開始深度學習之前,先了解什麼是「感知器」(Perceptron)
source: Pixabay
前言
自 2012 年 AlexNet 在 ILSVRC 贏得冠軍後,深度學習 (Deep Learning) 的概念逐漸成為顯學,人工神經網路 (Artificial Neural Network) 開始應用在傳統演算法無法解決的問題上,包含電腦視覺 (Computer Vision) 與自然語言處理 (Natural Language Processing)。
在開始探索深度學習的核心觀念之前,我們先從神經網路的始祖「感知器」(Perceptron) 開始學起,理解感知器的概念,能夠幫助我們奠定深度學習的理論基礎。
什麼是感知器 (Perceptron)
感知器 (Perceptron) 是 Frank Rosenblatt 基於生物中神經細胞的概念,於 1957 年發明的「人造神經元」(Artificial Neuron),是一種簡單的「二元線性分類器」。需要特別注意的是,在現代 (近幾年) 發表的神經網路 (Neural Network) 模型中,所使用的神經元並不是 Perceptron,而是另外一種神經元,稱為「Sigmoid Neuron」。關於 Sigmoid Neuron 的觀念,我們將會在下一篇文章介紹。了為了完全解 Sigmoid Neuron 的原理,我們必須先掌握 Perceptron 的精髓!
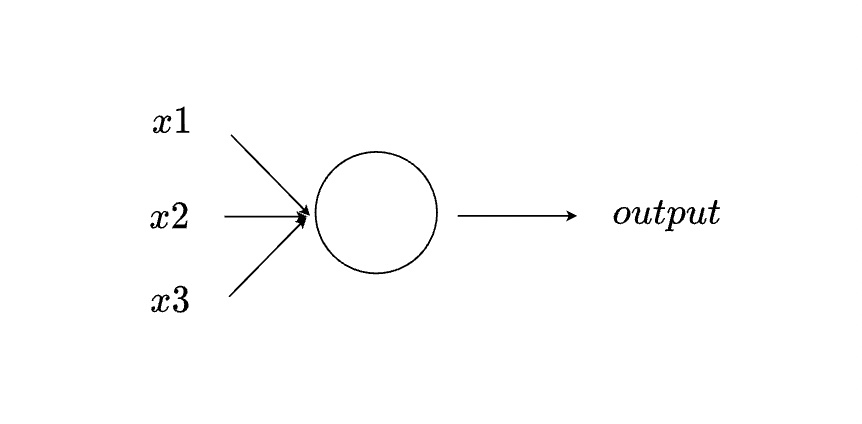
感知器 (Perceptron) 接收「多個」二元數值並輸出「一個」二元數值
如上圖所示,Perceptron 能夠接收多個數值,並且輸出一個數值。其中 x1、x2、x3 與 output 皆為「二元數值」,也就是他們的數值不是 0 就是 1。
Rosenblatt 也提出一個簡單的方法來計算 Perceptron 的 output:將每一個輸入 x 與不同的參數 w 相乘,並計算他們的總和。如果總和大於某一個門檻 (threshold) 即輸出 1,否則輸出 0。w 與 threshold 都是這一個 Perceptron 的參數。
我們也可以利用數學算式理解 Perceptron 的原理:
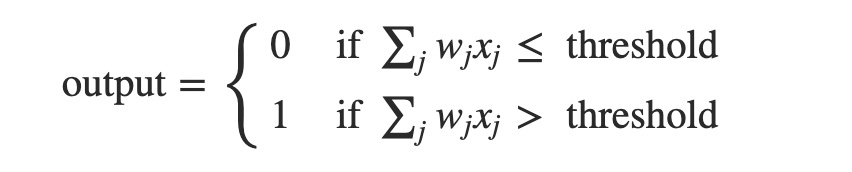
