[論文介紹] Tuning LayerNorm in Attention: Towards Efficient Multi-Modal LLM Finetuning

source: Pixabay
前言
從 2022/11/30 ChatGPT 問世以來,至今(2024/07/08)也還不到 2 年的時間,就已經有超級無敵多能夠與 ChatGPT 匹敵的 LLM 被開發出來(Claude、Gemini … 還只是常聽到的),看看 Arena Leaderboard 就可以知道 LLM 的競爭有多麽激烈,佔據排行榜不到幾週就被其他 LLM 給幹掉。從 Open LLM Leaderboard 也可以發現 Open Sourced 領域的 LLM 開發也不遑多讓!
Single Modality 的 LLM 已經不足為奇,各大科技巨頭爭先恐後的推出自家的 Multimodal Large Language Model。在 HuggingFace 上也早就已經有 OpenVLM Leaderboard,可以看到 GPT-4o 和 Claude 3.5 Sonnet 佔據目前的第一和第二名,是全世界最強的 Vision Language Model。特別註記今天的日期是 2024 年 07 月 08 日,看看這兩個模型可以在寶座上堅持多久!
今天正是想和大家分享 Multimodal Large Language Model 相關的論文,這是一篇 ICLR 2024 的 Spotlight Paper,叫做 Tuning LayerNorm in Attention: Towards Efficient Multi-Modal LLM Finetuning。這篇 Paper 算是相當好讀,相信你光看標題就可以掌握這篇論文所提出的 80% 的概念了:沒錯!就是只單純 Finetune Attention Block 中的 LayerNorm Layer,也可以把 LLM 訓練成很強的 MLLM!
本篇論文想要解決的問題
過去已經有許多研究被提出來,如何將一個 LLM 訓練成 Multimodal LLM,像是 NeurIPS 2023 Oral Paper:Visual Instruction Tuning 中所提出的 LLaVA 或是在 Enhancing Vision-language Understanding with Advanced Large Language Models 這篇論文所提出的 MiniGPT4,都已經可以成功的讓 LLM(Vicuna)變成一個可以進行 Zero-Shot Instruction-Following 的 Multimodal LLM。
在把 LLM 訓練成 Multimodal LLM 的過程,通常需要經歷兩個階段的訓練:
- 第一階段:稱為 Pre-Training 階段,通常透過很多 Image Captioning Data 訓練 Connector。這個階段的目的是希望透過這些 Image Captioning Data 訓練 Connector 將 Visual Encoder 輸出的 Image Embedding 可以 Align 到 Language Model 的 Word Embedding Space。意思就是,讓 LLM 可以開始「初步」的理解圖像這種新的模態。
備註 1:在我的印象中,大部分的 MLLM(例如:LLaVA 和 MiniGPT4),這個階段都是透過 Image Captioning Data 進行訓練,但是在 Apple 最近發表的 MM1 論文中,提到在這個階段其實也要加入其他類型的訓練資料,可以幫助 MLLM 的表現更好。
備註 2:這邊說「初步」的原因是,在我的實作經經驗中,只經過 Pre-Training 階段的 MLLM 其實就已經看得懂圖像這種模態,然而只能進行基本的「圖像描述」,而沒有辦法進行一些 Instruction-Following 的任務。
