2022 AACL Tutorial: Recent Advances in Pre-trained Language Models

source: First slide in the PDF of this tutorial
前言
本篇文章主要在記錄 AACL-IJCNLP 2022 Tutorial: Recent Advances in Pre-trained Language Models 中所提到的知識點,主要是幫助自己和讀者對於 NLP 中的 Pre-trained Model 有一個大方向的理解,因此並不會全面而且詳細的紀錄!如果你想學習更多,可以再自行觀看影片或是投影片。
本篇主要簡介以下知識點:
- #1: Pre-trained Language Model 學的是 Contextualized Word Representation
- #2: BERTology:理解 BERT 每一個 Layer 究竟學到 Language 的什麼知識
- #3: BERT Embryology:理解 BERT 在訓練時期的什麼階段獲得什麼知識
- #4: Pre-trained Language Model 具有 Cross-Discipline 的能力
- #5: BERT 在 Sentence-Level 的 Representation 能力偏廢
- #6: 學習 Sentence-Level 的 Representation 的優點
- #7: BERT-flow 與 BERT-whitening 幫助 BERT 輸出好的 Sentence Representation
- #8: 透過 Contrastive Learning 幫助 BERT 輸出好的 Sentence Representation
- #9: Parameter-Efficient Fine-tuning 的概念
- #10: PEFT: Adapter
- #11: PEFT: LoRA (Low-Rank Adaptation of Large Language Models)
- #12: PEFT: Prefix Tuning
- #13: PEFT:Soft Prompting
#1: Pre-trained Language Model 學的是 Contextualized Word Representation
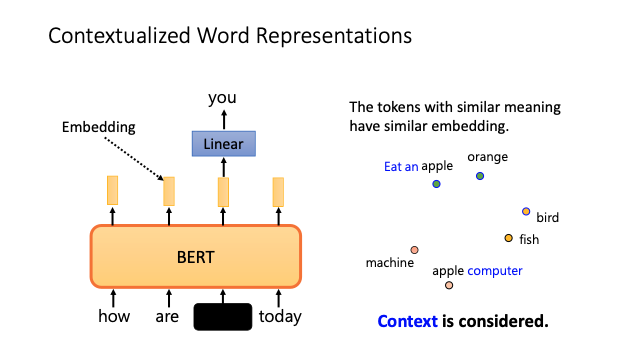
Pre-trained Language Model 學得到的是 Contextualized Word Representation
相較於 Word2vec 與 GloVe 學的是 Word Representation,Pre-trained Language Model 學到的是 Contextualized Word Representation!意思是說,針對同一個 Word 並不會總是是相同的 Representation,而是會根據目前這個 Word 所在的上下文不同而得到不同的 Representation。

相同的 Word 在不同的 Context 下會有不同的意義,而產生不同的 Representation
如上圖所示,「Lie」這個 Word 因為所在的 Context 不同,模型會生成不同的 Representation!
#2: BERTology:理解 BERT 每一個 Layer 究竟學到 Language 的什麼知識
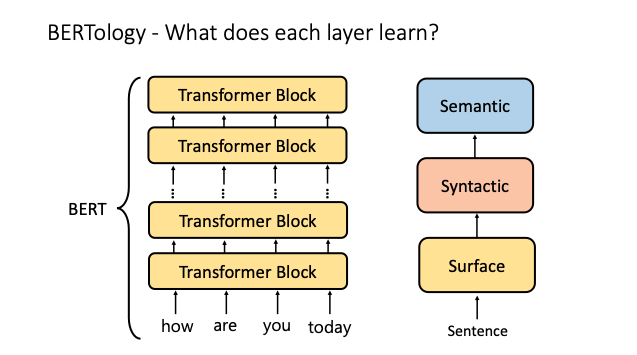
BERT 的前面 Layer 學到 Surface 的意義,中間 Layer 學到 Syntactic 的知識,最後幾個 Layer 則是了解整段句子的 Semantic
如上圖所示,透過一些 Probing 的技術,我們可以分析 BERT 每一層 Layer 輸出的 Representation 主要包含什麼資訊。從一些研究中發現,BERT 在前面幾層 Layer 中主要學到 Language 中比較表層的知識;到了中間 Layer 開始理解這個 Language 的「語法」;在最後的 Layer 中,則是理解這個 Language 的語意。在 BERT Rediscovers the Classical NLP Pipeline (ACL’19) 這篇有名論文中,也揭示了 BERT 模型從第一層到最後一層所學到的東西,就像是一個傳統的 NLP Pipeline 在處理一段句子!後續有一些研究指出,沒辦法這麼單純且直接的劃分 Pre-trained Language Model 每一層分別學到什麼東西,他們的能力是會根據目前輸入的 Input 不同而改變的(如下圖右方所示)。
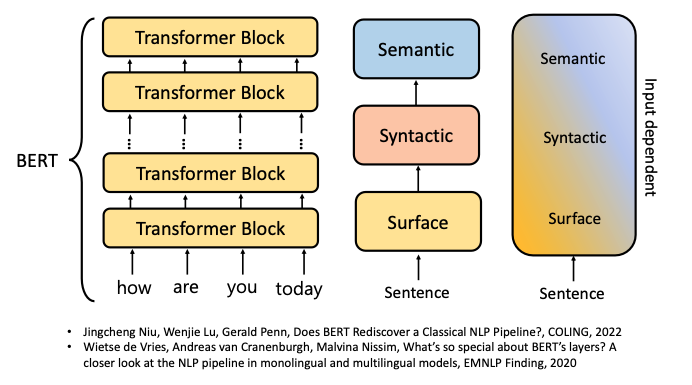
Pre-trained Language Model 中每一層學到的資訊是會受到目前的 Input 影響的
#3: BERT Embryology:理解 BERT 在訓練時期的什麼階段獲得什麼知識
BERT Embryology:理解 BERT 在訓練時期學到什麼資訊
除了理解 Pre-trained Language Model 的每一層分別學到什麼 Language 的知識,在模型整個訓練階段中,分別在哪一個時期學到什麼樣的資訊,也是一個有趣的議題。而這個議題稱為 BERT Embryology!
