Kaggle 競賽教學 —— CIFAR-10 Object Recognition in Images

source: Pixabay
前言
許多剛接觸機器學習的初學者,想透過 Kaggle 競賽來提升自己的機器學習實力,然而卻又不知道應該從哪一場競賽開始。本篇文章推薦初學者可以從 CIFAR-10 – Object Recognition in Images 競賽開始,帶領初學者參與人生中第一場 Kaggle 競賽。
需要注意的是,本篇文章的實作部分使用的是 PyTorch 套件,若你不曾接觸過 PyTorch 務必參考官方教學。若你是 TensorFlow 或 Keras 的使用者,相信你也可以輕易看懂 PyTorch 的程式碼。
本篇文章的程式碼收錄於筆者的 GitHub 中。
競賽簡介
接著,讓我們簡單了解 CIFAR-10 Object Recognition in Images 競賽是什麼。CIFAR-10 是電腦視覺領域中廣為人知的資料集,很多機器學習的初學者都會使用這個資料集練功。CIFAR-10 中包含了 60000 張 32 × 32 的彩色圖片,每張圖片裡面都包含有一個物件,這個物件屬於 10 個類別中的其中一個類別。整體來說,每個類別各有 1000 張圖片。
在此競賽的資料集中,主辦方已經事先將CIFAR-10 資料集拆分為訓練資料集以及測試資料集,訓練資料集包含 50000 張圖片、測試資料集包含 10000 張圖片。每張圖片都是下列 10 個類別中的其中一個類別:
- airplane
- automobile
- bird
- cat
- deer
- dog
- frog
- horse
- ship
- truck
我們的目標就是建立一個模型,利用 50000 張訓練圖片訓練後,能夠在剩下的 10000 張測試圖片有精準的預測結果。主辦方為了避免參賽者作弊(手動標記測試資料集中的 10000 張圖片),在測試資料集中塞入額外 290000 張圖片,讓參賽者不知道其中哪些圖片才是真正的測試資料集。
從競賽簡介我們可以知道這是一個「圖像分類」的任務,而且每張圖片只會有一個類別。此外,整體類別的數目也不多(10 個),每個類別所包含的訓練資料也非常一致(不會產生訓練資料不平衡的問題),因此 CIFAR-10 – Object Recognition in Images 算是一個相當適合初學者參與的競賽。
實作細節 01 —— 載入函式庫
了解競賽的目標之後,我們就可以開始實作這個專案。首先,載入必要的函式庫:
# model import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import models # dataset import math import glob import pandas as pd from PIL import Image from sklearn.model_selection import train_test_split from torchvision import transforms from torch.utils.data import Dataset, Subset, DataLoader import matplotlib.pyplot as plt # save result import pickle
接著,讓 PyTorch 抓取機器上的 GPU 資源:
torch.manual_seed(2022)
try:
device = torch.device("mps")
except:
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
為了能夠抓取 Apple Silicon GPU,必須指定 MPS Device。
實作細節 02 —— 載入資料集
因為筆者是在 Colab 中完成此專案,因此會先將整個專案都上傳到 Google Drive 後,再將 Drive Mount 到 Colab 上,並解壓縮訓練資料與測試資料。
from google.colab import drive
drive.mount('/gdrive')
!unzip "/gdrive/MyDrive/Colab Notebooks/Kaggle/CIFAR-10 - Object Recognition in Images/cifar-10.zip"
!7z x train.7z
!7z x test.7z
解壓縮完成之後,我們將所有訓練資料的路徑存下來:
img_names = glob.glob(f"cifar-10/train/*.png")
實作細節 03 —— 圖像資料前處理
在將圖像輸入到模型之前,我們通常會對圖像進行一些前處理,讓模型能夠更好訓練、學得更好。在此專案中,我們僅針對圖像進行最基本的前處理 —— 正規化。進行正規化時,我們需要選擇一組平均(Mean)與標準差(Standard Deviation),因此我們計算訓練資料集中「每個 Channel」(RGB 圖片有 3 個 Channel)的 Mean 與 Standard Deviation。
我們首先讀取每一張圖片,並將圖片轉為 PyTorch 中的 Tensor:
imgs = [] transform = transforms.Compose([ transforms.ToTensor(), ]) for img in img_names: img = Image.open(img) imgs.append(transform(img))
接著,計算每一個 Channel 的 Mean 與 Standard Deviation:
imgs = torch.stack(imgs, dim=3)