- 第二階段:稱為 Fine-Tuning 階段,通常會透過很多 Instruction-Following Data 訓練 Connector 和 LLM。這個階段的目的是透過這些 Instruction-Following Data 訓練 MLLM 不單單只是會進行圖像描述而已,還能夠根據我們的 Prompt 給出不同的回答。舉例來說,給定一張圖片,我們可以問 MLLM「這張圖片裡面有多少人」。
備註 1:在此階段中到底要 Fine-Tune 哪些 Module 沒有一個統一的說法。以 LLaVA 為例,它在此階段就同時 Fine-Tune Connector 和 LLM;但是在 MiniGPT4 中,此階段僅有 Fine-Tune Connector。
備註 2:依照我自己的訓練經驗,如果在此階段也有 Fine-Tune LLM 的話(例如:LLaVA 的做法),那麼這個 MLLM 的表現會比較好,然而因為 LLM 的參數被更動到了,就很容易發生 Catastrophic Forgetting,意思就是 LLM 原本的對話能力(Conversational Ability)會下降。為了避免 Catastrophic Forgetting,就必須在訓練資料集中也加入一些 Language-Only 的資料,讓 LLM 在訓練成 Instruction-Following MLLM 的過程,也可以保有原來的對話能力。另一方面,如果在此階段沒有 Fine-Tune LLM 的話(例如:MiniGPT4 的作法),就沒有 Catastrophic Forgetting 的問題,LLM 的對話能力還是不錯,但是相對來說,這個 MLLM 的回答似乎就沒有這麼的精確。
為了提升 MLLM 的表現,我們可能會選擇在第二階段的訓練(Fine-Tuning 階段)中把 LLM 也一起加入訓練。然而,通常這些 LLM 的參數量都非常多,光是上文舉例的 LLaVA 所使用的 Vicuna 就已經有 7B 的超參數,要 Fine-Tune 這 7B 的參數,我相信不是所有老百姓都可以支援的。
因此,本篇論文就是希望可以更有效率的在第二階段中 Fine-Tune LLM 而提出 Tuning LayerNorm in Attention 這樣的作法!
Tuning LayerNorm in Attention
因此,本篇論文提出的做法為:只需要在第二階段的訓練中,Fine-Tune Attention Block 中的 LayerNorm 就可以幫助 LLM 變成一個不錯的 MLLM。
作者會有這樣的想法是因為他們將 LLM 訓練成 MLLM 的過程視為是一種 Domain Adaption,也就是從原來的 Text Domain 變成 Multi-Modal Domain。而過去又有研究指出,如果要讓模型適應 Domain Shift,調整 Normalization Layer 會是一個有效的做法!
因此,在實作層面上,這篇論文實在沒什麼好說的,就是在第二階段訓練時將 LLM 中 LayerNorm 的參數的 “reguire_grad” 設為 True 就可以了。
實驗結果
作者在比較各種不同的 Fine-Tuning 方法時,都會先將 MLLM 的 Connector Pre-train 3 個 Epoch,然後才對 MLLM 進行 Fine-Tune。簡單來說,大家用相同的 Pre-Training 方法,然後比誰的 Fine-Tuning 方法比較好!
在實驗中階段,作者總共比較了 6 種 Fine-Tuning 方法:
- Finetune:微調 LLM 中的所有參數
- LoRA:在 LLM 中的 Linear Structure 加上 LoRA Component (Rank = 32),然後微調這些 Component
- Attn. QV Proj.:微調 Attention Block 中的 Q 和 V Linear Projection
- Attn. MLP:微調 Attention Block 中的 MLP
- LayerNorm:微調 Attention Block 中的 Input 和 Post LayerNorm
注意:在 Fine-Tuning 階段中,(Vision-Language)Connector、LLM Word Embedding 和 LLM Output Head 也有一起被微調!