#4: Pre-trained Language Model 具有 Cross-Discipline 的能力
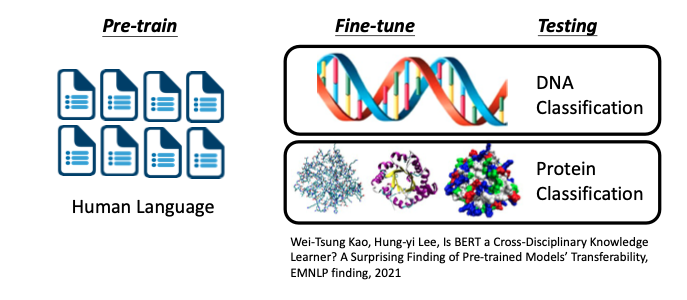
Pre-trained Language Model 具有 Cross-Discipline 的能力
如上圖所示,當我在模型的 Pre-trained 階段,使用大量的 Human Language 讓它學習,而在 Fine-tune 階段讓它學習一個完全不同領域的知識(例如:DNA 序列得分類或是蛋白質結構的分類),這樣對於模型的影響是什麼呢?模型會因為 Pre-trained 階段學了太多不相關的知識,而在 Downstream Task 反而表現得比較差嗎?
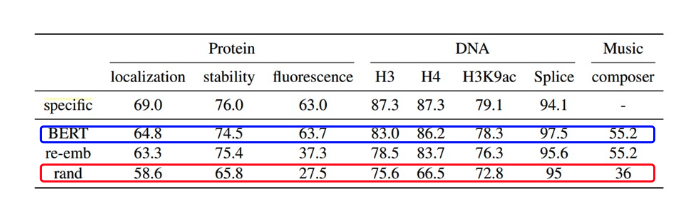
有經過 Pre-trained 的 Model (BERT) 表現得仍然比隨機初始化的 Model (rand) 還要好
從上方的實驗數據可以發現,有經過 Pre-trained 再進行 Fine-tune 模型 (BERT) 仍然比隨機初始化後再進行 Fine-tune 的模型 (rand) 在下游任務上有更好的表現!透過這樣的實驗我們可以推測,Language Model 在 Pre-trained 階段學習到的不僅僅是我們提供給他的資料集的知識,他還可能會學習到一些泛化能力更高,能夠幫助他進行分類的知識。
#5: BERT 在 Sentence-Level 的 Representation 能力偏廢
在 #1 ~ #4 中,我們已經知道 Pre-trained Language Model (BERT) 可以學到 Contextualized Word Representation,然而在 Sentence Representation 上 BERT 學的卻不是那麼好:

BERT 在 Sentence-Level Representation 上學的不好
從上圖可以發現 Sentence-Level 的 Representation 沒辦法很簡單的把所有 BERT 輸出的 Token 的 Representation 平均在一起!神奇的是如果直接把 GloVe 輸出的 Word Representation 直接平均在一起當作 Sentence Representation,其效果都比 BERT 來得好!
#6: 學習 Sentence-Level 的 Representation 的優點
既然做不好的事情,那就不要學就好啦?學習 Sentence Representation 這件事情有那麼重要嗎?
當然!如果我們能夠取得好的 Sentence Representation,將會有以下優點:
- 有一個 Sentence-Level Task 的 Backbone Model
- 更精準的衡量兩個 Sentence 之間的相似度
- 提升對 Sentence 做 Clustering 或是 Semantic Search 的準確度
#7: BERT-flow 與 BERT-whitening 幫助 BERT 輸出好的 Sentence Representation
BERT-flow 論文中提到 BERT 之所以沒辦法學習到好的 Sentence Representation,是因為他在訓練的過程中會將 Sentence 投射到 Non-Smooth Anisotropic 的空間中。換句話說,即使 Embedding Space 夠大,BERT 往往會將這些 Sentence 投射到 Embedding Space 中的某一個區塊,降低了這一個 Embedding Space 的表達能力。

Anisotropy problem in BERT’s representation space
