機器學習的模型、訓練與推論
前言 & 概述
在開始閱讀本篇文章之前,必須先了解 Machine Learning 的概念。可以先閱讀前一篇文章,對 Machine Learning 有基本的認知。在本篇文章中,將會介紹 Machine Learning 中重要的三個元素的概念:模型 (Model)、模型的訓練演算法 (Model Training Algorithm) 以及模型的推論演算法 (Model Inference Algorithm)。
模型、訓練與推論的概念
初次學習 Machine Learning 的夥伴,勢必對於 Machine Learning 中許多專業術語感到恐懼,因此這邊先以生活化的例子比喻模型、訓練與推論的概念。
實際上,此三者的關係就像是「手拉坯」的過程!「模型」就像是一塊未經過雕塑的「黏土」。「訓練」則是透過我們的雙手去雕塑「黏土」的過程。依照我們目標的不同,我們會採不同的方式將黏土雕塑成不同形狀的容器。因此,機器學習中也有很多不同的訓練演算法。至於,「推論」則像是已經雕塑好的容器要進行「測試」。我們試著將容器承裝液體,確認容器安全無虞。

Machine Learning 中主要分為這三個步驟 [source: Udacity]
機器學習模型是什麼
初步了解模型的概念後,我們換個角度以數學的形式理解模型的意義。實際上,模型可以想成一個「函式」(Function)。沒錯,就是在國中時我們所學到的那個「函式」(y = f(x))。函式的概念很單純:輸入一個東西,輸出另外一個東西。
為了解決某些問題,我們需要不同的函式。例如,下圖是一個函式:輸入一張圖片,輸出這張圖片的類別。