從下表 Table 1 可以發現,在所有的 Fine-tuning 方法中,只有微調 LayerNorm 竟然也可以得到不錯的表現:
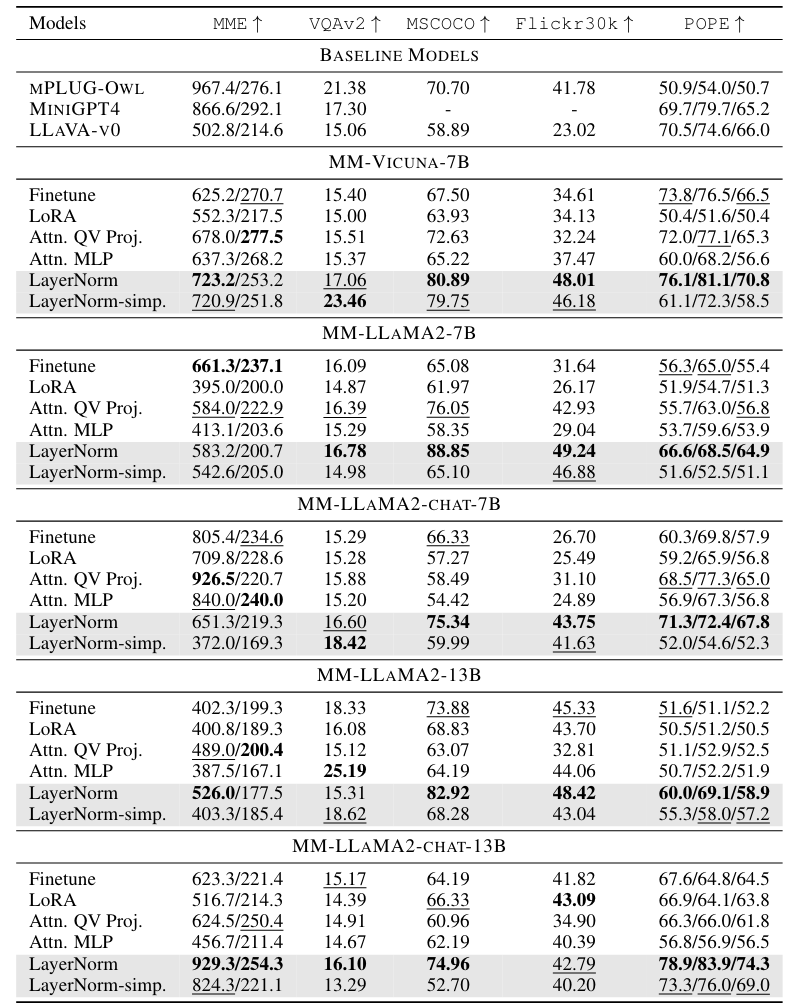
Table 1: Model performance on five multi-modal benchmarks with different components tuned in the LLM. We mark the best results with bold and the second best scores with underline. ‘-’ means the model cannot follow the required output format on captioning tasks.
Table 1 中的 LayerNorm 實際微調的參數除了有 Attention Block 中的 LayerNorm 外,還有:
- Vision-Language Connector
- LLM Word Embedding
- LLM Output Head
那我們可不可以只單純微調 LayerNorm 就好,另外三個都不要。換句話說,作者希望確認「真的只要微調 LLM 中的 LayerNorm 就可以有不錯的表現」。在 Table 1 中的 LayerNorm-simp. 就是這這設定下的實驗結果,可以發現結果其實也還不錯:在一些 Benchmark 上,其表現甚至和 Full Fine-Tuning 一樣好或是更好。
從下表的 Table 2 也可以看到各種不同 Fine-Tuning 方法的 Memory Consumption:
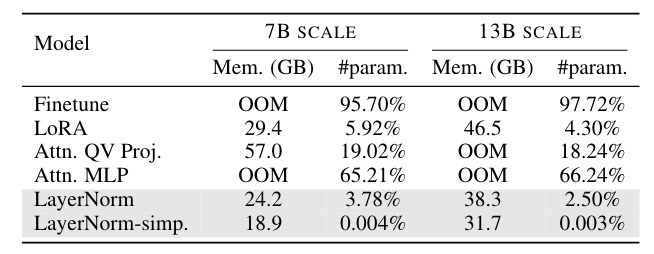
Table 2: Memory consumption and percentages of trainable parameters tested on a single A100 GPU.