因此在 BERT-flow 中,試圖讓 Sentence Embedding 從 Non-Smooth Anisotropic 的分布變成 Smooth Isotropic 的高斯分布。而 BERT-whitening 提到在後處理階段使用一些 Whitening 技巧,也能夠幫助 Sentence Embedding 的分布更為 Isotropic,進而提升 BERT 輸出好的 Sentence Representation。(如下圖實驗結果所示)
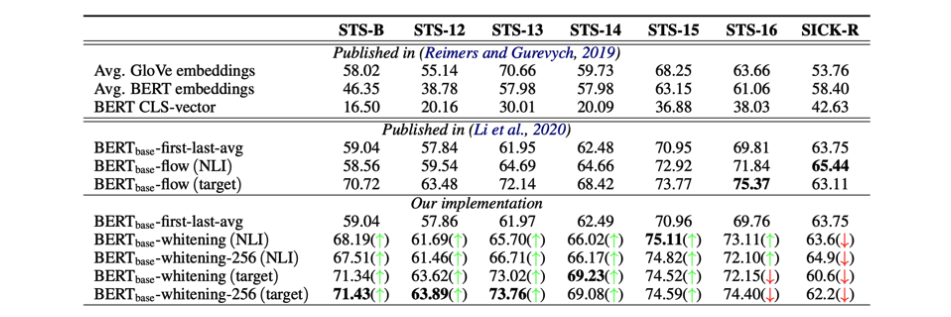
BERT-flow 和 BERt-whitening 提升 BERT 在 Sentence-Level Representation 的表現
#8: 透過 Contrastive Learning 幫助 BERT 輸出好的 Sentence Representation
Self-Supervised Learning (SSL) 在近幾年掀起一個熱潮,在 SSL 中我們可設計一些 Pretext Task 以善用 Unlabeled Data 來訓練模型。舉例來說,在 NLP 領域享譽盛名的 BERT,正是透過 Masked Language Modeling 與 Next Sentence Prediction 這兩個 Pretext Task 訓練出來的 Pre-trained Language Model。SSL 中的方法可以簡單分成 Self-Prediction 與 Contrastive Learning 兩種,像訓練 BERT 所使用的兩個 Pretext Task 正是屬於 Self-Prediction 類型;近幾年 Contrastive Learning 的方法在 Computer Vision 上也不斷創造出很好的成績,在 ImageNet 的圖像分類問題上,已經可以勝過 Supervised Learning 所訓練出來的模型。
如果你對於 SSL 的概念不太了解的話,除了可以看 Hung-Yi Lee 老師的自督導式學習 (Self-supervised Learning) 課程,也可以參考這個 NeurIPS 2021 的 Tutorial(講者可是 Lilian Weng!)。如果你想了解近幾年 Contrastive Learning 在 CV 領域的進展,可以參考這個由中國一位厲害的老師錄製的影片,裏頭快速介紹了 14 篇有名的 Contrastive Learning 論文!(個人覺得真的非常有用)
回歸正題,在這一個 Part 中,講者介紹了許多論文如何使用 Contrastive Learning 的技巧來幫助 BERT 學習到更好的 Sentence Representation。主要可以分為以下幾個類別:
- Designed Positives
- Generating Positives
- Bootstrapping Methods
- Dropout Augmentations
- Equivariant Contrastive Learning
- Prompting
- Ranking-based Methods
接著,我們一一來了解各個類別包含什麼樣的方法!在 Designed Positives 中,主要是透過一些機制來製造出 Contrastive Learning 中需要的 Positive Samples。
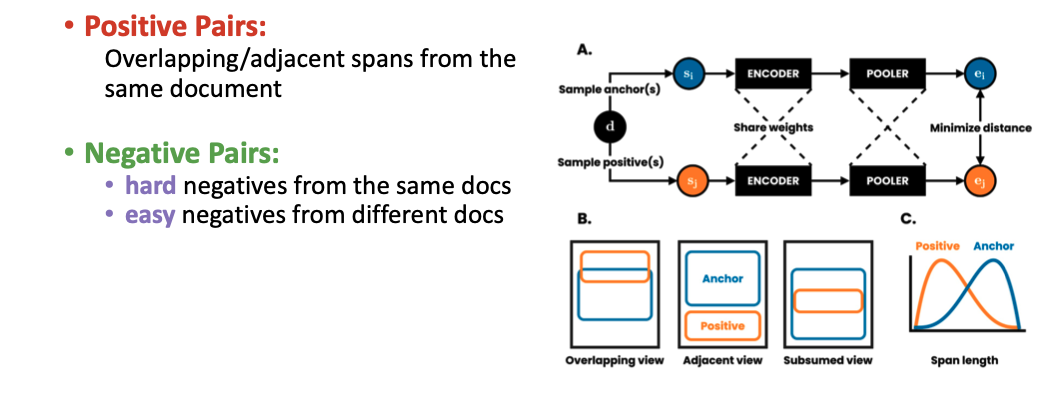
DeCLUTR 透過一份 Document 中 Overlapping 或是 Adjacent 的 Span 來定義 Positive Sample
如上圖所示,在 DeCLUTR 中透過一份 Document 中,這兩個 Span 是否 Overlapping 或是 Adjacent 來定義 Positive Sample。
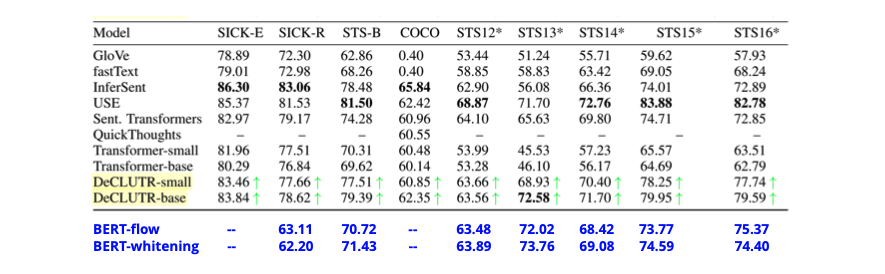
DeCLUTR 的表現勝過 BERT-flow 和 BERT-whitening
從上圖可以發現,Contrastive Learning Based 的方法,其表現勝過 BERT-flow 和 BERT-whitening!