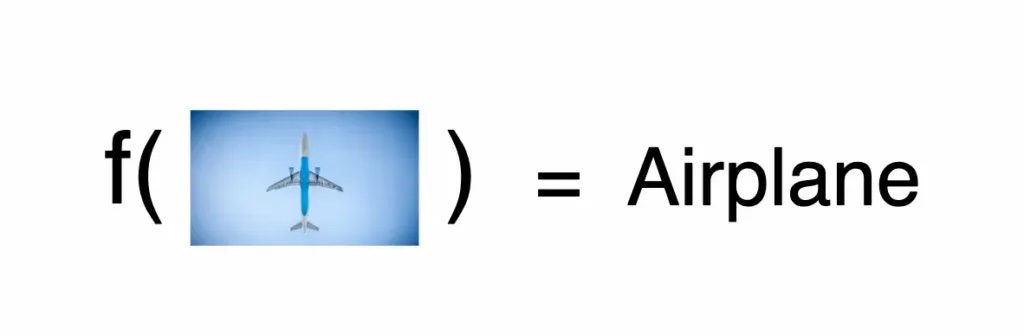
機器學習中的模型就是一個複雜的函式
又或者是下面這個函式:輸入房子的坪數,輸出這間房子的價格。
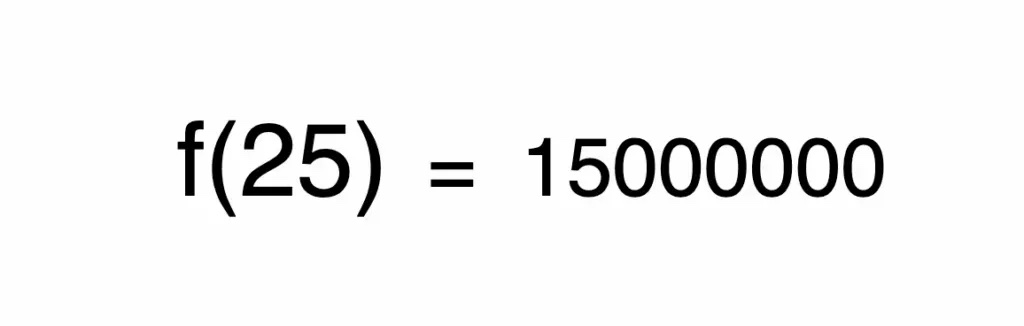
機器學習中的模型就像是一個函式
既然已經了解模型其實就是函式,函式內當然有許多的參數。例如,下方的函式中就包含了 w1、w2 與 w3 三個參數。
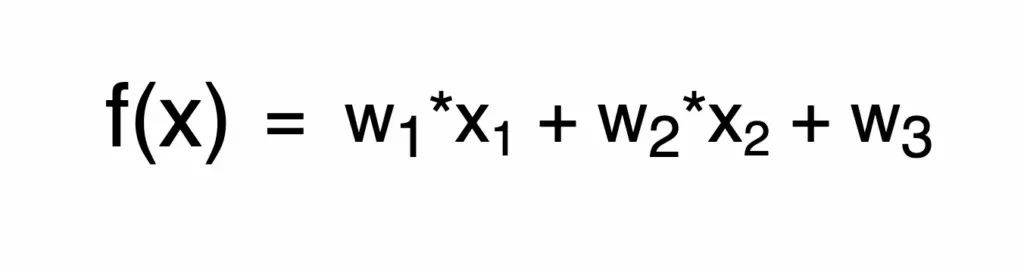
機器學習中的模型就像是一個複雜的函式
在上述的例子中,為了能夠訓練一個模型 (函式) 在輸入房子的坪數後,能夠預測該房子的價格,我們會準備很多樣本 (Sample) 給模型學習。每一個樣本中都包含兩個數值:(坪數 => 價格)。
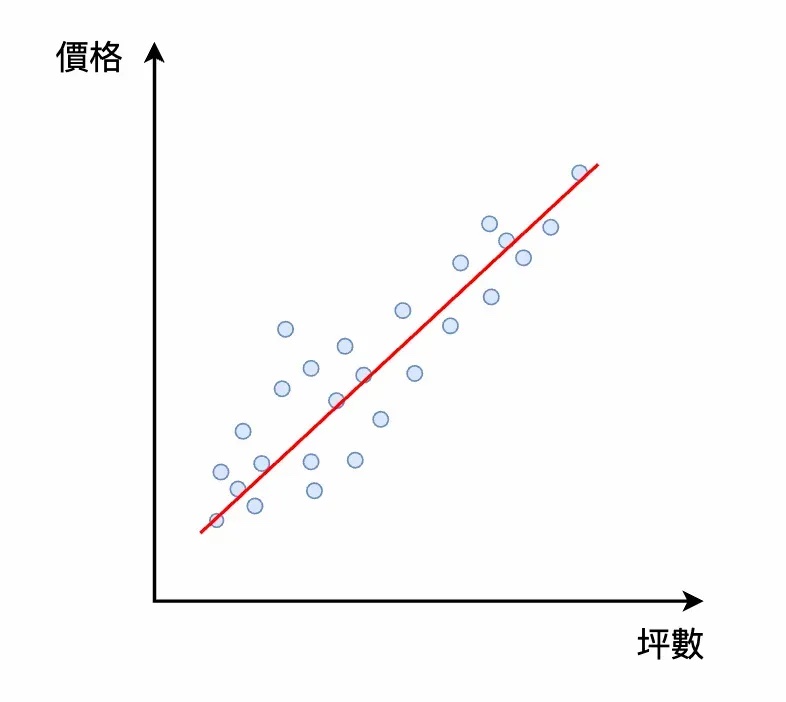
紅色的線就是我們希望學到的模型
如果將很多的 (坪數 => 價格) 的樣本,通通畫在一個二維平面上,如同上方的藍色點點。我們希望模型透過這些藍色點點,可以自動調整自己的參數,使得輸入一個「坪數」後,能夠輸出一個準確的「價格」。也就是說,「紅色的線」就是我們希望得到的模型。
模型的訓練是什麼
我們已經了解模型其實就是函式,透過我們提供的樣本,模型學習調整自己的參數,最終變成我們想要的模型。「模型學習調整自己的參數」的過程,就是在訓練模型。
訓練模型的過程是一個重複的流程。這個流程中包含了兩個行為:
- 找到模型中參數調整的方向與大小
