[論文介紹] GAIA: A Benchmark for General AI Assistants

General AI
前言
在 ChatEval 一文中和大家介紹了 LLM Agent 的概念,以及如何透過 Multi-Agent 的框架,讓多個 LLM Agent 進行 Debate 來衡量(Evaluate)其他 LLM 的輸出。然而,有沒有一個 Benchmark 可以衡量一個 Agent 能力呢?今天要和大家分享一篇 ICLR 20204 Poster 的論文叫做 GAIA: A Benchmark for General AI Assistants,這篇論文正是提出了一個 Benchmark 來衡量一個 General AI Assistant 的能力!
之所以想和大家分享這篇論文,除了這篇論文有趣之外,另一個原因是這篇論文的作者竟然有 Yann LeCun!身在 AI 領域應該都聽過 Yann LeCun 這號人物,前陣子還和 Elon Musk 在 X 上大戰呢 …

本篇論文的作者看起來都相當大咖
GAIA Benchmark 想要解決的問題
現今世界已經有那麼多 Benchmark 可以來衡量 LLM Agent 的能力,為什麼還需要提出一個 GAIA Benchmark 呢?它跟過去大家所使用的 Benchmark 有什麼不同呢?
舉例來說,在 Meta 發表 Llama 3 時就使用了 MMLU、HumanEval、GSM-8K 等常見的 Benchmark 來衡量其 LLM 的能力:
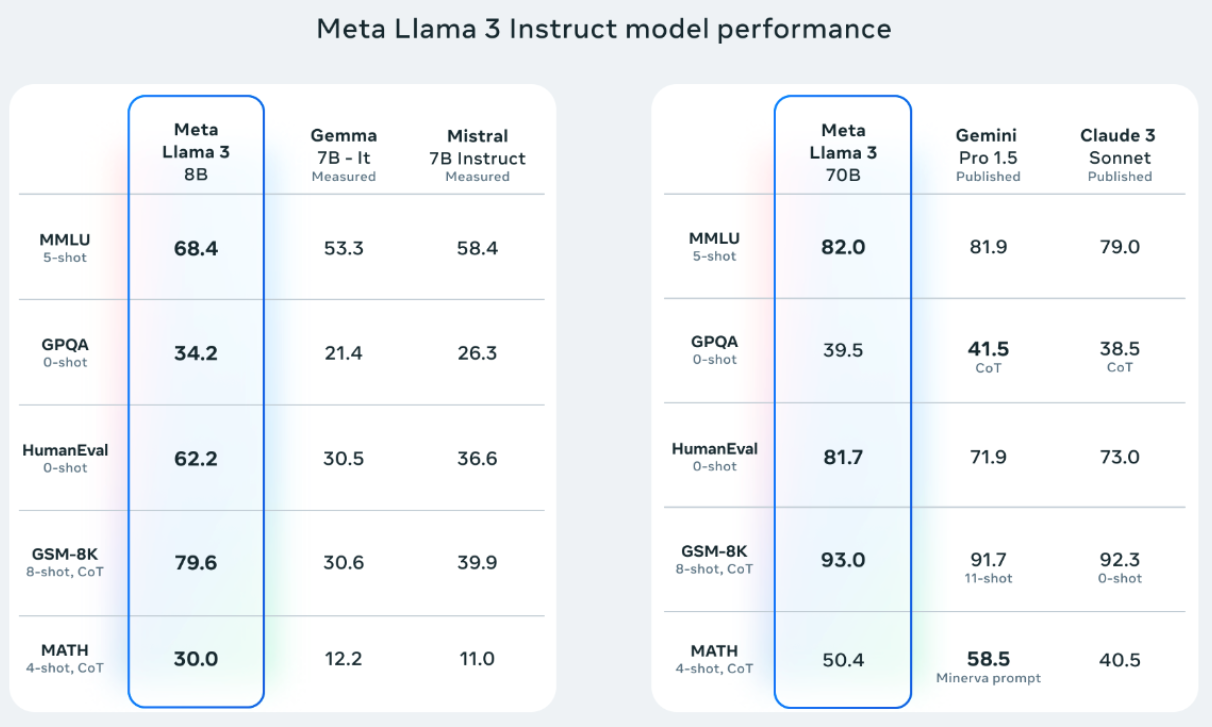
Llama 3 Benchmark
在 Nvidia 發表 Nemotron 時,也使用了類似的 Benchmark 來表示其 LLM 有多麽聰明:
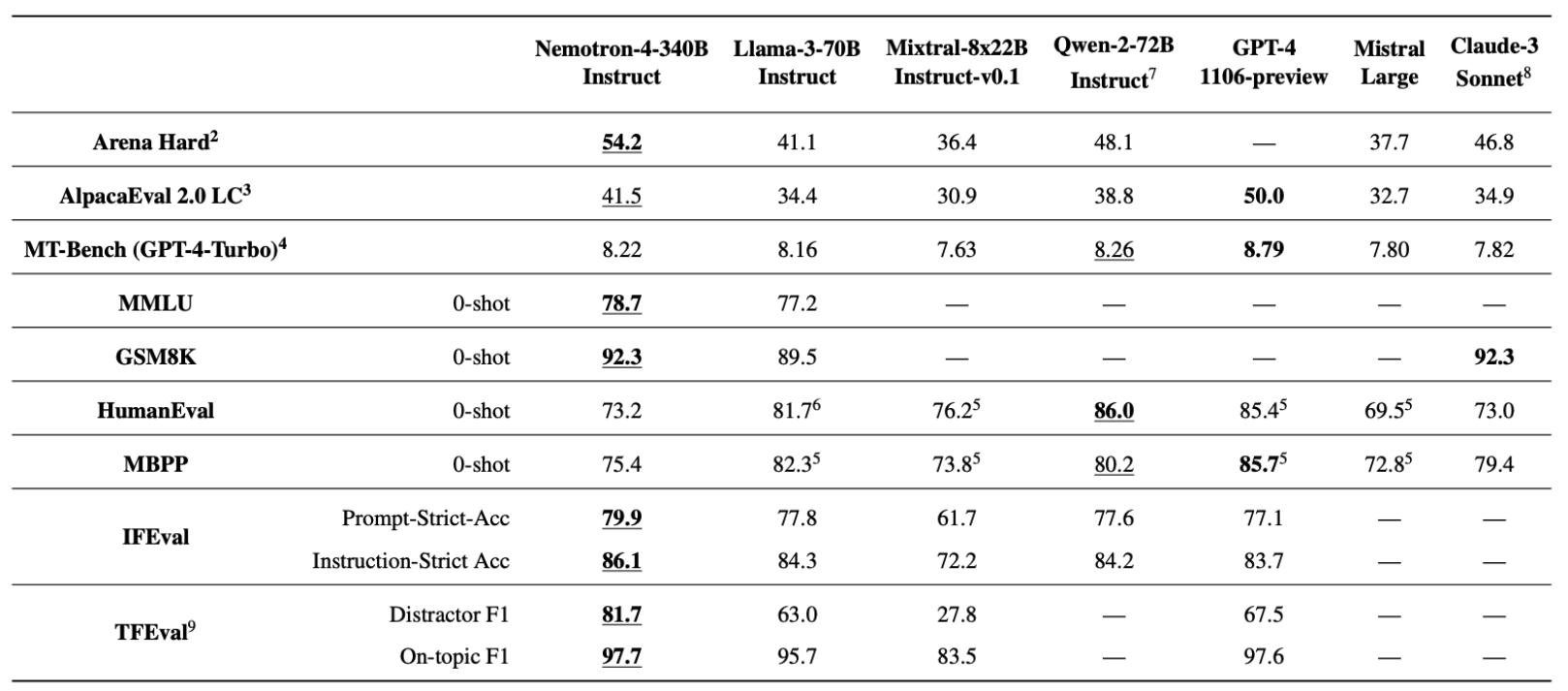
Nemotron Benchmark
GAIA 所想要解決的問題正是認為過去這些 Benchmark 雖然可以衡量 LLM 的知識量(或是說聰明程度),但是和 General AI Assistant 的能力卻不完全一致!
舉例來說,以下是來自 MMLU Benchmark 的兩個 Sample 以及 GSM8K Benchmark 的一個 Sample:
# Question 1
Paper will burn at approximately what temperature in Fahrenheit?
# Answer 1
986 degrees
# Question 2
Which of the following heavenly bodies have never had a spacecraft landed on it?
# Answer 2
Jupiter
# Question 3
Paddington has 40 more goats than Washington. If Washington has 140 goats, how many goats do they have in total?