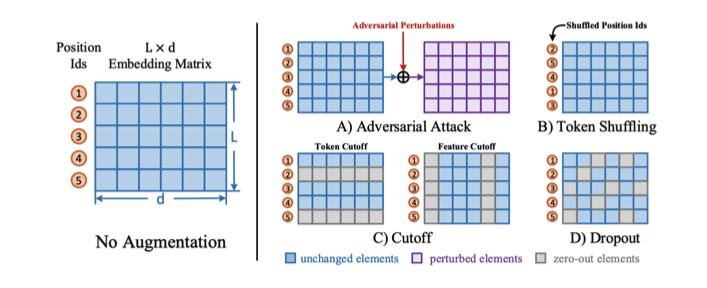
ConSERT 在 Token 的 Embedding Space 上做了各種 Augmentation 生成 Contrastive Learning 所需的 Positive Samples
上圖呈現的是 ConSERT 在 Token 的 Embedding Space 上做了各種 Augmentation 生成 Contrastive Learning 所需的 Positive Samples。
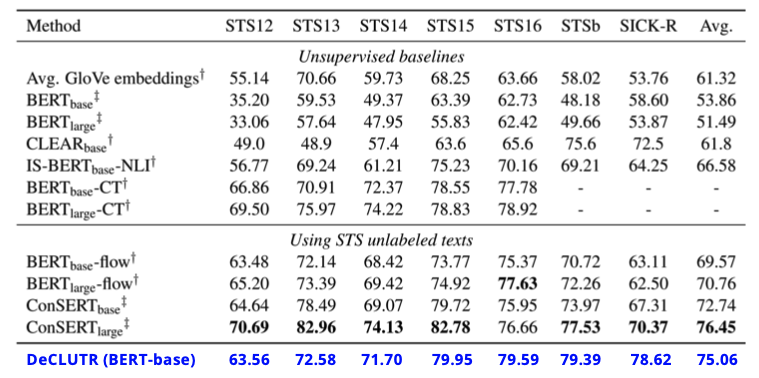
ConSERT 的表現更勝 DeCLUTR
從上圖的實驗數據也可以發現,ConSERT 的表現更勝 DeCLUTR!
除了透過一些 Augmentation 的方法來產生 Positive Sample 外,Generating Positives 類別的方法是透過從無到有的方式直接生成 Positive Sample。

DINO 借助 GPT-2 的力量直接生成 Positive Sample
上圖呈現的是 DINO 這篇論文,直接透過 GPT-2 的力量來生成 Positve Sample。
在 Contrastive Learning 的方法中,Negative Sample 的數量經常扮演著重要的角色,如果 Negative Sample 的數量太少,常常會使得模型沒辦法學習到好的 Representation。但是,自從 Bootstrap Your Own Latent A New Approach to Self-Supervised Learning (BYOL) 這篇論文被提出後,我們就可以在不需要 Negative Sample 的情況下也能夠進行 Contrastive Learning!
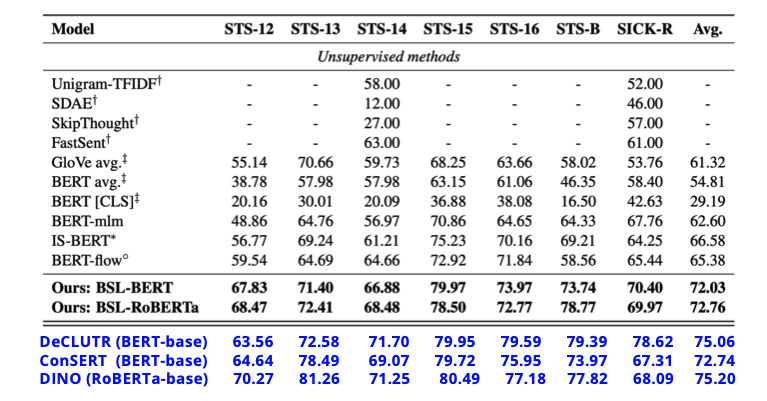
透過 BYOL 幫助 BERT 學習 Sentence Representation (效果不如有包含 Negative Sample 的 Contrastive Learning 方法)
在 Bootstrapping Methods 的類別中,Bootstrapped unsupervised sentence representation learning 這篇論文正是將 BYOL 的想法應用在 BERT 的 Sentence Representation Learning 上,但是就上圖的實驗結果來說,還是略遜於有 Negative Sample 的 Contrastive Learning 方法(DeCLUTR、ConSERT、DINO)。
接著介紹第四種類別的方法「Dropout Augmentations」,代表作為 SimCSE 這篇有名的論文!
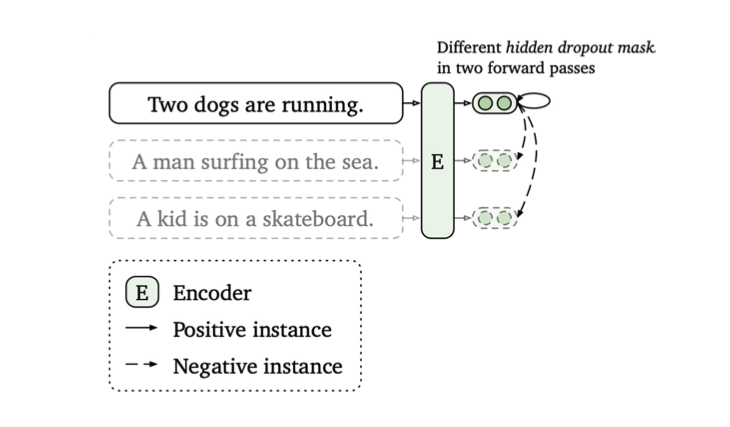
SimCSE 使用 Dropout 來取代直接對 Input 進行 Augmentation
SimCSE 針對 Transformer Layer 進行 Dropout,取代直接對 Input 進行 Augmentation。如上圖所示,同一個 Sentence 輸入到同一個 Model 兩次,這兩次 Model 使用相同的 Dropout Probability 但是不同的 Dropout Ratio,因此得到兩個不同的 Embedding。因為都是來自於同一個 Sentence,就可以作為 Positive Sample!