- 對參數進行調整
訓練模型的過程就是不斷的重複這兩個行為,直到模型的輸出達到我們滿意的水準。
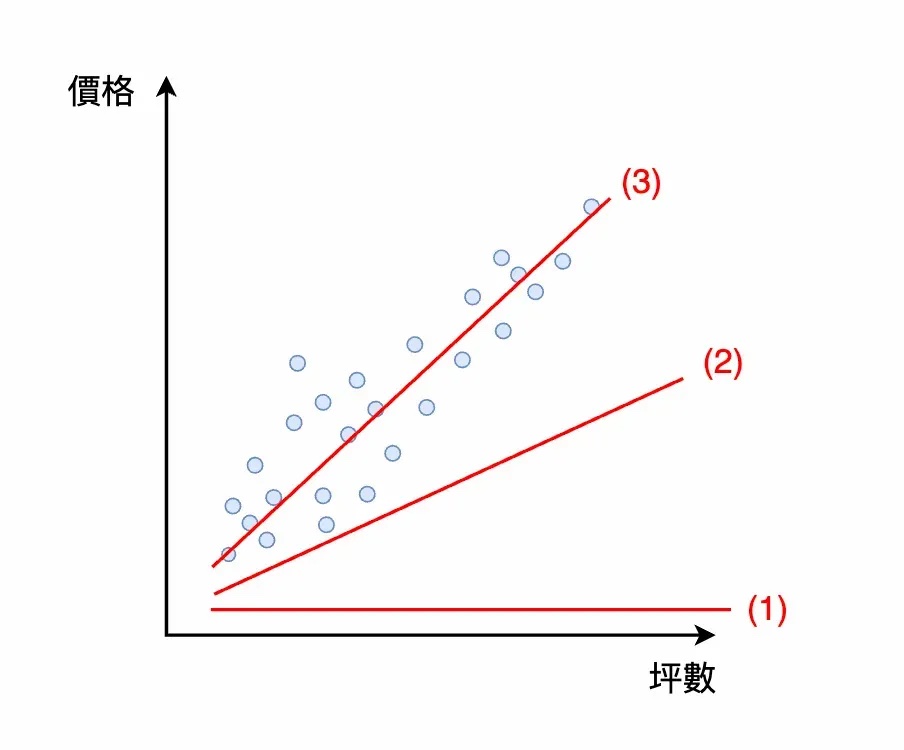
模型從 (1) 慢慢變成 (3)
以輸入「坪數」輸出「價格」的模型為例。一開始的模型可能是一條水平線 (1),無論我們輸入什麼坪數,始終是相同的價格。模型調整一次參數後,變成稍微斜一點的直線 (2),隨著輸入的坪數愈大,模型輸出的價格也跟著愈大,模型的輸出漸漸變好。隨著模型調整愈多次參數後,輸出的價格愈來愈準確,最終變成我們想要的模型 (3)。
模型的推論是什麼
當模型經過訓練後,模型內部的參數已經經過了多次的調整,根據不同的輸入,模型的輸出我們也相當滿意。接著,就是模型的推論階段。所謂的推論階段其實就是正式開始「使用模型」。
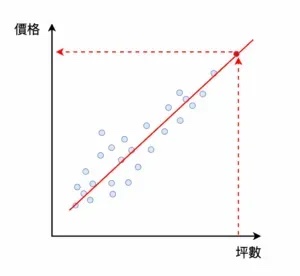
輸入房子的坪數,模型輸出預測的價格
在「輸入坪數,輸出價格」的例子中,模型在訓練階段看過了這些藍色的樣本後,並經過多次的調整參數後,成為現在的模型 (紅色線)。在未來,當我們得到一個只有坪數沒有價格的樣本時,就能透過我們已經訓練過的模型,進行價格的預測 (紅色點點)。
結語
在本篇文章中,對 Machine Learning 中的模型 (Model)、模型訓練 (Model Training) 與模型推論 (Model Inference) 有了進一步的認識!在下一篇文章中,將會介紹當我們遇到一個需要透過 Machine Learning 技術解決的問題時,應該依循哪些步驟來將問題解決。