[論文介紹] EHRAgent: Code Empowers Large Language Models for Few-shot Complex Tabular Reasoning on Electronic Health Records

Source: Pixabay
前言
表格式資料(Tabular Data)是日常工作中常見的資料格式。舉凡一間有規模的公司,也經常會透過 Relational Database 儲存資料;倘若是小公司,也至少會使用 Excel 或 CSV 來紀錄一些日常的財務狀況。而不管是 Relational Database, Excel, CSV…,都是屬於 Tabular Data!
在 LLM 問世之後,我們開始會透過 LLM 在各種不同的 Data Modality 上進行推理任務,LLM 在 Tabular Modality 的推理任務當然也不例外。ICML 2025 甚至有一篇 Poster “Position: Why Tabular Foundation Models Should Be a Research Priority” 在闡述 Foundation Model 的研究應該開始從 Text 與 Image 轉向 Tabular Data。
本篇文章想和大家分享一篇 EMNLP 2024 的論文 — EHRAgent: Code Empowers Large Language Models for Few-shot Complex Tabular Reasoning on Electronic Health Records。本篇論文以 Electronic Health Record 這種 Domain-Specific 的 Tabular Data 為例,說明如何設計一個 LLM-Based Single Agent 進行複雜的 Tabular Reasoning。
EHRAgent 所遇到的挑戰
本篇論文要處理的任務,就是要將 LLM Agent 應用在 Medical Domain 的 Table-Based Question-Answering Task 上。在 Medical Domain 中,有所謂的 Electronic Health Record (EHR),其實就是電子病例的概念。在醫院的 Relational Database 中存放著大量的 EHR,假設今天有一個 EHR Query,那通常需要工程師從 Database 中進行許多檢索找到相關的 Table,才能推理出最後的答案。
因此,如果能夠讓 LLM Agent 理解這些 Table 的話,勢必可以減少許多查找的時間。然而,要設計一個針對 EHR TableQA 任務的 LLM Agent 仍有以下挑戰:
- LLM 缺乏 Medical Domain 的知識,使其難以正確的取出 Table 或是 Record
- EHR Query 所涉及的 Relational Database 通常都非常的大。例如,可能會有 26 個 Table 裡頭包含了 46K 個 Patient 的資料。要怎麼從這麼大量的 Record 中取出正確的資料
- Query 本身如果是 Multi-Hop,就還需要針對 Table 進行 Multi-Step Operation
因此本篇論文提出的 EHRAgent,就是要提昇 LLM Agent 在 Multi-Table Reasoning Task 上的表現!
EHRAgent 方法概觀
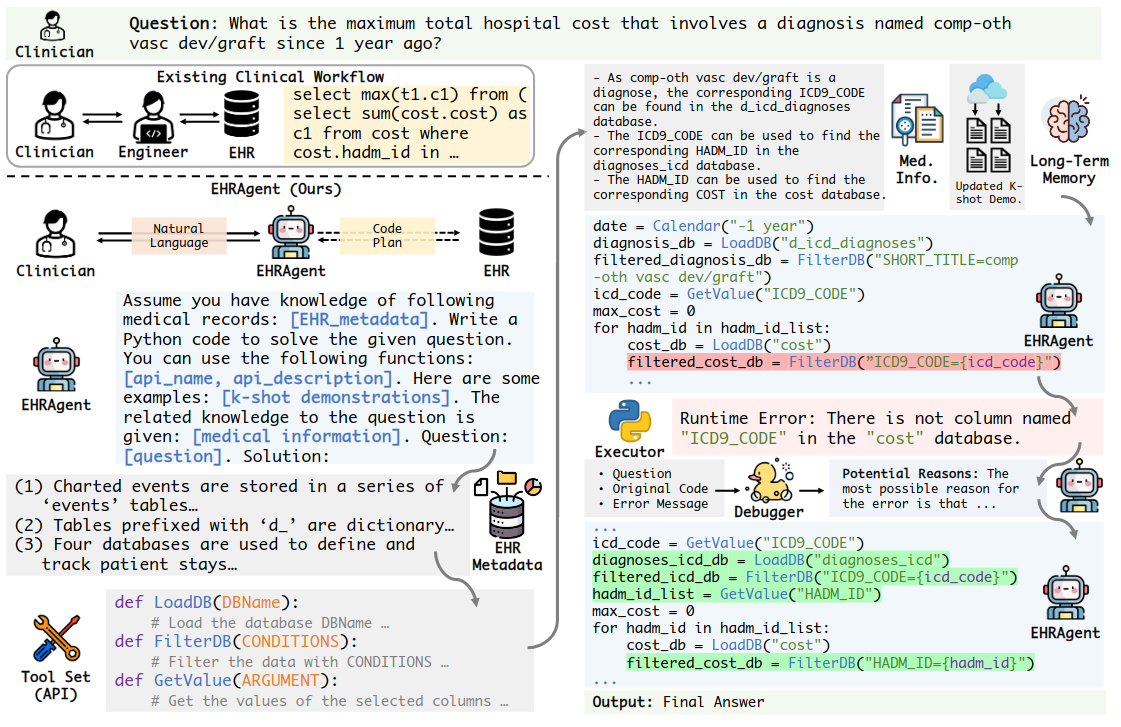
Figure 3: Overview of our proposed LLM agent, EHRAgent, for complex few-shot tabular reasoning tasks on EHRs. Given an input clinical question based on EHRs, EHRAgent decomposes the task and generates a plan (i.e., code) based on (a) metadata (i.e., descriptions of tables and columns in EHRs), (b) tool function definitions, (c) few-shot examples, and (d) domain knowledge (i.e., integrated medical information). Upon execution, EHRAgent iteratively debugs the generated code following the execution errors and ultimately generates the final solution.