以數學形式表示 Perceptron 的運作 [source: Neural Networks and Deep Learning]
用簡單的例子理解 Perceptron 的運作
Perceptron 會依據每個輸入的「重要性」給予其不同的權重
我們可以用生活中的例子,更直觀的理解 Perceptron 的運作方式。如上圖所示,我們可以將 x1、x2、x3 想成不同的「因素」,output 則視為最終的「決定」。舉例來說,假設這個週末你的朋友約你一起出去玩,你很猶豫要不要去,因為你還在考慮以下三件事情:
- 週末是不是晴天 (討厭雨天)
- 出去玩的成員中有沒有異性 (不想要一群臭宅宅)
- 能不能搭別人的汽車過去 (不想要自己搭火車)
我們可以將這三個考慮的「因素」當作上面 Perceptron 的 x1、x2、x3 ,將最後「決定」要不要去當作 output。舉例來說,如果週末晴天,則 x1 為 1;如果是雨天,則 x1 為 0。如果出去玩的成員中有異性,則 x2 為 1;如都是一群肥宅,則 x2 為 0。x3 也是相同的概念。
因為你對這三個因素有不同的「重視程度」,因此在 Perceptron 中 x1、x2、x3 也會有相對應的參數 w。舉例來說,假設你真的非常在意「出去玩的成員中有沒有異性」,只要出去玩的成員中有異性,即是週末註定下大雨,注定不能搭別人的車子,你仍會決定要去,則 w2 的數值會大於 w1 與 w3。
綜合上述的描述,你將三項因素的重視程度做了排序:「出去玩的成員中有沒有異性」>「週末會不會下雨」=「能不能搭別人的汽車過去」,則 Perceptron 的 w 數值可能為 w1 = 3、w2 = 6、w3 = 3。
Perceptron 中的參數除了 w 外還有 threshold,在此例子中我們將 threshold 設為 5。如此一來,如果「出去玩的成員中『有』異性」(x2 為 1);「週末『會』下雨」(x1 為 0);「『不能』搭別人的汽車過去」(x3 為 0),最後的決定 (output) 仍然會是 1。如果我們將 threshold 設為一個很大的數字 (例如:100),那麼即使三個因素都符合你的預期,你最終也會決定不和朋友出去玩。
由這個例子,我們可以發現透過調整 Perceptron 中的 w,可以給予因素不同的重視程度,也就是給予輸入不同的權重;調整 Perceptron 中的 threshold,則象徵你有多想做出正向的決定,也就是輸出多有可能為 1。