可以發現 “LayerNorm” 和 “LayerNorm-simp.” 的微調方法,對於 GPU Memory 的負擔真的小很多。
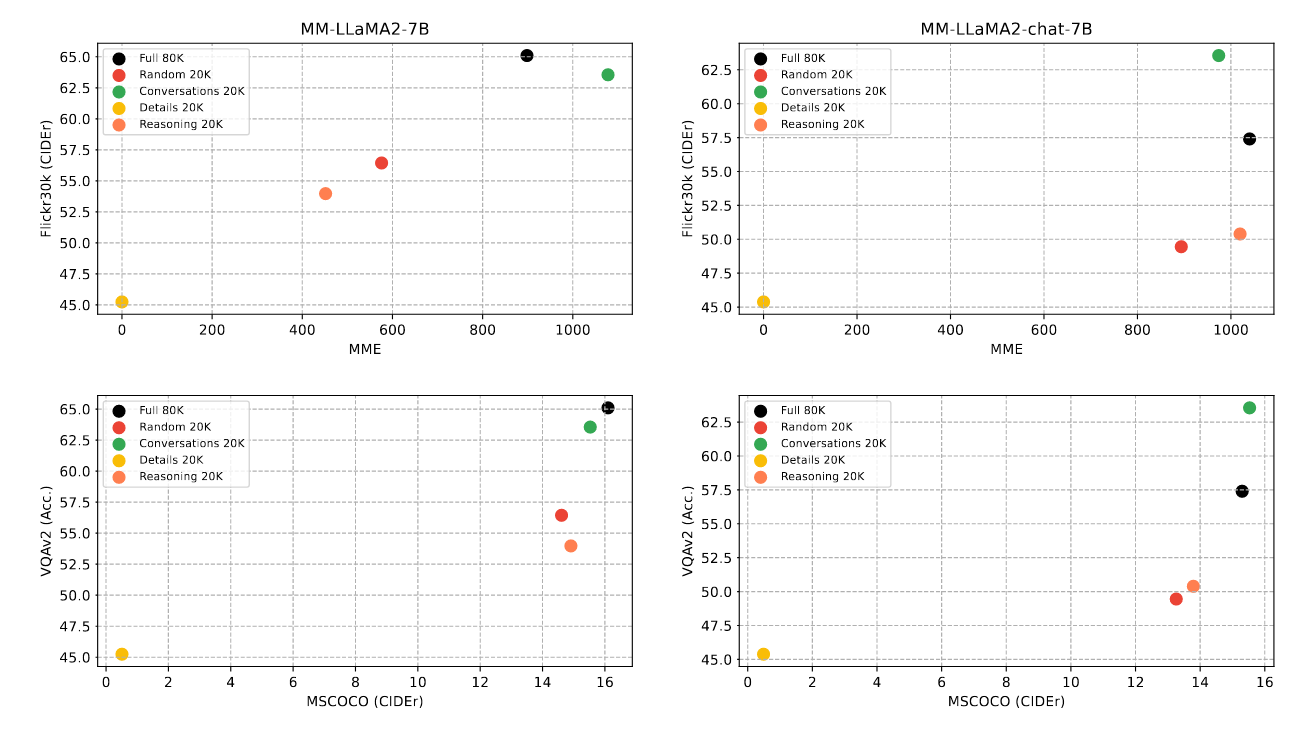
Figure 2: Performances of models that are finetuned on different datasets on four multi-modal benchmarks. The MME score is the sum of both Cognition and Perception scores on the benchmark.
除此之外,作者也分析在 Fine-Tuning 階段所使用的訓練資料集類型,對於 MLLM 能力的貢獻為和。在 Fine-Tuning 階段所使用的 Instruction-Following Data 主要可以分為三種類型
- image-grounded conversation
- image detail descriptions
- image-based complex reasoning
從上圖 Figure 2 可以發現 image-grounded conversation 是比較有效率的類型,相同的資料量下,它更可以提升 MLLM 的表現。
然而,在這邊我有一些質疑:作者這邊的 20K 是指「樣本數」,但是會不會在相同的樣本數的情況下,conversation 資料所包含的 Token 比較多,因此模型學得更好?如果你知道答案的話,也歡迎在下方留言告訴我!
如同前面所說的,在 Fine-Tuning 階段中所使用的不同 Fine-Tuning 方法下,Vision-Language Connector 預設都會被允許微調。
會不會其實 Vision-Language Connector 才是讓模型從 Text Domain (LLM) Adapt to Multi-Modal Domain (MLLM) 的關鍵?
