[論文介紹] Better & Faster Large Language Models via Multi-token Prediction

source: Pixabay
前言
Meta AI 在今年(2024)的 06/18 於 Meta Blog 上發布多個新的 AI 模型,其中一個我覺得特別有趣稱為「Multi-Token Prediction Model」。Meta 一直都是 AI Open-Sourced Community 中重要的貢獻者,這個模型的訓練參數當然也可以在 HuggingFace 中找到。實際上,闡述這個模型的論文早在今年 4 月就已經被上傳到 Arxiv 上,只不過在 Meta 正式宣佈 & 開源其模型之前似乎沒有得到太多關注。
在這篇文章中,我希望用很簡單、很快速的方式和大家分享這篇論文的內容,包含它想解決什麼問題、解法是如何被設計的,以及最後的實驗結果又是如何!
Multi-Token Prediction Model 背後的動機 & 想解決的問題
目前我們所見到的大型語言模型(LLM)幾乎 99% 都是屬於 Auto-Regressive Model。換句話說,不管在訓練或是推論時,這些模型都是在進行 Next-Token Prediction 的任務:基於第 1 個到第 t 個 Token 來預測第 t+1 個 Token。在訓練階段的 Loss Function 通常如下圖 Equation(1) 所示:
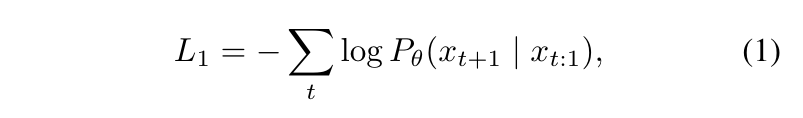
Next-Token Prediction Task 的 Loss Function
而本篇論文想解決的問題非常直覺:為什麼一定要一次預測一個 Token,而不一次多預測一些 Token 呢?
Multi-Token Prediction Model 的設計
既然想要一次預測多個 Token,那在訓練階段的 Loss Function 勢必要先進行修改,如下 Equation (2) 所示:
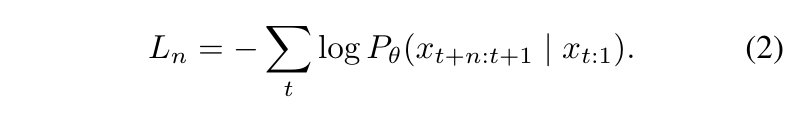
Multi-Token Prediction Model 的 Loss Function
可以發現跟原來唯一的差別就在於,原本是拿 1 個 Predicted Token 的機率分佈計算 1 次 Cross-Entropy Loss,現在是拿 n 個 Predicted Token 機率分佈計算 n 次 Cross-Entropy Loss,然後把這 n 個 Loss 加總在一起來對模型進行更新。
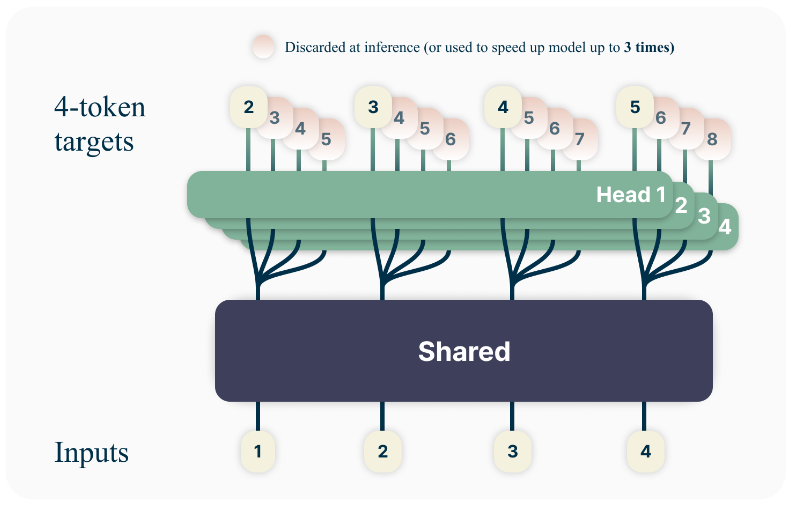
Multi-Token Prediction Model Architecture
除了 Loss Function 的修改,在模型的架構上(如上圖所示)主要是會透過一個 Shared Transformer Trunk(可以想成一個大家共用、唯一的 Encoder)得到一個 Hidden Representation 來象徵前面 t 個 Token 的資訊,再透過 n 個 Head 分別預測未來的 n 個 Token。