多個 Perceptron 形成一個 Network
在上面的例子中,我們可以發現到一個 Perceptron 能夠處理的問題的複雜度其實有限,為了解決現實生活中更複雜的問題,我們可以使用更多的 Perceptron,形成一個神經網路 (Neural Network)。
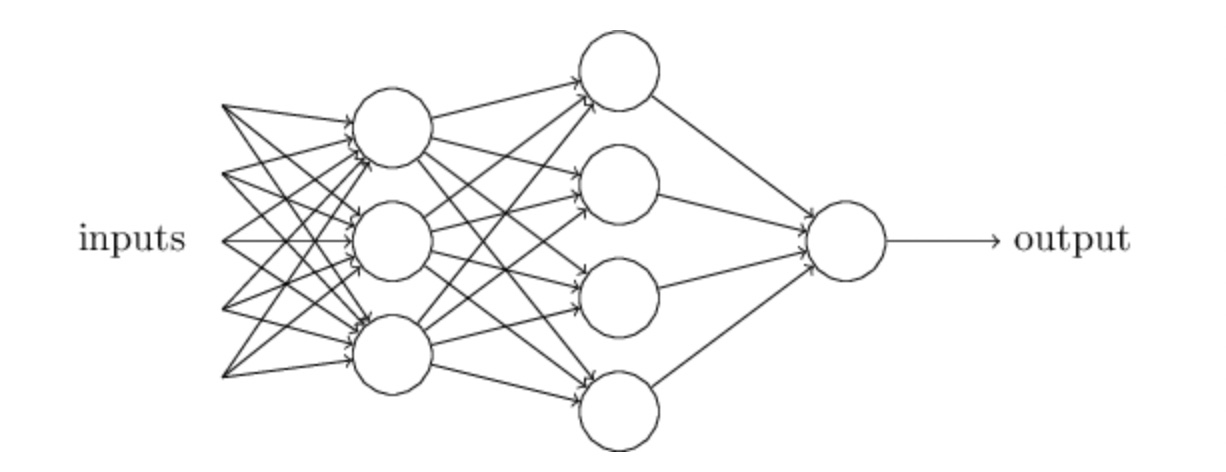
多個 Perceptron 形成一個 Neural Network [source: Neural Networks and Deep Learning]
如上圖所示,我們將 8 個 Perceptron 組織成一個 Neural Network。在 Neural Network 的第 1 層有 3 個 Neuron,每一個 Neuron 都會將每一個輸入乘以一個權重 (w) 並將其總和在一起,根據最終的總和是否大於門檻 (threshold) 輸出 1 或 0。因此,這一層神經網路 (有三個 Neuron) 相當於做了三種不同的決定。下一層的 Neuron 又會根據前一層的輸出 (決定) 進行決策。如此一來,愈後層的神經元所做的決定,會比前面層的更複雜、更抽象。因此,為了有效處理現實生活中困難的問題,我們經常會搭建出超級多層的神經網路。
你可能會覺得奇怪,因為在一開始介紹 Perceptron 時,明明只會有一個 output,但是為什麼在上圖的 Neural Network 中 Perceptron 卻有多個 output 呢?其實,Perceptron 仍然只有一個 output,只是我們將 output 用於多個 Neuron 的 input,因此才畫出多個箭頭。
簡化 Perceptron 的數學算式
以數學形式表示 Perceptron 的運作 [source: Neural Networks and Deep Learning]
在一開始,我們介紹到 Perceptron 的數學算式如上圖所示。然而,這個算式看起來又臭又長,因此我們要將其簡化,主要是做 2 個小改變。
首先,∑wx 是將每一個輸入與權重相乘後的總和,可以單純用「內積」表示:w ⋅ x,兩者皆為向量。此外,我們也可以將 threshold 由不等式的右邊移到左邊,形成:−threshold,−threshold 看起來相當冗長,因此以 b 表示。