從下表 Table 4 可以看到,當然同時微調 LayerNorm 和 Connector 整體來說會有比較好的表現。然而,如果只微調 Connector 的話,可以發現表現變差很多;如果只微調 LayerNorm 的話,MLLM 的表現也會變差,但是相對來說沒有掉那麼多:
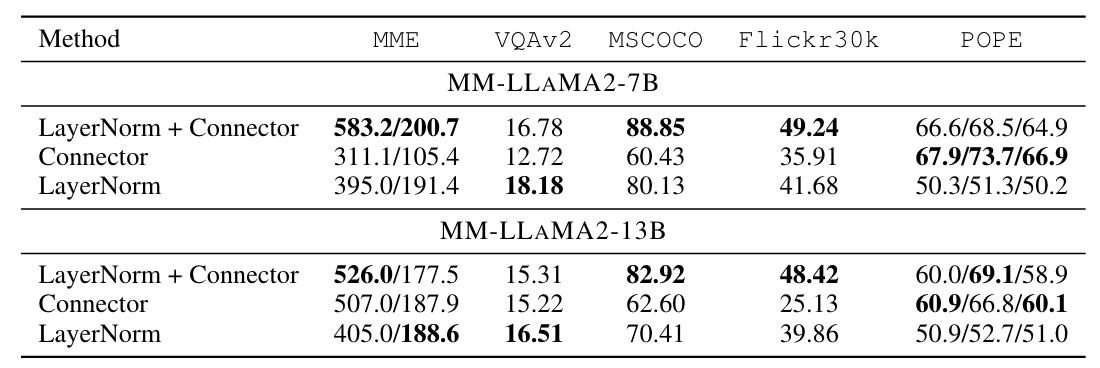
Table 4: Results of models with LayerNorm and/or vision-language Connector activated.
讀到這裡,相信你也已經了解到在訓練 LLM 變成 MLLM 的過程,如果在地案階段只 Fine-Tune LLM 中的 LayerNorm 而非整個 LLM,也可以很有效率的讓最終的 MLLM 表現不錯。但是為什麼呢?LayerNorm 是什麼神奇的 Module?
為了要理解為什麼只微調 LayerNorm 會比微調整個模型帶來更好的表現,作者分析了模型中所有的 Layer 的 Representation 的相似度。
下表 Table 6 呈現的是三種不同的模型透過兩種不同的微調方法訓練後,所有的 Layer Representation 之間相似度的平均值,可以發現只微調 LayerNorm 的相似度會比較低:
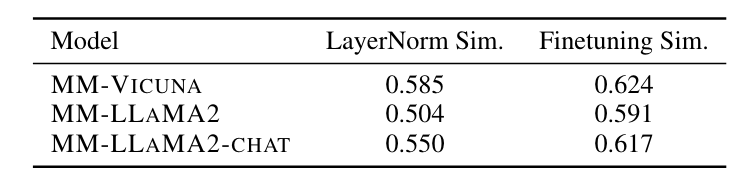
Table 6: Layer representation similarity of LayerNorm and finetuning methods on three 7B MLLMs. Lower the similarity is, the better expressive power a model possesses.
當一個模型的 Layer 之間的相似度低,就表示這個模型的表達能力更強,可以掌握更多 Data 內的 Pattern。這是作者所提出的一個理由之一,作者也有試著從訓練過程中 Gradient Variance 的角度切入來解釋,如果有興趣可以再閱讀這篇論文。
結語
本篇文章和大家分享了 LLM 訓練成 Multimodal LLM 的許多觀念(Pre-Training & Fine-Tuning),透過 Tuning LayerNorm in Attention: Towards Efficient Multi-Modal LLM Finetuning 這篇 ICLR 2024 的論文分享更有效率的 Fine-Tuning 方法:只需要在第二階段的訓練中,Fine-Tune Attention Block 中的 LayerNorm 就可以幫助 LLM 變成一個不錯的 MLLM。並透過實驗說明,這樣的 Fine-Tuning 方法確實有效,在一些 Benchmark 上,其表現甚至和 Full Fine-Tuning 一樣好或是更好。最後,作者也透過 Layer Representation Similarity 或是 Gradient Variance 的角度來解釋為什麼僅 Fine-Tuning LLM 中的 LayerNorm 就可以讓 MLLM 達到不錯的表現!
希望透過本篇文章幫助你學習到一些 Multimodal LLM 的新知,也歡迎在底下留言提出你的想法或建議!