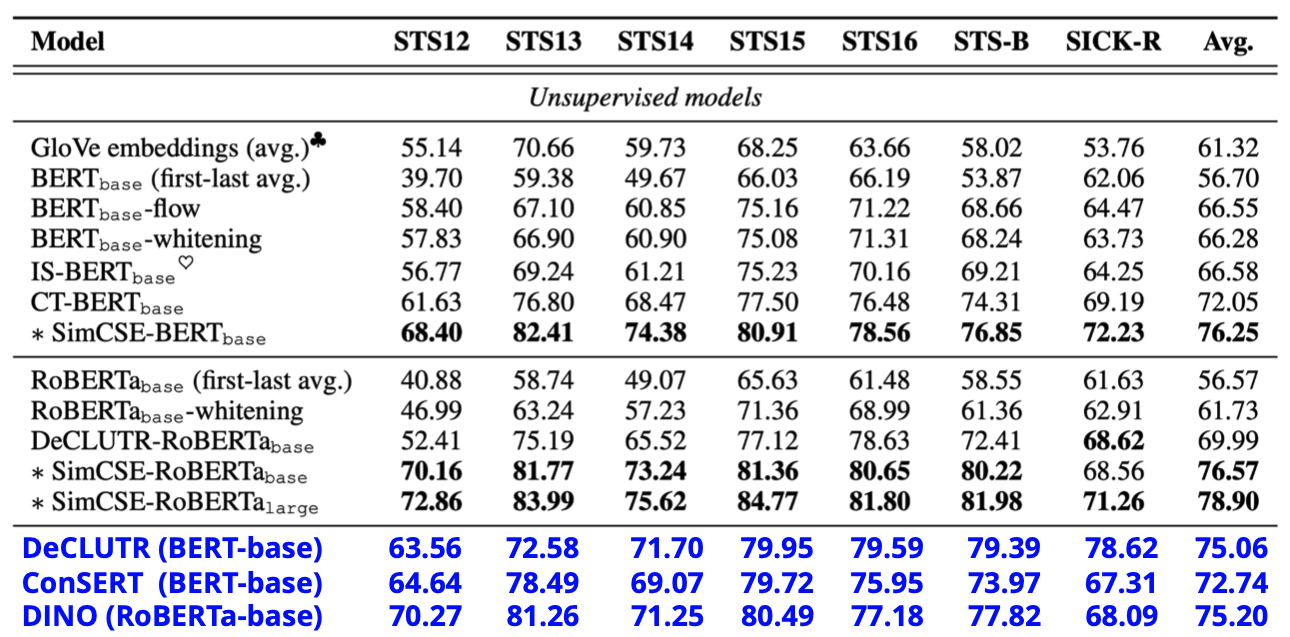
SimCSE 的做法勝過其他以 Data Augmentation 為基礎來生成 Positive Sample 的方法
從上圖的實驗結果可以發現,SimCSE 這種單純對 Model 進行 Dropout 來生成 Positive Sample 的方法,比 DeCLUTR、ConSERT、DINO 等透過一些 Augmentation 方法來生成 Positive Sample 的方法有更好的表現。
第五種類別的方法為「Equivariant Contrastive Learning」,主要是從 SimCSE 發現到「要對 NLP 做 Data Augmentation 不是一件容易的事情」,因為即使做了各種 Augmentation,最後的表現也不及直接對 Model 進行 Dropout 來得好。之所以會在 Contrastive Learning 中使用 Data Augmentation 來產生 Positive Sample,是因爲希望 Model 可以學習到好的 Representation,而且這個 Representation 是 Invariant to Augmentation。然而,從 DeCLUTR、ConSERT、DINO 和 SimCSE 的比較,我們發現這樣的出發點反而會降低模型的表現。
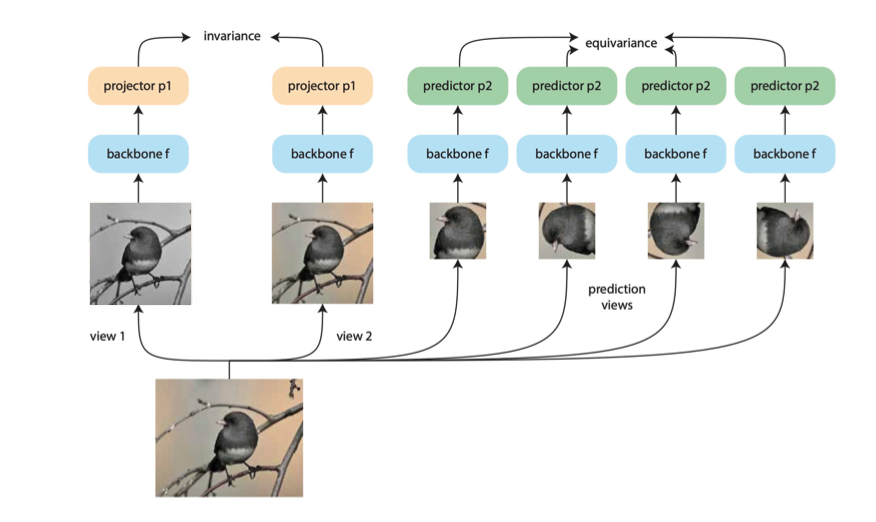
Equivariant Contrastive Learning 中同時包含兩種 Task
因此,在 Equivariant Contrastive Learning 中,發現到有些 Contrastive Learning 的方法希望透過 Invariance Task 讓模型學到好的 Representation(如上圖左),而有些希望透過 Equivariance Task 讓模型學到好的 Representation(如上圖右)。