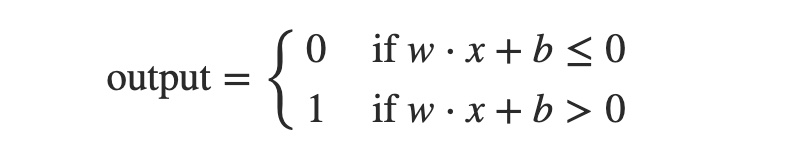
Perceptron 簡化後的數學算式 [source: Neural Networks and Deep Learning]
在深度學習的世界中,我們經常會將 w 稱作 weight,b 稱作 bias。weight 與 bias 都是神經網路模型的參數。在接下來的文章中,我們也會使用 weight 與 bias 來描述神經網路中的參數。
bias 的概念經常讓人覺得有些抽象。如同上文所述的,bias 的前身為 threshold,象徵這一個 Neuron 的輸出有多麽大的機會為 1;以生物學的角度來想,我們也可以將 bias 想成這一個 Neuron 被「激活」的難易度。如果某一個 Neuron 的 bias 是一個很大的數字 (例如 : 100),則無論輸入 x 是什麼,最後的輸出都很可能會是 1 (Neuron 被激活);反之,當 bias 是一個很小的負數 (例如 : -1),則最後的輸出都很可能會是 0。
Perceptron 相當於 NAND Gate
在上文中,我們介紹了 Perceptron 如何將每一個輸入給予不同的權重,並計算相乘後的總和。實際上,Perceptron 也可以作為一個「Logical Function」。最簡單的 Logical Function 相當於我們在數位電路設計的課程中學到的「邏輯閘」,也就是 AND、OR、NOT Gate。
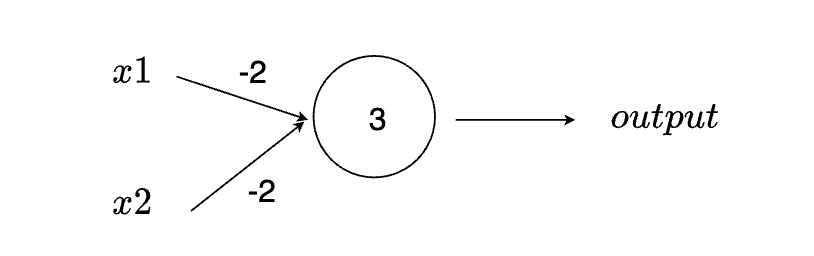
Perceptron 也可以運作的像 NAND Gate 一樣
舉例來說,如上圖所示,我們有一個 Perceptron 接受兩個輸入 (x1 與 x2),兩個輸入的權重 (w1 與 w2) 都是 -2,bias 為 3。我們輸入 00 (x1=0 與 x2=0) 到 Perceptron 中,得到的輸出為 1,因為 (0 × -2) + (0 × -2) + 3 = 3。同樣的,我們輸入 01 與 10 到 Perceptron 中,最後得到的輸入也是 1。然而,如果我們輸入 11,因為 (1 × -2) + (1 × -2) + 3 = -1,所以得到的輸出為 0。由此可知,這一個 Perceptron 的運作,和 NAND Gate 完全相同。