channel_mean = imgs.view(3, -1).mean(dim=1)
channel_std = imgs.view(3, -1).std(dim=1)
print(f"channel mean: {channel_mean}")
print(f"channel std: {channel_std}")
並透過 PyTorch 中 transforms.Compose( ) 函式將多個資料前處理的步驟包在一起:
transform_fn = transforms.Compose([ transforms.ToTensor(), transforms.Normalize( mean=channel_mean, std=channel_std ) ])
最後定義一個 PyTorch Dataset:
class CIFARDataset(Dataset):
def __init__(self, img_path, transform, csv_path):
self.csv_path = csv_path
self.transform = transform
if csv_path:
self.img_names = glob.glob(f"{img_path}/*.png")
else:
self.img_names = [f"{img_path}/{idx}.png" for idx in range(1, 300001)]
if csv_path:
label_df = pd.read_csv(csv_path)
self.label_idx2name = label_df['label'].unique()
self.label_name2idx = {}
for i in range(len(self.label_idx2name)):
self.label_name2idx[self.label_idx2name[i]] = i
self.img2label = {}
for_, row in label_df.iterrows():
self.img2label[f"{img_path}/{row['id']}.png"] = self.label_name2idx[row['label']]
def __len__(self):
return len(self.img_names)
def __getitem__(self, index):
img = self.img_names[index]
if self.csv_path:
label = self.img2label[img]
label = torch.tensor(label)
else:
label = -1
img = Image.open(img)
img = self.transform(img)
return (img, label)
dataset = CIFARDataset(
img_path="cifar-10/train",
transform=transform_fn,
csv_path="cifar-10/trainLabels.csv",
)
為了評估模型的效能,我們會將訓練資料集再拆分為 Training 與 Validation 兩部分:
indexes = list(range(len(dataset)))
train_indexes, valid_indexes = train_test_split(indexes, test_size=0.2)
train_dataset = Subset(dataset, train_indexes)
valid_dataset = Subset(dataset, valid_indexes)
print(f"number of samples in train_dataset: {len(train_dataset)}")
print(f"number of samples in valid_dataset: {len(valid_dataset)}")
並分別建立 PyTorch DataLoader:
train_dataloader = DataLoader( train_dataset, batch_size=32, shuffle=True ) valid_dataloader = DataLoader( valid_dataset, batch_size=32, shuffle=True )
在 PyTorch 中定義自己的 Dataset 與 DataLoader 是常見的事情,如果你對此不熟悉可以參考官方教學。
透過 DataLoader,我們可以試著讀取一個 Batch 的 Data,並顯示其中幾張圖片。在顯示圖片時,記得要將正規化後的圖片還原回來。此外,因為 Matplotlib 在顯示圖片時,預設是將圖片的「色彩維度」放在最後一個,因此透過 permute( ) 函式更改為度的順序:
def show_samples(batch_img, batch_label=None, num_samples=16):
sample_idx = 0
total_col = 4
total_row = math.ceil(num_samples / 4)
col_idx = 0
row_idx = 0
fig, axs = plt.subplots(total_row, total_col, figsize=(15, 15))
while sample_idx < num_samples:
img = batch_img[sample_idx]
img = img.view(3, -1) * channel_std.view(3, -1) + channel_mean.view(3, -1)
