Path (Backtracking)。為了讓 LLM 學習到這樣複雜的思考過程,Rationale Generation 的方法也需要有相對應的設計:
首先,會先透過 Prompting 讓 LLM 基於目前的 Question 生成 Initial CoT/Rationale (e_0) 以及 Answer (y_0)。如果 Verifier 認為 LLM 所產生的 Answer 不正確(代表目前的 CoT 也是不正確的),就會再讓 LLM 隨機選擇一種 Search Strategy,根據過去的 CoT 以及 Answer 產生新的 CoT 以及 Answer。
Search Strategy 有以下四種:
- Exploring New Paths: 用一個全新的 CoT (和過去既有的 CoT 不同) 來推理出答案
- Backtracking: 選擇一個之前的 CoT,繼續進行推理
- Verification: LLM 先衡量目前的 CoT 以及 Answer 哪裡有錯,再得到一個新的 CoT 和 Answer
- Correction: LLM 修正目前 CoT 中的錯誤,然後得到一個新的 CoT 和 Answer
針對一個 Question,作者設定 LLM 的 Maximum Search Iteration 是 3 次。如果 3 次 Iteration 後仍然沒有推理出正確的答案,就會全部重頭來再嘗試一次,也就是生成新的 Initial CoT 以及 Answer。最多嘗試 3 次後,如果仍然沒有找到答案,那就會丟棄這一個 Question。

Figure 3: Example of data synthesis. Left: strategy search on medical verifiable problems until the answer is validated. Right: Merging the entire search process into efficient complex CoTs, facilitating effective deep reasoning to refine answers. The complex CoTs and responses are used to train the model to adopt thinks-before-it-answers behavior akin to o1.
到目前為止,針對每一個 Question 我們已經擁有一個 Trajectory 的 CoT 以及 Answer。舉例來說,如果 LLM 在 Search 3次後成功得到正確的答案,那麼這個 Trajectory 中會包含 [e_0, e_1, e_2, e_3, y_3)](只保留最後的正確答案)。接著,我們需要將這個 Trajectory 轉為一個 Single Complex CoT。具體的 Input 和 Output 如下方算式所示,而結果如上圖 Figure 3 所示。
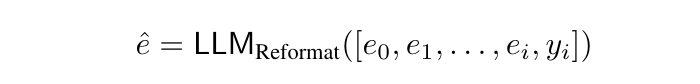
Formula: Convert Trajectory of CoT into Single Complex CoT
從 Fig 3 可以發現一個有趣的事情,將這個 Trajectory 轉為一個 Complex CoT 後,整個思考過程就像是人類一樣:做更 Deep 與 Long 的 Chain-of-Thought,且在這過程中還會修改自己的結果 (ex. “But, wait”, “But hold on”),而且思考過程的 Transition 也是自然的。將 CoT Trajectory 轉為一個 Single Complex CoT 的 Prompt 如下所示:
<Thought Process>
{Thought_Process}
</Thought Process>
<Question>
{Question}
</Question>
The <Thought Process> above reflects the model’s reasoning based on the <Question>. Your task is to rewrite the <Thought Process> to resemble a more human-like, intuitive natural thinking process. The new version should:
1. Be presented as step-by-step reasoning, with each thought on a new line separated by a line break.
2. Avoid structured titles or formatting, focusing on natural transitions. Use casual and natural language for transitions or validations, such as "hmm," "oh," "also," or "wait."
3. Expand the content, making the reasoning richer, more detailed, and logically clear while still being conversational and intuitive.
Return directly the revised natural thinking in JSON format as follows: “‘json {
"NaturalReasoning": "..."
}
基於 Complex CoT 以及 Question 來得到最終 Response 的 Prompt 如下所示:
<Internal Thinking>
{Complex_CoT}
</Internal Thinking>
<Question>
{Question}
</Question>
The <Internal Thinking> represents your internal thoughts about the <Question>. Based on this, generate a rich and high-quality final response to the user. If there is a clear answer, provide it first. Ensure your final response closely follows the <Question>. The response style should resemble GPT-4’s style as much as possible. Output only your final response, without any additional content.