# Answer 3
If Washington has 140 goats, Washington has 140+40 = <<140+40=180>>180 goats. In total, they have 140+180 = <<140+180=320>>320 goats #### 320
從上述的範例應該可以感受到,假如 LLM 可以在這些問題上回答的很好,我們可能會覺得它很聰明(什麼都懂),但是在這些問題上回答的很好,就是代表我們距離 General AI Assistant 又更靠近了嗎?
我想答案絕對是否定的!在 GAIA 論文中也有提到,現今我們在衡量 AI 模型(LLM) 的能力時,大多會用一些連人類也做不好的問題來衡量,這些問題大多是一些專業領域相關的問題。然而,從近幾年 AI 模型屢次在 MMLU 或 GSM8k 這些 Benchmark 上獲得好成績的趨勢來看,AI 已經愈來愈擅長這些特定艱難的任務。
此外,目前在衡量 AI 模型(LLM) 的 Benchmark 中,有些也是屬於 Open-Ended Generation 的類型,意思就是說這些問題並沒有一個標準的答案,或是說這些問題的答案通常需要透過比較多的文字來描述。那這樣就會導致我們在衡量某一個 AI 模型在這種 Benchmark 上的表現時,可能就必須透過其他 AI 模型或是 Human 作為裁判(Judge)而沒有辦法透過 Rule-Based 的方式來檢查 AI 模型的輸出。然而,這些問題其實也有可能是既有的 AI 模型或是 Human 所回答不出來的,那又怎麼能夠請他們擔任裁判呢?
GAIA Benchmark 介紹
理解了 GAIA Benchmark 想要解決的問題後,我們開始介紹 GAIA Benchmark 的獨特之處!
GAIA Benchmark 中包含 466 個 Question/Answer Pair,每一個 Question 都是 Text-Based,有時候會有額外的檔案 (例如,圖像檔案或是 CSV 檔案)。如下圖為 GAIA Benchmark 中各種檔案類型的統計:
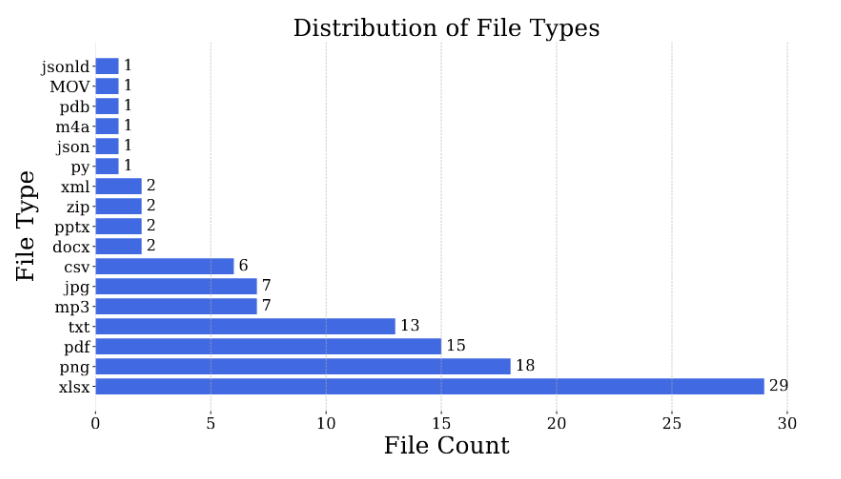
GAIA Benchmark 中所包含的檔案類型
GAIA 中的 Question 可能是日常工作常見的文書任務、科學問題或是通用的知識性問題。而GAIA 中最重要的特色就是每一個 Answer 都是簡短、簡單、容易驗證的(避免模稜兩可的狀況出現),但都需要很多不同面向的基本能力,才有辦法得到這一個 Answer。
具體來說,GAIA 中的 Answer 要馬是一個 Number 或是一個 String 或是 A List of String,且正確答案只會有一個。此外,我們又可以透過 System Prompt 告訴 Agent 應該輸出怎麼樣的 Answer Format,這對於 Automated Evaluation 會很有幫助。而 AI 模型如果要在 GAIA Benchmark 上得到高分,就必須具備以下幾種能力:
- Advanced Reasoning
- Multi-Modality Understanding
- Coding Capability
- Tool Use
如下圖(左)呈現的是每一種技能所包含的問題數量,可以發現大部分的問題都沒有辦法直接透過 AI 模型既有的知識來回答,AI 模型必須學習透過 Web Browsing 的方式來得到正確答案。下圖(右)呈現的是每一種難度的問題需要使用多少種不同的工具,以及多少個步驟才能得到答案。
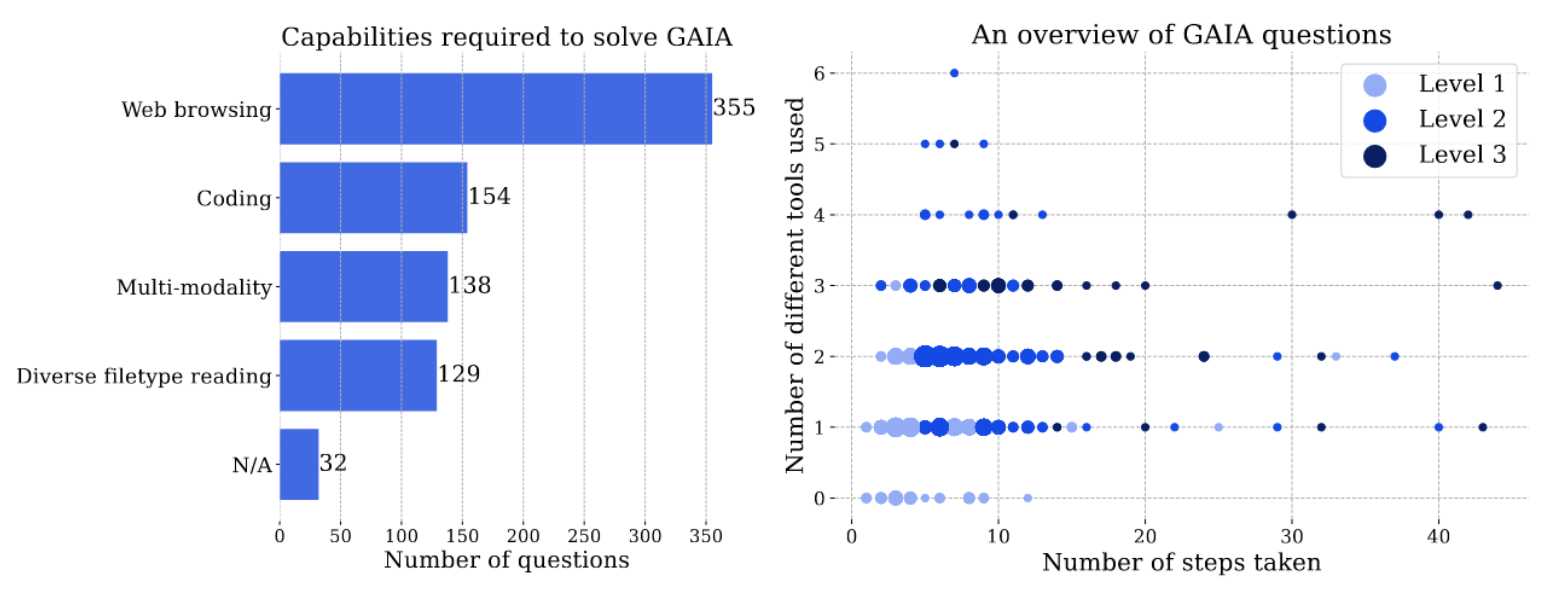
GAIA Benchmark 的問題難度
GAIA Benchmark 的使用方式也相當直觀,直接使用官方所提供的 System Prompt 對 AI 模型進行 Zero-Shot 的 Inference 即可。如下圖是官方所提供的 System Prompt 以及一個範例的問題:

System Prompt of GAIA Benchmark

Sample Question in GAIA