我們可以發現 Multi-Token Prediction Model 的架構相當好理解,但是實際在訓練時就會發現到:在 LLM 的 Forward Pass 過程中,最後得到的 Logit 的維度是遠大於中間運算過程的 Hidden Representation 的維度。因此,當今天要進行 Multi-Token Prediction 時,如果 n 個 Token 是同時被平行運算出來的,就會導致 GPU Memory 的使用量從 1 個 Logit 變成 n 個 Logit。這篇論文為了避免 GPU 使用量過多,將每一個 Token 的預測變成是 Sequential 的:
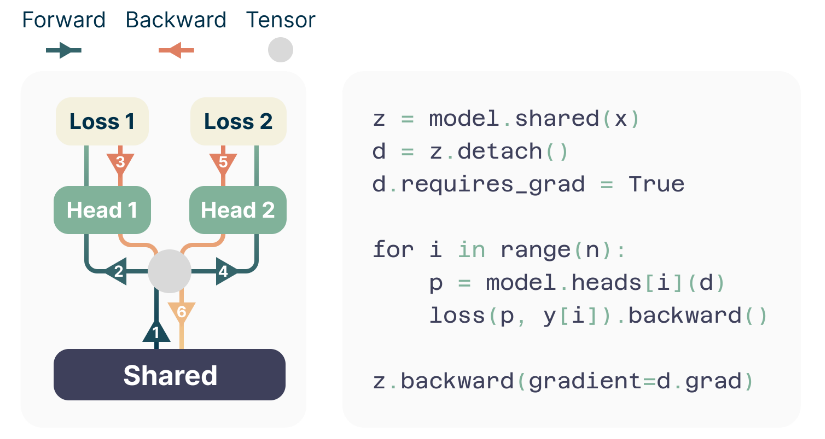
By performing the forward/backward on the heads in sequential order, we avoid materializing all unembedding layer gradients in memory simultaneously and reduce peak GPU memory usage.
如上圖左方所示,基於一個 Input Sequence,從 Shared Transformer Trunk 得到 Hidden Representation 後:
- 會先輸入到到 #1 Head,得到 #1 Predicted Token 和 Loss,然後透過這個 Loss 進行 Backward Pass 把 Gradient 先累積在 Hidden Representation
- 再輸入到 #2 Head,得到 #2 Predicted Token 和 Loss,然後透過這個 Loss 進行 Backward Pass 把 Gradient 先累積在 Hidden Representation
- 依此類推 N 個 Token
- 最後,再把累積在 Hidden Representation 的 Gradient 進行 Backward Pass 計算 Shared Transformer Trunk 中的 Weight 的 Gradient。
從上圖右方的 Pseudocode 也可以清楚地看到,Input Sequence (x) 輸入到 Shared Transformer Trunk 得到 Hidden Representation (z) 後,就透過 detach() 方法得到的 Tensor d。Tensor d 的數值和 Tensor z 是一樣的,但是透過 detach() 方法使得 Tensor d 離開了 Tensor z 所在的 Computation Graph。這樣帶來的效果是,當我們對於 Tensor d 之後的運算所得到的 Tensor 呼叫 backward() 時,Gradient 的計算最多就只會到 Tensor d,而不會再往前到 Tensor z、model.shared 或是 Tensor x。
具體來說,Pseudocode 下半的 For Loop 中,會把 Tensor d 進行一些運算後得到 Tensor p(就是其中一個 Head 的 Prediction),然後拿 Tensor p 和 Label 計算 Loss 並呼叫 backward()。這裡是關鍵,這時候只會計算「Tensor p」的 Gradient、「model.heads[i] 中的 Weight/Bias」的 Gradient 以及「Tensor d」的 Gradient。
為什麼不會繼續算「Tensor z」和「model.shared 的 Weight/Bias」的 Gradient 呢?因為透過 detach() 方法,Tensor d 已經和它們不在相同的 Computation Graph 上了!