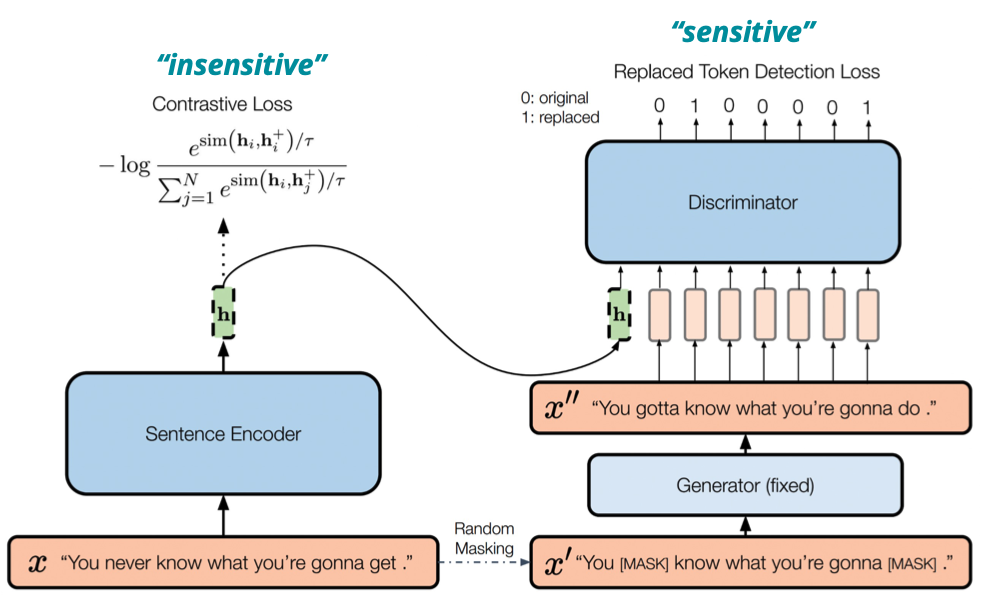
DiffCSE 基於 Equivariant Contrastive Learning 的想法,透過兩種 Task 來訓練 Sentence Encoder
如上圖所示,DiffCSE 基於 Equivariant Contrastive Learning 的想法,透過兩種 Task 來訓練 Sentence Encoder。在 DiffCSE 左半邊進行的是 Invariance Task,而右半邊進行的是 Equivariance Task。最後在 Inference 時,只有模型左半邊的 Sentence Encoder 會拿來使用。
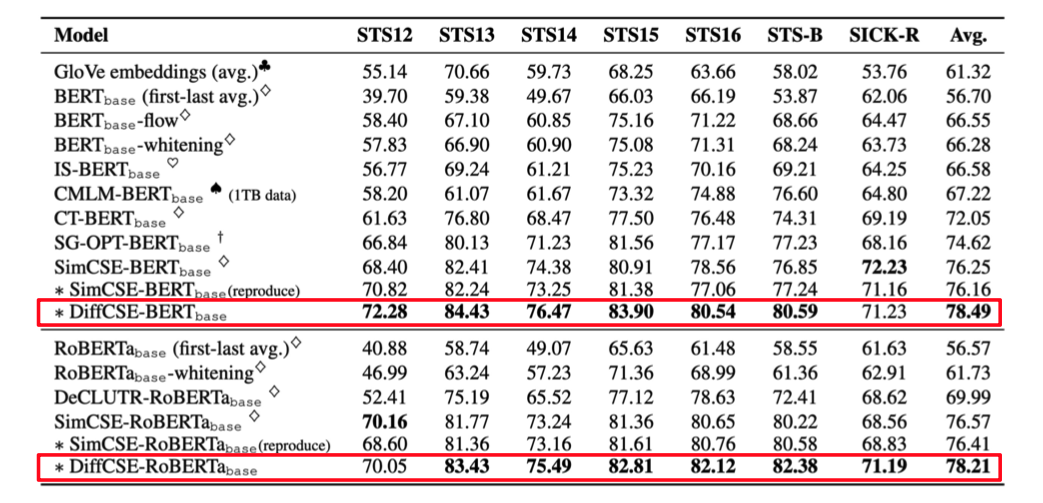
DiffCSE 比 SimCSE 表現得更好
從上圖的實驗結果可以發現,DiffCSE 比 SimCSE 的表現好了約 2% – 3%!
接著來說明下一種類別的方法: Prompting。在此類別的方法中,代表的論文為 PromptBERT: Improving BERT Sentence Embeddings with Prompts。

透過設計 Prompt Template 來學習 Sentence 的 Embedding
如上圖所示,在 PromptBERT 中設計了一些 Prompt Template,給定一個 Sentence,我們將其插入到 Template 中的 [X],再將此 Prompt 輸入到 BERT 中,就可以將 [MASK] Token 所對應到的 Hidden State 當作這個 Sentence 的 Embedding!