最後,作者將原來 40k 個 Data Sample (Question-Answer Pair) 中的 20k 個抽取出來,進行上述的流程。因此,目前就擁有 20k 個 (Question, Complex Rationale, Response) Tuples,以及 20k 個 (Question, Answer) Pairs。
HuatuoGPT-o1 #3 Step: Supervised Fine-Tuning
此步驟的目的在於讓 LLM 學習輸出先 Long Chain-of-Thought Style 的 Rationale,再得到最後的 Response。因此,此階段主要是基於 20k 個 (Question, Complex Rationale, Response) Tuples。LLM 的輸入為 Question,而輸出為 Complex Rationale + Response。
HuatuoGPT-o1 #4 Step: Reinforcement Learning
為了更進一步優化模型的推理能力,作者還透過剩下的 20k 個 (Question, Answer) Pairs 搭配 PPO 來訓練模型。在 Reward 的計算上,主要是透過 Verifier 來比較 LLM 的 Output 以及 Ground-truth Answer 來決定:
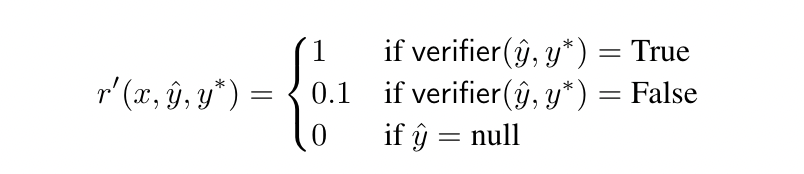
Reward Function in HuatuoGPT-o1
比較有趣的是,如果 LLM 推理出錯誤的答案,然仍會得到一個 Positive Reward(只是比較少),但是當 LLM 的 Output 沒有遵守先 Think-before-Answering 的行為模式時,就不會得到 Reward。為了在 Sparse Reward 下能有穩定的學習,最後的 Reward Function 中還會加上 KL Divergence,避免 Update 太多和 Initial Policy 差距太大。
HuatuoGPT-o1 的實驗表現
在模型訓練的細節上,作者基於 Llama-3.1-8B-Instruct 與 70B 訓練出 HuatuoGPT-o1-8B 與 70B。值得注意的是,在 Stage 1 的 SFT 的 LR 僅設定 5e-6 而 Stage 2 的 RL 的 LR 僅設定 5e-7。從下表 Table 1 也可以看到 HuatuoGPT 的表現比 Baseline 來得更好。
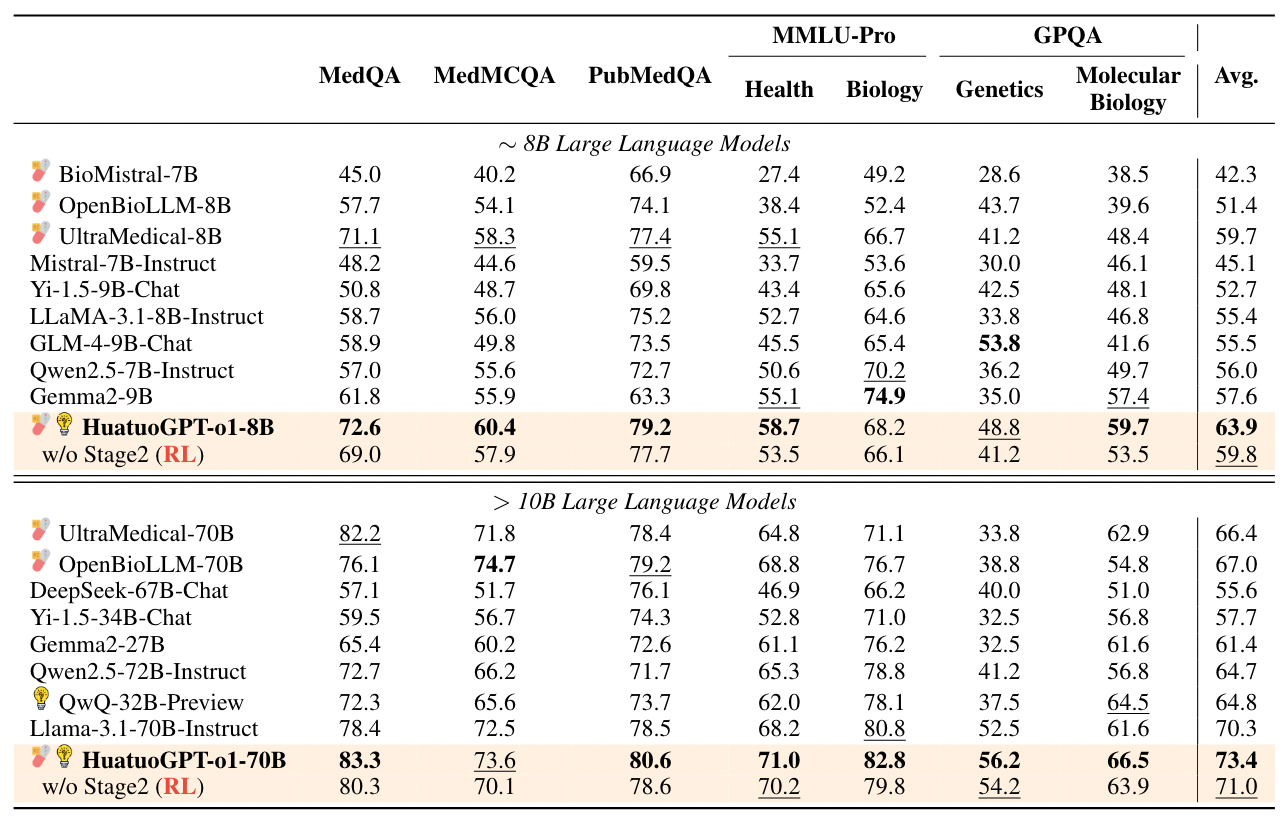
Table 1: Main Results on Medical Benchmarks. LLMs with “capsule” emoji are specifically trained for the medical domain, and indicates LLMs training for long chain-of-thought reasoning. “w/o” means “without”. Within each segment, bold highlights the best scores, and underlines indicate the second-best.
結語
本篇文章分享 HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs (2024/12) — 一篇針對 Medical Domain 的 o1 模型。讀完 HuatuoGPT-o1 後,我們將能夠學習到如何在 Medical Domain 訓練出一個 o1 模型。我覺得這篇論文讓我們學習到最多的就是,如何從頭開始且比較低成本的方式 (相較於 OpenAI o1),建立一個 Domain-Specific 的 o1 模型。包含整體流程該如何設計 (Dataset Collection, Preprocess, Transformation, SFT, RL),以及 Prompt 該怎麼寫 (Search Strategy, CoT Trajectory to Complex CoT)。