此外,在 For Loop 中每一次的 Tensor d 都是相同的,代表其實每次從 Head Loss 計算得到的 Gradient 都會存在 Tensor d 中。在 PyTorch 中,預設會進行「梯度累積」,也就是 Tensor d 中所有的 Gradient 都會被加起來。
一直到 For Loop 結束之後,才手動的對 Tensor z 呼叫 backward(gradient=d.grad),並且使用累積在 Tensor d 的 Gradient 來計算 Tensor z 的 Gradient。(以及 Tensor z 之前 model.shared 的 Weight/Bias 的 Gradient)
你可以發現到,這樣 Sequential 運算每一個 Head 的做法,就是為了避免在:
- Forward Pass 時,所有 Head 的 Logit 一起同時被計算出來
- Backward Pass 時,所有 Head 的 Loss 一起同時計算整個模型的 Gradient
進而降低 GPU Memory 的用量。
在 Inference 時,當然就很彈性,可以僅保留 #1 Predicted Token 的 Head,就是進行一般的 Next-Token Prediction。當然也可以保留所有 Head,做到類似 Speculative Decoding 的概念。
備註:如果你對於 Neural Network 中參數的更新(Gradient 的計算)不理解的話,可以看看 Backpropagation 介紹一文,相信你一定會有所收穫的!
Multi-Token Prediction Model 的實驗結果
理解了 Multi-Token Prediction Model 的方法設計後,最後是實驗的介紹。為了節省讀者的時間,這裡僅對實驗結果做概述!
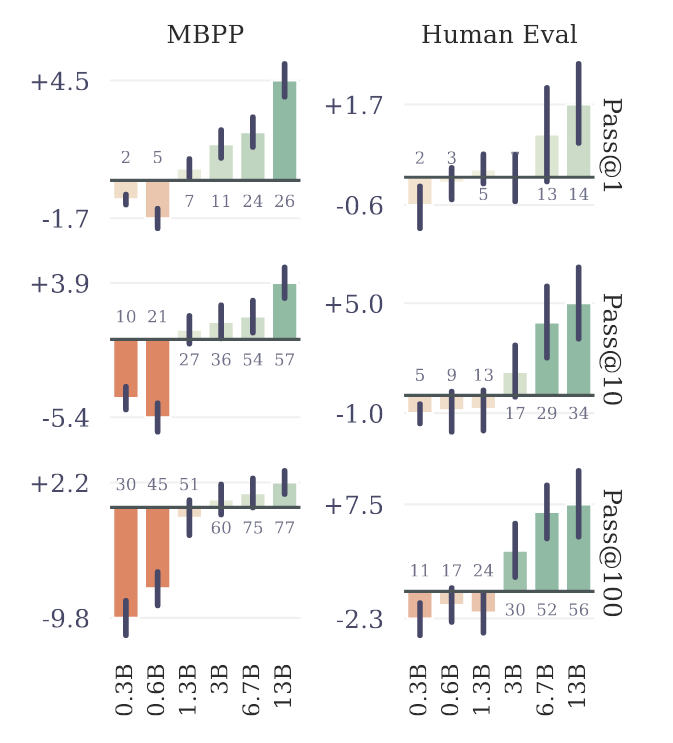
Results of n-token prediction models on MBPP by model size. We train models of six sizes in the range or 300M to 13B total parameters on code, and evaluate pass@1,10,100 on the MBPP and HumanEval benchmark with 1000 samples. Multi-token prediction models are worse than the baseline for small model sizes, but outperform the baseline at scale. Error bars are confidence intervals of 90% computed with bootstrapping over dataset samples.
首先,從上圖可以看到將 6 種不同 Size 的 Model 衡量在兩個 Benchmark(MBPP 和 HumanEval)時,小模型搭配 Multi-Token Prediction 的表現反而比較差。大模型則是普遍帶來更好的效果。作者也推測,這個原因可能是導致 Multi-Token Prediction 方法過去一直沒有熱門起來的原因。
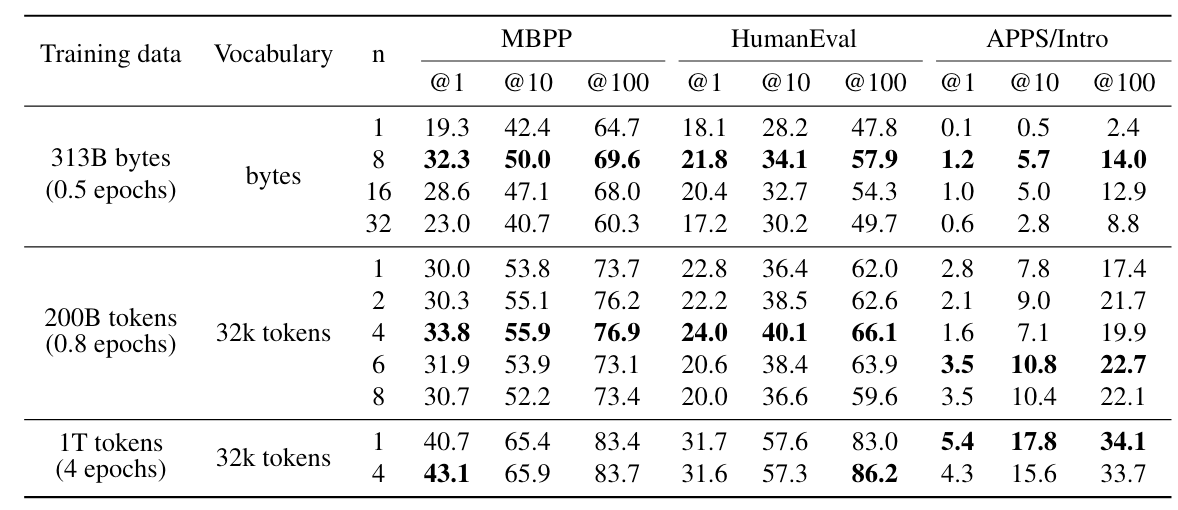
Multi-token prediction improves performance and unlocks efficient byte level training. We compare models with 7B parameters trained from scratch on 200B and on 314B bytes of code on the MBPP, HumanEval and APPS benchmarks. Multi-token prediction largely outperforms next token prediction on these settings.