「NAND Gate」!如果你曾經學過數位電路相關的課程,你一定會想到 NAND Gate 是一個「Universal Gate」。也就是說,我們可以透過 NAND Gate 搭建出任何我們想要的 Logical Function。
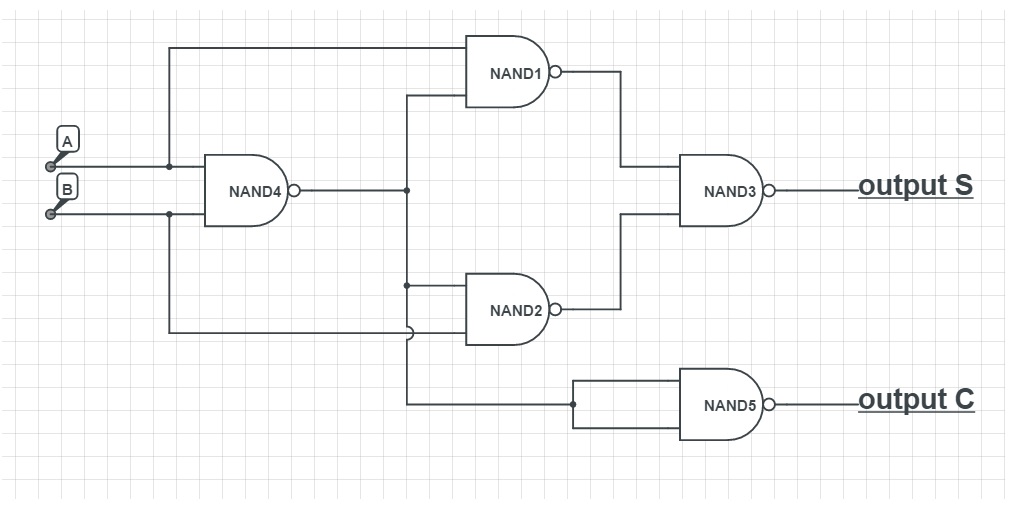
僅透過 NAND Gate 搭建一個加法器 [source: Wikimedia Commons]
舉例來說,在上圖中我們僅透過 NAND Gate 搭建一個加法器 (Half Adder)。又因為 Perceptron 其實可以當作 NAND Gate 來使用,因此我們可以將上圖中所有的 NAND Gate 替換成 Perceptron。
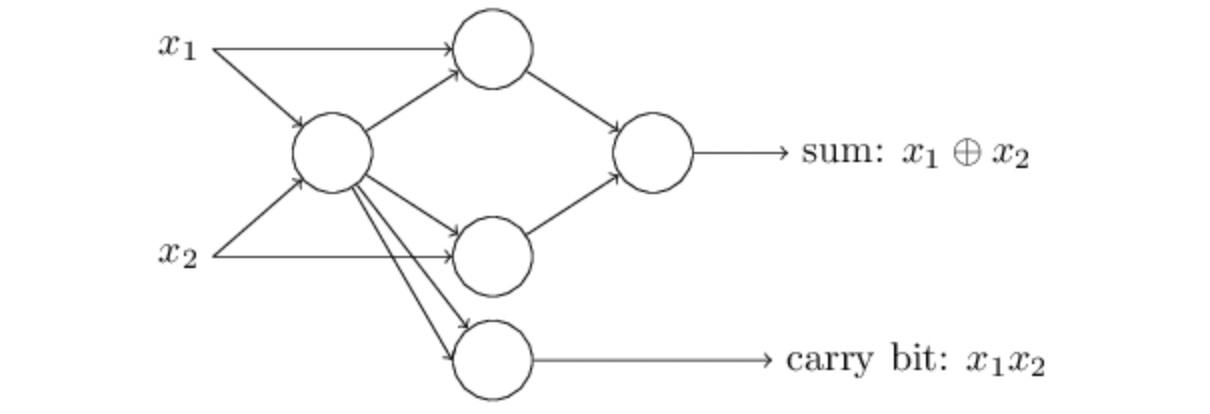
將加法器中的 NAND Gate 都替換成 Perceptron [source: Neural Networks and Deep Learning]
將所有的 NAND Gate 都替換成 Perceptron 後,電路圖瞬間變成了 Neural Network。仔細觀察這一個 Neural Network 可以發現,最左邊的 Neuron 有兩個輸出同時輸入到同一個 Neuron。這對我們來說比較奇怪,因為在前面的 Perceptron 介紹中,我們沒有畫出這樣的輸入與輸出的模式。為了化解疑慮,實際上我們也可以將兩個輸入合成為一個輸入,並將權重由 -2 變為 -4,整個 Neural Network 的運作結果仍然不變。
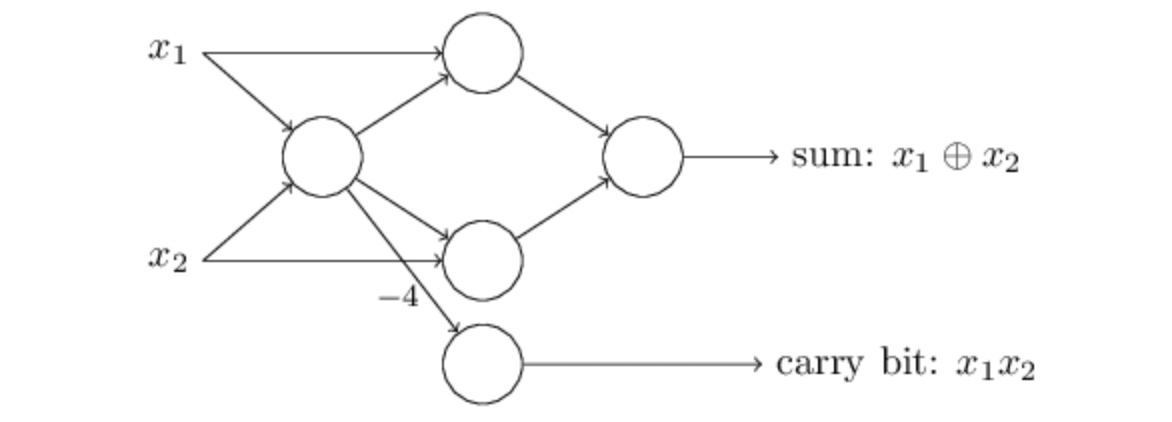
將「兩條 -2」換成「一條 -4」[source: Neural Networks and Deep Learning]
除此之外,我們通常會將 Neural Network 最左邊的輸入也用「Perceptron 的符號」表示:
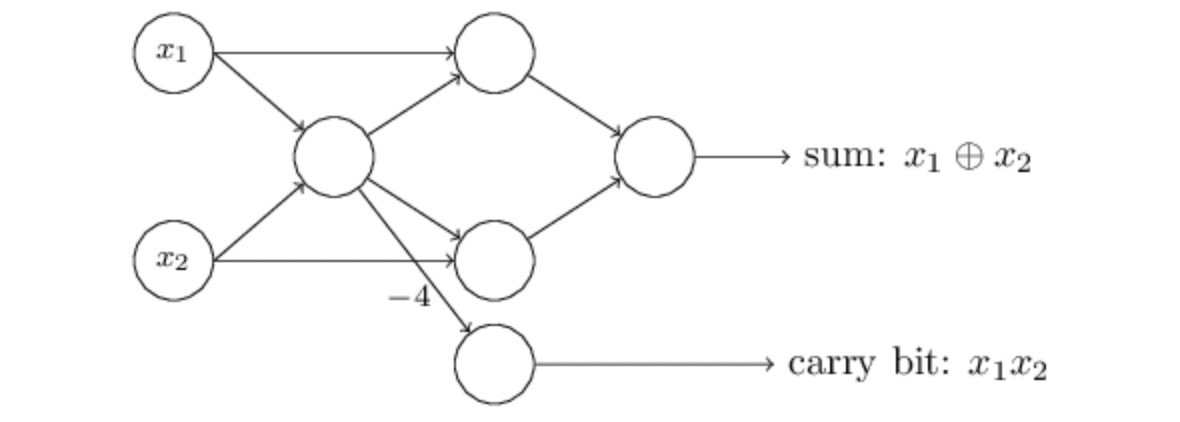
將 Neural Network 最左邊的輸入以 Perceptron 表示形成一個 Layer [source: Neural Networks and Deep Learning]
如上圖所示,當我們將 Neural Network 的輸入 (x1 與 x2) 用 Perceptron 來表示時,最左邊看起來就像是多了一層 (Layer),我們通常稱這一層為「輸入層」(Input Layer)。