如上圖 Figure 3 所示,EHRAgent 的根據 User (Clinician) 的 Query 會產生一個 Code Plan 來從 EHR Database 中得到 Answer。
為了讓 LLM Agent 所產生的 Prompt 更為明確,減少模稜兩可的情況,一個常見的作法就是讓 LLM Agent 所產生的 Plan 是透過 Code 來表達,而不是 Natural Language。
因此,在 EHRAgent 中,Plan = Sequence of Action = Sequence of Executable Code = Iterative Coding:由 LLM Agent (Planner) 負責產生 Code,然後由 Executor 實際執行 Code,並將執行結果作為 Feedback 回傳給 LLM Agent (Planner),讓它可以繼續 Refine Code。作者認為讓 Planner 與 Executor 進行這樣 Multi-Turn Dialogue 可以讓 Planner 產生更好的 Code Plan。
具體來說,EHRAgent 包含了4 個步驟:
- Information Integration
- Demonstration Optimization through Long-Term Memory
- Interactive Coding with Execution
- Rubber Duck Debugging via Error Tracing
EHRAgent #1 Step: Information Integration
此階段的目的在於提供更多 Medical Domain 的 Information 給 LLM,使其更了解目前 Query 的 Background Knowledge。具體來說,在 EHR Relational Database 中的每一個 Table,都會有一個完整的描述:
- Table Description
- Each Column Description
事先將每個 Table 的描述 (Table Description + Each Column Description) 總結出 Key Information,再將所有 Table 的 Key Information 結合透過 LLM 取出與目前 Query 相關的 Key Information 作為 Prompt 的一部分。就是 Figure 3 所呈現的 Prompt 中的 “[medical information]”。此外,也會將 Table 的 Metadata 資訊也放入 Prompt 中 (“[EHR_metadata]”)。
EHRAgent #2 Step: Demonstration Optimization through Long-Term Memory
此階段的目的在於提供與目前 Query 相似的 Experience 給 LLM,讓 LLM 可以參考這個 Experience 產生更好的 Code Plan。具體來說,需要維護一個 Long-Term Memory,裡頭主要紀錄過去成功處理的 Query 以及其相對應的 Actions (Code Plan)。基於一個 Query,會從 Long-Term Memory 中 Retrieve 出與目前這個 Query 相似度最高的 K 個 Query 及其 Actions,讓 LLM 可以參考這些 Demonstrations 進行後續的推理。就是 Figure 3 所呈現的 Prompt 中的 “[k-shot demonstrations]”。