作者透過實驗發現,在訓練一個 7B 的 Byte-Level Transformer 時(也就是這個 Transformer 預測的是下一個 Byte 而非下一個 Token),透過 Multi-Byte Prediction Pre-Training Task 會比 Next-Byte Pre-Training Prediction Task 帶來更好的表現。(如上表中的第一列所示)
此外,從上表中的第二列還可以發現在 Token-Level Transformer 上,4 個 Prediction Head 通常能帶來最好的結果;而在 Byte-Level Transformer上(上表中的第一列),8 個 Prediction Head 則比較好。可以發現 Prediction Head 的數量會和 Input Data Distribution 有關。然而大體上而言,Multi-Toke (Byte) Prediction 還是比 Next-Token (Byte) Prediction 來得好!
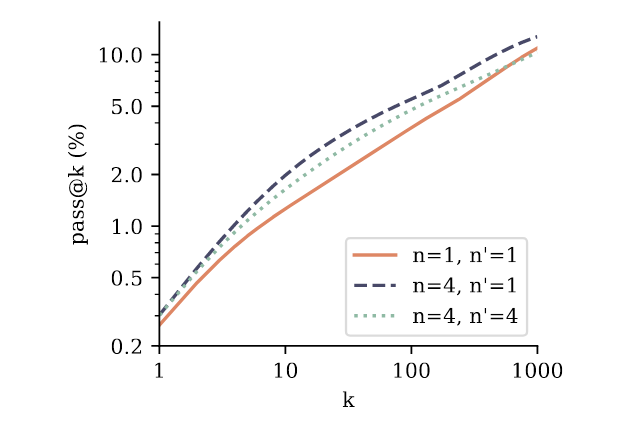
Comparison of finetuning performance on CodeContests. We finetune a 4-token prediction model on CodeContests (train split) using n′token prediction as training loss with n′ = 4 or n′ = 1, and compare to a finetuning of the next-token prediction baseline model (n = n′ = 1). We observe that both ways of finetuning the 4-token prediction model outperform the next-token prediction baseline. Intriguingly, using next-token prediction finetuning on top of the 4-token prediction model appears to be the best method overall.
在上圖中,作者將一個 7B Model 用兩種方式 Pre-train:Next-Token Prediction (橘色實線, n=1) 與 4-Token Prediction (黑色和綠色虛線, n=4),並將模型進行 Fine-tune。在 Fine-tune 時有 Next-Token (n’=1) 以及 4-Token (n’=4)。可以發現不管 k 是多少,黑色虛線和綠色虛線的表現都超越橘色實線,說明在 Pre-training 階段使用 Multi-token Task 的有效性。
結語
本篇文章中我們介紹了 Meta 最新發表以及開源的 Multi-Token Prediction Model,有別於目前絕大多數的 LLM 都是以 Next-Token Prediction 的方式進行訓練,Meta 發現對於 3B 以上的 LLM 透過 Multi-Token Prediction Task 來訓練,反而能夠提升模型的表現。此外,在本文中我們也詳細介紹了 Multi-Token Prediction Model 的架構,以及如何透過 Sequential Prediction 的方式來減少 GPU Memory 的用量。最後,如果你對於本文有任何建議的話,也歡迎在底下留言!