最後,來到「Ranking-based Methods」類別。在此類別中的代表方法為 RankEncoder: Ranking-Enhanced Unsupervised Sentence Representation Learning。RankEncoder 透過一個 Sentence 周圍的鄰居,來學習這個 Sentence 的 Embedding。
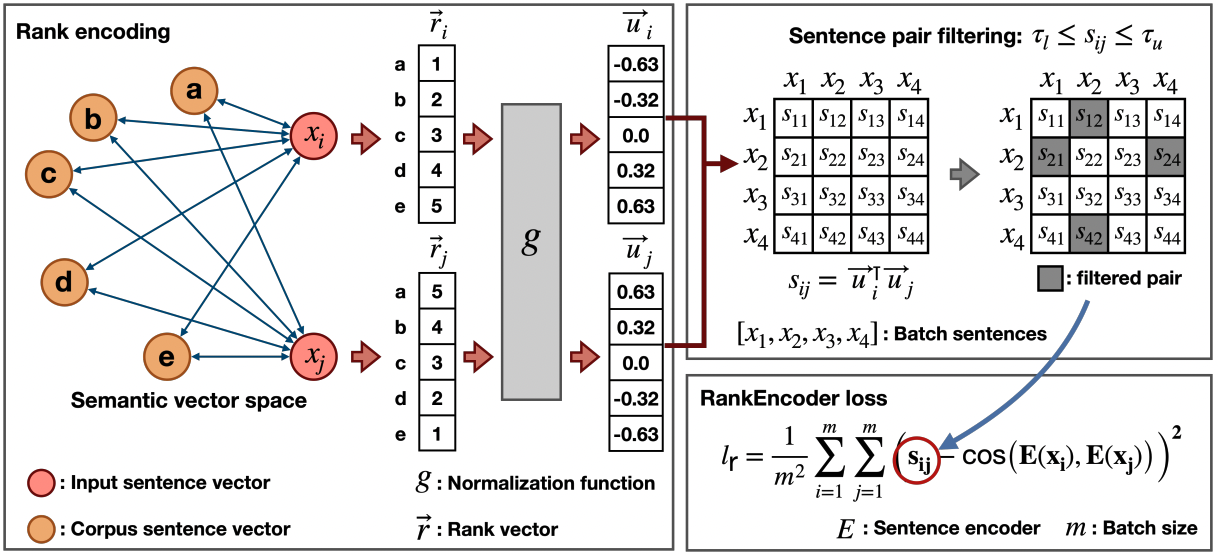
RankEncoder 透過鄰居資訊來學習一個 Sentence 的 Embedding
上圖呈現的是 RankEncoder 的作法:給定兩個 Sentence,分別計算這兩個 Sentence 與外部 Corpus 中 Sentence 的相似度,建立兩個 Rank Vector。接著將這兩個 Rank Vector Normalize 後並內積,得到這兩個 Sentence 的 Similarity。在上圖右下角的地方可以看到,RankEncoder 要學習將這兩個 Sentence 轉為好的 Representation,使得兩個 Representation 的 Cosine Similarity 可以逼近用這兩個 Sentence 的「鄰居資訊」所計算出來的 Similarity。
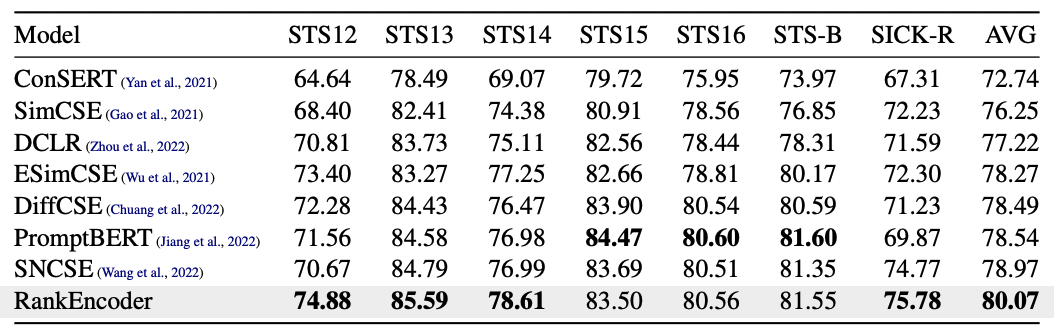
透過 RankEncoder 學習出來的 Sentence Representation 達到 SOTA
從上圖可以看到,RankEncoder 的表現幾乎比前面介紹的所有方法都來得好!