img = img.view(3, 224, 224)
img = img.permute(1, 2, 0)
axs[row_idx, col_idx].imshow(img)
if batch_label != None:
axs[row_idx, col_idx].set_title(dataset.label_idx2name[(batch_label[sample_idx])])
sample_idx += 1
col_idx += 1
if col_idx == 4:
col_idx = 0
row_idx += 1
batch_img, batch_label = next(iter(train_dataloader))
show_samples(batch_img, batch_label, 16)
實作細節 04 —— 模型建立(VallinaCNN)
一開始,我們先利用最基本、最原始的模型來處理圖像分類的任務。我們利用基本的 Convolution Layer 建立了 VallinaCNN 模型:
class VallinaCNN(nn.Module):
def __init__(self):
super(VallinaCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1)
self.linear1 = nn.Linear(64*8*8, 10)
def forward(self, inp):
x = F.relu(self.conv1(inp))
x = F.max_pool2d(x, (2, 2))
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, (2, 2))
x = F.relu(self.conv3(x))
x = torch.flatten(x, 1)
out = self.linear1(x)
return out
net = VallinaCNN()
net.to(device)
print(f"number of paramaters: {sum([param.numel() for param in net.parameters() if param.requires_grad])}")
實作細節 05 —— Loss Function 與 Optimizer
因為是多個類別的分類問題,因此我們選擇 CrossEntropyLoss( ) 作為 Loss Function,並使用 SGD 來調整模型中的參數:
criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.005)
實作細節 06 —— Training & Validation Loop
在 Training 與 Validation Loop 中,每一次都會透過 DataLoader 從 Dataset 讀取一個 Batch 的資料,並將該 Batch 資料輸到模型中。在 train( ) 中,我們會透過 Optimizer 更新模型中的參數;在 validate( ) 中,我們則只有單純計算模型的 Accuracy 與 Loss:
def get_accuracy(output, label):
output = output.to("cpu")
label = label.to("cpu")
sm = F.softmax(output, dim=1)
_, index = torch.max(sm, dim=1)
return torch.sum((label == index)) / label.size()[0]
def train(model, dataloader):
model.train()
running_loss = 0.0
total_loss = 0.0
running_acc = 0.0
total_acc = 0.0
for batch_idx, (batch_img, batch_label) in enumerate(dataloader):
batch_img = batch_img.to(device)
batch_label = batch_label.to(device)
optimizer.zero_grad()
output = net(batch_img)
loss = criterion(output, batch_label)
loss.backward()
optimizer.step()
running_loss += loss.item()
total_loss += loss.item()
acc = get_accuracy(output, batch_label)
running_acc += acc
total_acc += acc
if batch_idx % 500 == 0 and batch_idx != 0:
print(f"[step: {batch_idx:4d}] loss: {running_loss / 500:.3f}")
running_loss = 0.0
running_acc = 0.0
return total_loss / len(dataloader), total_acc / len(dataloader)
def validate(model, dataloader):
model.eval()
total_loss = 0.0
total_acc = 0.0
for batch_idx, (batch_img, batch_label) in enumerate(dataloader):
batch_img = batch_img.to(device)