EHRAgent #3 Step: Interactive Coding with Execution
此階段的目的在於讓 LLM 可以根據 Query 產生 Code Plan,並透過 Code 的執行結果來修正 Code Plan。具體來說,讓 LLM 基於以下內容來產生 Code Plan:
- Input Query
- Database 的 Metadata (#1 Step 產生)
- Database 的 Key Information (#1 Step 產生)
- K-Shot Demonstration (#2 Step 產生)
- Tool Function Definition
Tool Function Definition 其實就是 Figure 3 Prompt 中的 “[api_name, api_description]”。說明 LLM 可使用的 Function (ex. Calendar, LoadDB, GetValue, …)。
在此階段,會先透過 Executor 從 LLM 的 Output 中 Parse 出要執行的 Code,然後一步步執行並將執行結果回傳給 LLM,讓 LLM 可以繼續修改 Code。
很明顯這邊的核心想法其實就是讓 LLM 根據 Feedback 來改善自己的輸出,這樣的想法可說是廣泛出現在各種論文中!舉例來說,在 Self-Refine (NeurIPS 2023) 中,是直接 Prompt LLM 自己本身(而非外部工具)產生 Feedback,然後根據 Feedback 來修改原來的輸出 ;而在 CRITIC (ICLR 2024) 中則是有把外部工具的概念引進來,讓 LLM 可以自己選擇外部工具來檢查自己的輸出並產生一些 Feedback。而在本篇論文 EHRAgent 一樣也是用外部的工具來產生 Feedback,只不過是固定 Code Executor 這個工具,沒有讓 LLM 選擇其他工具。
EHRAgent #4 Step: Rubber Duck Debugging via Error Tracing
此階段的目的在於讓 Executor 的 Feedback 中可以包含更多 Insight,讓 LLM 可以更有修改 Code Plan 的方向。主要是因為作者在實做上發現,如果只提供簡短的 Error Message 給 LLM,LLM 僅會針對原來的 Code 做出一點點修改並沒有辦法真的解決問題。因此,作者將 Executor 的執行結果,Parse 出更 Detail 的 Error Information,包含 Detailed Trace Feedback、Error Type、Error Message、Location 等資訊,再讓 LLM 根據這些資訊先分析為什麼原來的 Code Plan 會出問題,最後再讓 LLM 根據自己的分析結果去修改 Code。
EHRAgent 實驗結果
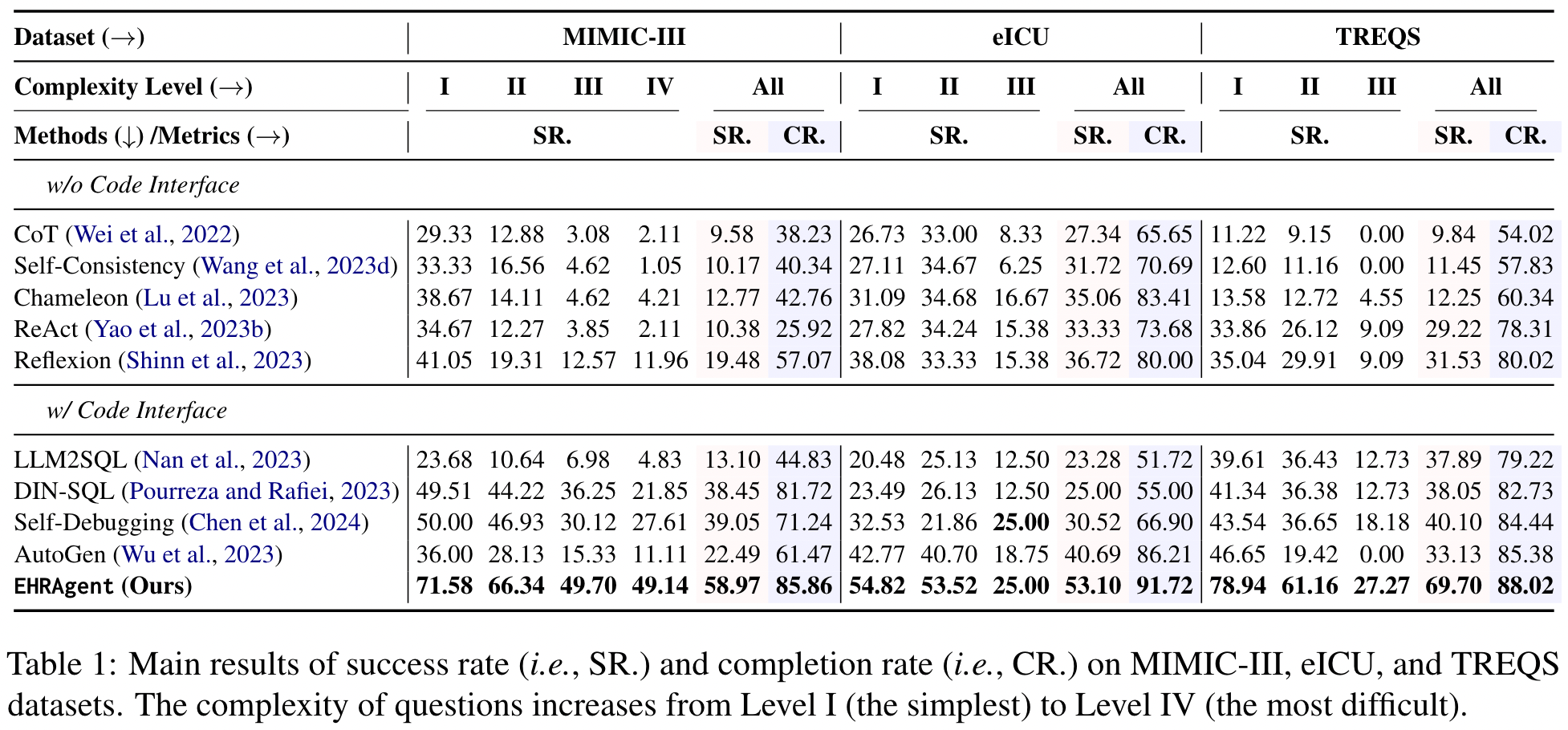
Table 1: Main results of success rate (i.e., SR.) and completion rate (i.e., CR.) on MIMIC-III, eICU, and TREQS datasets. The complexity of questions increases from Level I (the simplest) to Level IV (the most difficult).