最後,作者透過 GAIA Benchmark 來衡量多個 SOTA LLM 以及 Human 的表現:
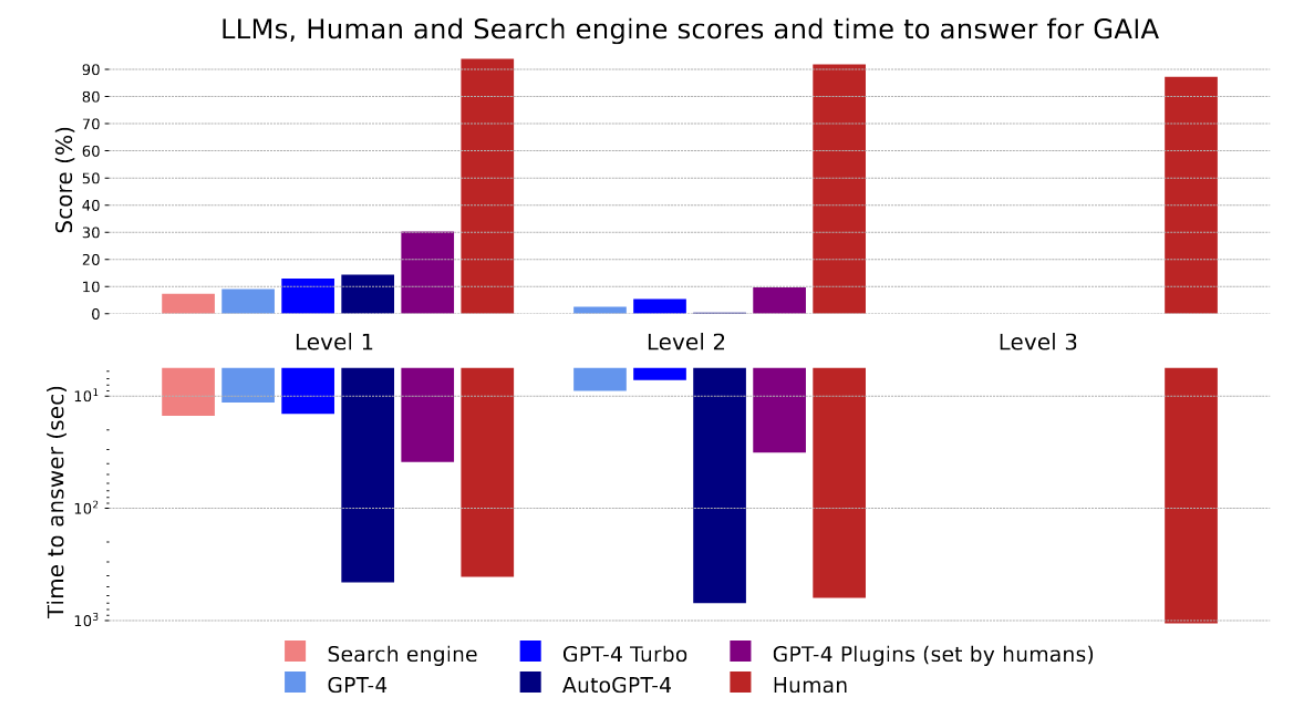
多個 SOTA LLM 在 GAIA Benchmark 上的表現
可以發現連前陣子最強的 GPT-4 Turbo 模型在 Level 1 問題的表現也只有 10 ~ 20 分,透過 Human 的幫助頂多可以到 30 分。在 Level 2 和 3 的問題上,這些既有的 SOTA LLM 表現的又更差。但你發現到了嗎!不管在 Level 1、2 還是 3,Human 所得到的分數幾乎都在 90 分上下!
我覺得這正是 GAIA Benchmark 的有趣之處 —— 它設計了一些對於 Human 來說簡單但是對於現今的 AI 模型來說困難的任務!它不單單只是考驗 AI 模型到底知道(記住)了多少知識,而又更進一步衡量 AI 模型會不會使用工具、能不能理解多種不同的資料類型、有沒有更強的推理能力以及能不能自己撰寫一些程式碼來進行分析。當 AI 模型有能力在 GAIA Benchmark 上有好的表現時,也象徵著這個 AI 模型又更像 General AI Assistant 了。
結語
在本篇文章中,和大家分享了 GAIA: A Benchmark for General AI Assistants 這篇 ICLR 2024 的 Poster 論文。原本只是看到:「哦~是 ICLR 的論文」(感覺值得讀一下),後來又看到「哇,是 Meta 發的」(感覺蠻有趣的),最後又看到「Yann LeCun 也是作者之一」(那真的必須一定要讀了)!
本篇論文提出了一個 Benchmark 來更準確的衡量一個 AI 模型是否具備 General AI Assistant 的能力,同時巧妙的設計 Answer,避免有模棱兩可的狀況出現,讓我們更容易透過 Ruled Based 方式來衡量 AI 模型的輸出。最後,也透過實驗呈現現今的 SOTA AI 模型在這個 Benchmark 上的表現仍然很差,但是 Human 卻有相當好的表現。