batch_label = batch_label.to(device)
# optimizer.zero_grad()
output = net(batch_img)
loss = criterion(output, batch_label)
# loss.backward()
# optimizer.step()
total_loss += loss.item()
acc = get_accuracy(output, batch_label)
total_acc += acc
return total_loss / len(dataloader), total_acc / len(dataloader)
實作細節 07 —— 開始訓練模型
EPOCHS = 20
train_history = []
valid_history = []
for epoch in range(EPOCHS):
train_loss, train_acc = train(net, train_dataloader)
valid_loss, valid_acc = validate(net, valid_dataloader)
print(f"Epoch: {epoch:2d}, training loss: {train_loss:.3f}, training acc: {train_acc:.3f} validation loss: {valid_loss:.3f}, validation acc: {valid_acc:.3f}")
train_history.append(train_loss)
valid_history.append(valid_loss)
if valid_loss <= min(valid_history):
torch.save(net.state_dict(), "net.pt")
實作細節 08 —— 模型訓練結果(VallinaCNN)
當模型訓練完之後,我們可以分析模型 Training Loss 與 Validation Loss 的變化,來了解模型的訓練結果。
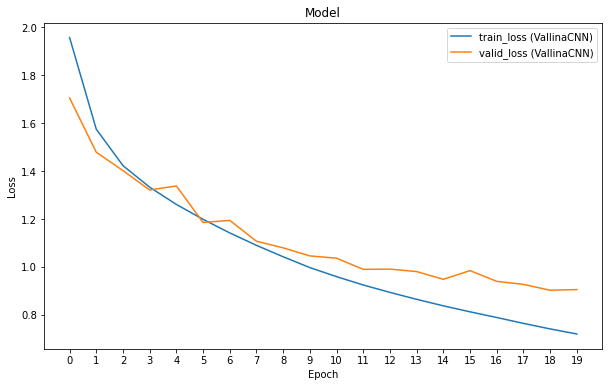
VallinaCNN 的訓練結果
上圖呈現的是 VallinaCNN 的訓練結果。從圖中可以發現一開始 Training Loss 與 Validation Loss 不斷的下降,然而從第 8 個 Epoch 開始,Validation Loss 下降的速率開始減慢。到了第 19 個 Epoch 時,Validation Loss 與 Training Loss 已經有一段落差。這是在訓練 Neural Network 時常遇見的問題 —— Overfitting。
實作細節 09 —— 在模型中加入 Dropout(CNNDropout)
減緩模型 Overfitting 的方法有很多,最簡單的一項可能是在模型中加入 Dropout Layer:
class CNNDropout(nn.Module):
def __init__(self):
super(CNNDropout, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, padding=1)
self.conv1_dropout = nn.Dropout(p=0.4)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, padding=1)
self.conv2_dropout = nn.Dropout(p=0.4)
self.conv3 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1)
self.linear1 = nn.Linear(64*8*8, 10)
def forward(self, inp):
x = F.relu(self.conv1(inp))
x = F.max_pool2d(x, (2, 2))
x = self.conv1_dropout(x)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, (2, 2))
x = self.conv2_dropout(x)
x = F.relu(self.conv3(x))
x = torch.flatten(x, 1)
out = self.linear1(x)
return out
CNNDropout 與 VallinaCNN 類似,只不過在 MaxPooling 的輸出再經過一層 Dropout。同樣將模型訓練 20 個 Epoch 後,我們將其訓練結果與原來的 VallinaCNN 比較:
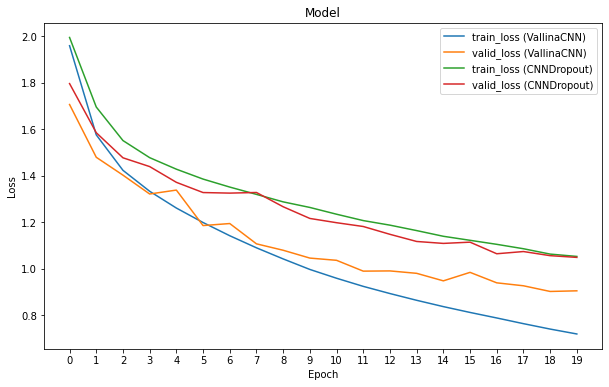
在 Convolution Neural Network 中加入 Dropout
我們可以發現原來的 Overfitting 問題確實減緩了,也就是說即使來到了第 19 個 Epoch,Validation Loss 仍然與 Training Loss 繼續下降。然而,和未加入 Dropout 的 VallinaCNN 比較,DropoutCNN 的 Training Loss 與 Validation Loss 仍然高出許多。
實作細節 09 —— 以 BatchNorm 取代 Dropout(CNNBatchNorm)
實際上,我們經常會利用 BatchNorm 取代 Dropout,BatchNorm 除了有減緩 Overfitting 的效果,也能夠加速模型的訓練:
class CNNBatchNorm(nn.Module):
def __init__(self):