Table 1 呈現的是 EHRAgent 和所有 Baseline 的表現。從 Baseline 的選擇上,我覺得蠻棒的,很多經典的 Single Agent 方法 (ex. ReAct (ICLR 2023)、Reflexion (NeurIPS 2023)、Chameleon(NeurIPS 2023)) 都有被納入。從 Table 1 作者提出以下 Insight:
- EHRAgent 的表現明顯勝過其他 Baseline 許多
- CoT、Self-Consistency 與 Chameleon 之所以表現不好,主要是因為他們沒有根據 Environment 給的 Feedback 來 Refine 自己的 Plan
- ReAct 與 Reflexion 雖考慮到 Feedback,但是太「著重在 Tool 所產生的 Error Message,而沒有考慮到整個 Planning」。我猜作者這邊應該是想表達 EHRAgent 的方法確實可以幫助 LLM Agent 根據 Feedback 對 Plan 做出好的修改
一些直接產生 SQL 的方法 (Ex. LLM2SQL 或 DIN-SQL) 表現不好,主要是因為產生出來的 SQL Quality 其實不夠好,此外他們也沒有 Debugging Process 來針對自己產生的 SQL Code 做更好的修改。
我覺得這邊也呼應我之前所讀到的一篇相關論文 Toward Conversational Agents with Context and Time Sensitive Long-term Memory (2024/06) 的說法:「讓 LLM 直接產生 SQL Code 然後再從 Database 中取出相對應的 Data Sample 這樣的作法其實不好。採用類似 Chain-of-Table (ICLR 2024) 的方式,讓 LLM 透過一個 Tool Chain 來對 Database 進行多次的操作會更棒。」— 就有點像是本篇論文 EHRAgent 讓 LLM 產生 Sequence of Action (Code Plan) 這樣的做法。
最後,作者也提到 Self-Debugging 和 AutoGen 是所有 Baseline 裡面做得比較好的,因為他們有考慮 Feedback,也會根據 Feedback 做分析再進行修改。但是因為他們沒有考慮到 Domain Knowledge 因此表現不好。
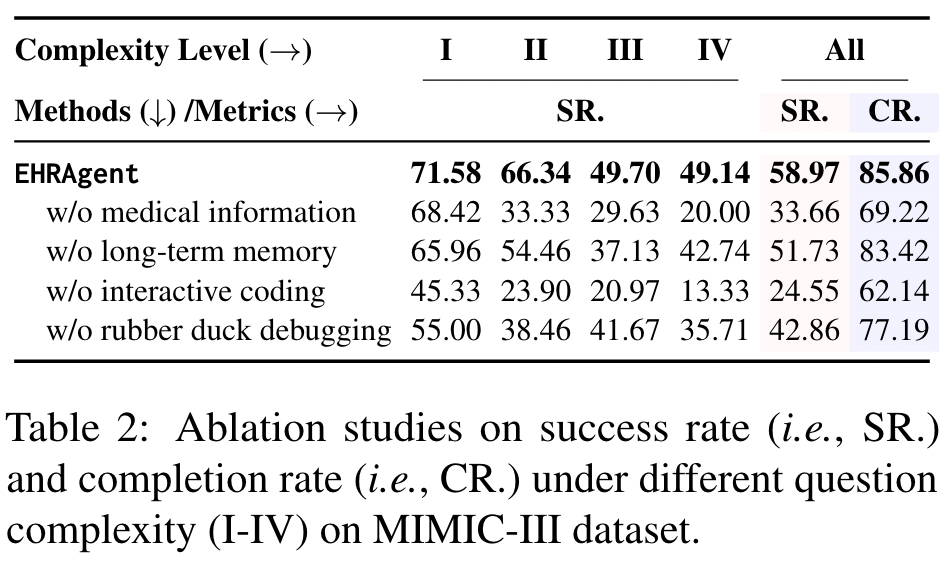
Table 2: Ablation studies on success rate (i.e., SR.) and completion rate (i.e., CR.) under different question complexity (I-IV) on MIMIC-III dataset.
從 Table 2 的 Ablation Study 中,作者強調兩個重點:
- Interactive Coding 方法扮演重要的角色
- 針對比複雜的問題,Domain Knowledge Integration 也變得愈來愈重要
結語
本篇文章主要介紹 EHRAgent (EMNLP 2024) 論文。EHRAgent 透過 Domain-Specific Information Integration、Demonstration Optimization through Long-Term Memory、Interactive Coding with Execution 與 Rubber Duck Debugging via Error Tracing 等技巧來提升 LLM Agent 於 Multi-Table Question-Answering Task 的表現。