然而,你可能會覺得奇怪:為什麼 Input Layer 的 Perceptron 沒有輸入?為了避免這樣的疑慮產生,我們不要將 Input Layer 中的 Neuron 視為真的 Perceptron,而是將他們當作一種特別的 Neuron,表示整個 Neural Network 的輸入。
Perceptron 可以表達任何的運算
由於 Perceptron 相當於 NAND Gate,NAND Gate 又是一種 Universal Gate 可以用來表達任何的運算。因此,我們以可以用 Perceptron 來組成 Neural Network,表達任何的運算。
「Perceptron 可以表達任何的運算」聽起來非常厲害,表示我們可以利用 Perceptron 組合出非常強大的運算裝置;然而,卻也令人失望,畢竟 Perceptron 就是 NAND Gate 化身啊!
但是,也別對 Perceptron、Neural Network 或是 Deep Learning 失去了希望,因為後來許多學者的努力研究,為 Perceptron 加入了其他元素,讓它不僅僅只是 NAND Gate 的化身。其中,最重要的即是「學習演算法」(Learning Algorithm)。透過 Learning Algorithm 我們可以讓 Perceptron「自己」調整參數 (weight 與 bias)!
這讓 Perceptron 與 NAND Gate 產生了很大的不同,我們不需要自己用一個個 Perceptron 組合出一個 Neural Network,然後手動設定 Neural Network 中的參數,而是讓整個 Neural Network 自動去調整自己的參數。
結語
在本篇文章中,我們介紹了 Perceptron 的基本概念,了解 Perceptron 的運作與數學算式。透過 Perceptron 與 NAND Gate 的關係,說明可以利用多個 Perceptron 組成 Neural Network 表達任意的運算。最後我們也提到 Learning Algorithm 讓 Perceptron 不僅僅只是 NAND Gate,而是一個可以自己學習的人工智慧。
在下一篇文章中,我們將會介紹更接近現代 Neural Network 中所使用的 Neuron —— Sigmoid Neuron。