super(CNNBatchNorm, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, padding=1)
self.conv1_bn = nn.BatchNorm2d(num_features=16)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, padding=1)
self.conv2_bn = nn.BatchNorm2d(num_features=32)
self.conv3 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1)
self.conv3_bn = nn.BatchNorm2d(num_features=64)
self.linear1 = nn.Linear(64*8*8, 10)
def forward(self, inp):
x = self.conv1(inp)
x = self.conv1_bn(x)
x = F.relu(x)
x = F.max_pool2d(x, (2, 2))
x = self.conv2(x)
x = self.conv2_bn(x)
x = F.relu(x)
x = F.max_pool2d(x, (2, 2))
x = self.conv3(x)
x = self.conv3_bn(x)
x = F.relu(x)
x = torch.flatten(x, 1)
out = self.linear1(x)
return out
同樣將模型訓練 20 個 Epoch 後,我們將其訓練結果與 VallinaCNN、CNNDropout 比較:
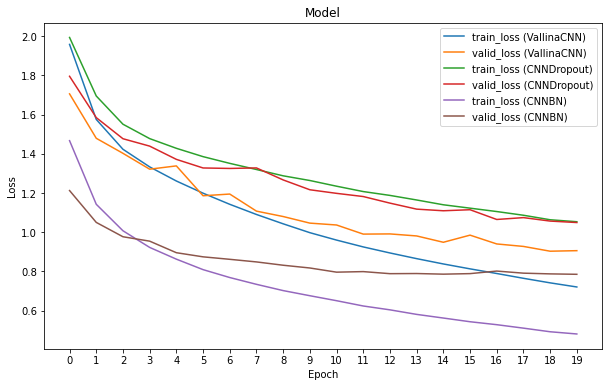
在 Convolution Neural Network 中加入 BatchNorm
從上圖可以發現,同樣訓練 20 個 Epoch,CNNBatchNorm 的 Training Loss 與 Validation Loss 明顯低於 VallinaCNN 與 CNNDropout。CNNBatchNorm 也大幅縮短了訓練所需的時間,只訓練 4 個 Epoch,其 Training Loss 與 Validation Loss 也已經低於另外兩個模型。
實作細節 10 —— 利用 Transfer Learning 提高模型準確度(PretrainDenseNet)
到目前為止,我們已經試過了三種不同的模型:VallinaCNN、CNNDropout 與 CNNBatchNorm,我們也觀察到不同技巧對模型效能的影響。回歸主題,我們應該如何在這一個 Kaggle Competition 中訓練出一個好的模型呢?我們可以使用 Transfer Learning 的技巧!
在 Transfer Learning 中,我們會針對已經訓練於大量資料的模型進行 Fine-Tune。在此專案中,我們從 PyTorch TorchVision Models 選擇 DenseNet,並載入模型訓練在 ImageNet 資料集的參數。因為該模型是訓練在 ImageNet 資料集,需要預測的圖像類別有 1000 個,但是因為我們只需要預測 10 個,因此我們將模型的 Classifier Head 部分進行修改:
class PretrainDenseNet(nn.Module):
def __init__(self):
super(PretrainDenseNet, self).__init__()
model = models.densenet121(pretrained=True)
num_classifier_feature = model.classifier.in_features
model.classifier = nn.Sequential(
nn.Linear(num_classifier_feature, 256),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, 10)
)
self.model = model
# for param in self.model.named_parameters():
# if 'features' in param[0]:
# param[1].requires_grad = False
def forward(self, x):
return self.model(x)
在 Transfer Learning 中,我們通常會將模型主體的參數固定住,只需要重新訓練新的 Classifier Head 的部分。然而在此專案中,我們嘗試讓整個模型都訓練,也能有不錯的表現:
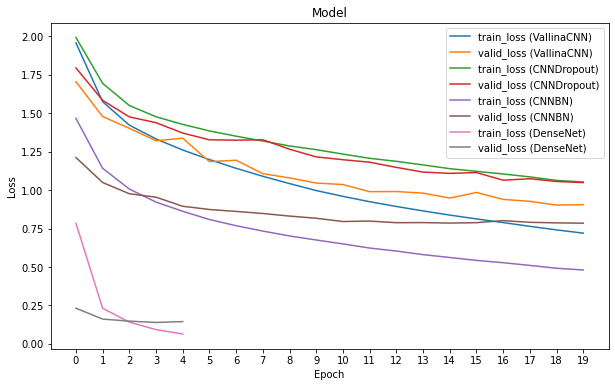
使用 Transfer Learning 訓練 DenseNet
由上圖可以發現,我們只對模型訓練 5 個 Epoch,其 Training Loss 與 Validation Loss 就已經趨近於 0。
結語
在本篇文章中,我們介紹了 Kaggle 上的 CIFAR-10 – Object Recognition in Images 競賽,是一個非常適合初學者參與的競賽。此外,我們也簡單比較了原始 CNN、Dropout 與 BatchNorm 對模型效能的影響。最後,我們介紹到 Transfer Learning 的技巧,透過 Transfer Learning 能夠讓我們在硬體資源、訓練資料量不足的條件下,仍然能夠訓練出高效能的模型。
在本篇文章中,我們沒有提到如何生成 Kaggle 指定的 submission.csv,這部分的程式碼可以參考筆者的 GitHub。