#9: Parameter-Efficient Fine-tuning 的概念
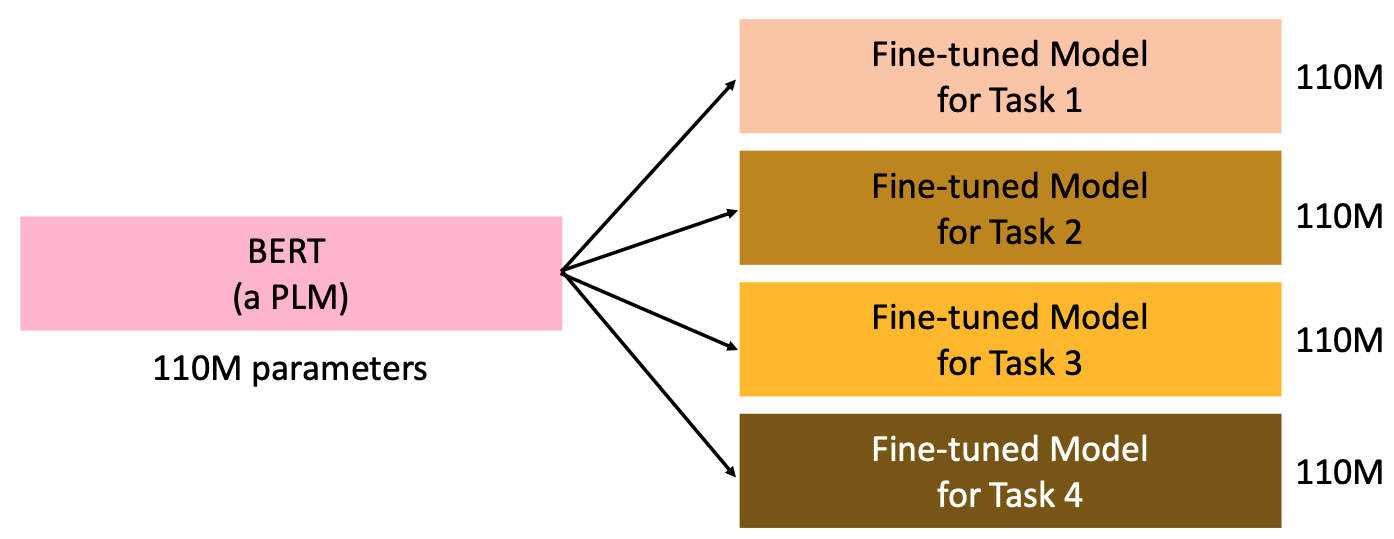
一般的 Finetune 方式中,會對整個 Pre-trained Model 訓練在下游任務
當我們有一個 Pre-trained 過的 Pre-trained Model 後,我們會將其 Finetune 在下游任務。如上圖所示,在一般的 Finetune 方式中,假設我們有 5 個下游任務,我們就會對「整個」 Pre-trained Model 進行 5 次訓練,使得在每一個下游任務中,我們都會儲存一個大小幾乎和 Pre-trained Model 一樣的 Model。
隨著 Pre-trained Model 愈做愈大,受限於 GPU Memory 的大小,一般人幾乎無法再對整個 Pre-trained Model 進行 Finetune,我們需要一種更有效率的 Finetune 方法,讓我們在 Finetune 階段可以不用對這麼多參數進行訓練,而這系列的 Finetune 方法就稱為 Parameter-Efficient Fine-tuning (PEFT)。
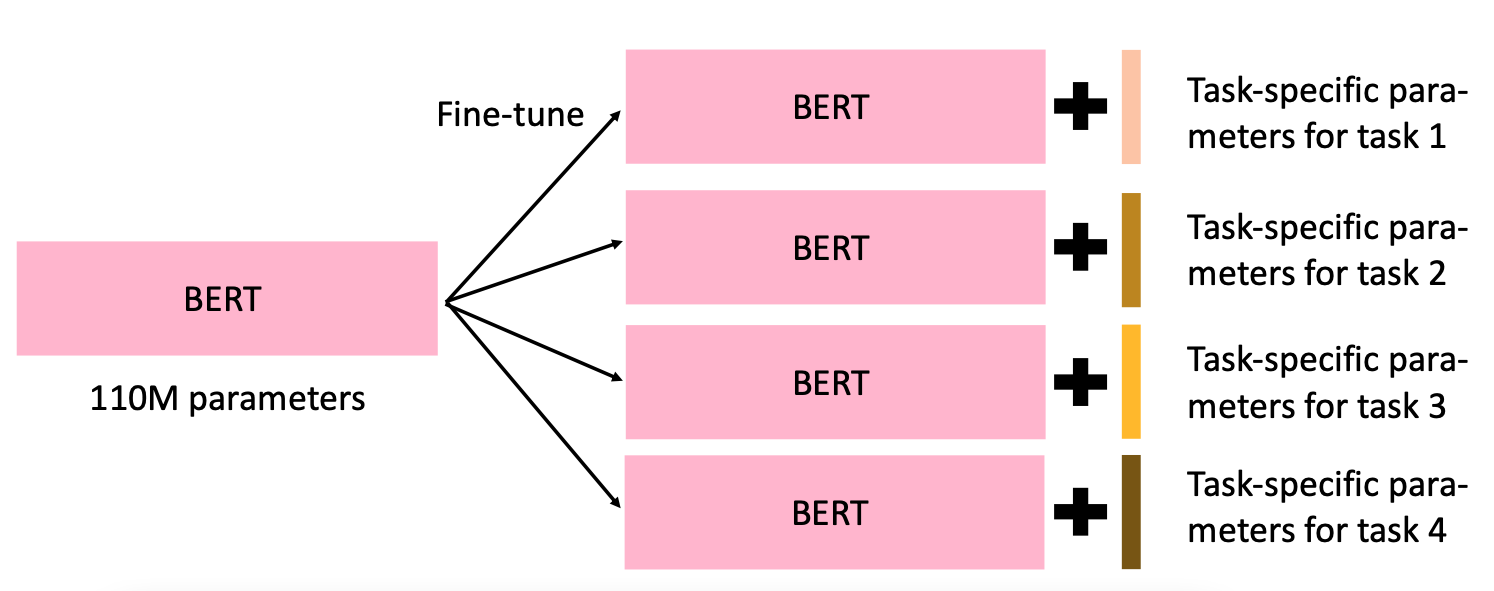
Parameter-Efficient Fine-tuning 在 Pre-trained Model 中加入額外的模組,並指針對這額外的模組進行 Finetune
如同上圖所示,PEFT 透過在 Pre-trained Model 中加入額外的模組,在 Finetune 階段時就只需要對這個額外的模組進行訓練!因此,最終在每一個下游任務中,我們不會再有一整個和 Pretrained Model 一樣大的模型需要保存,而是只需要保存這些額外模組的參數即可。
然而,為什麼 PEFT 可以成功?這需要回歸理解 Finetune 的本質:Finetune 是希望改變 Pre-trained Model 的 Representation,使其在下游任務有更好的表現。
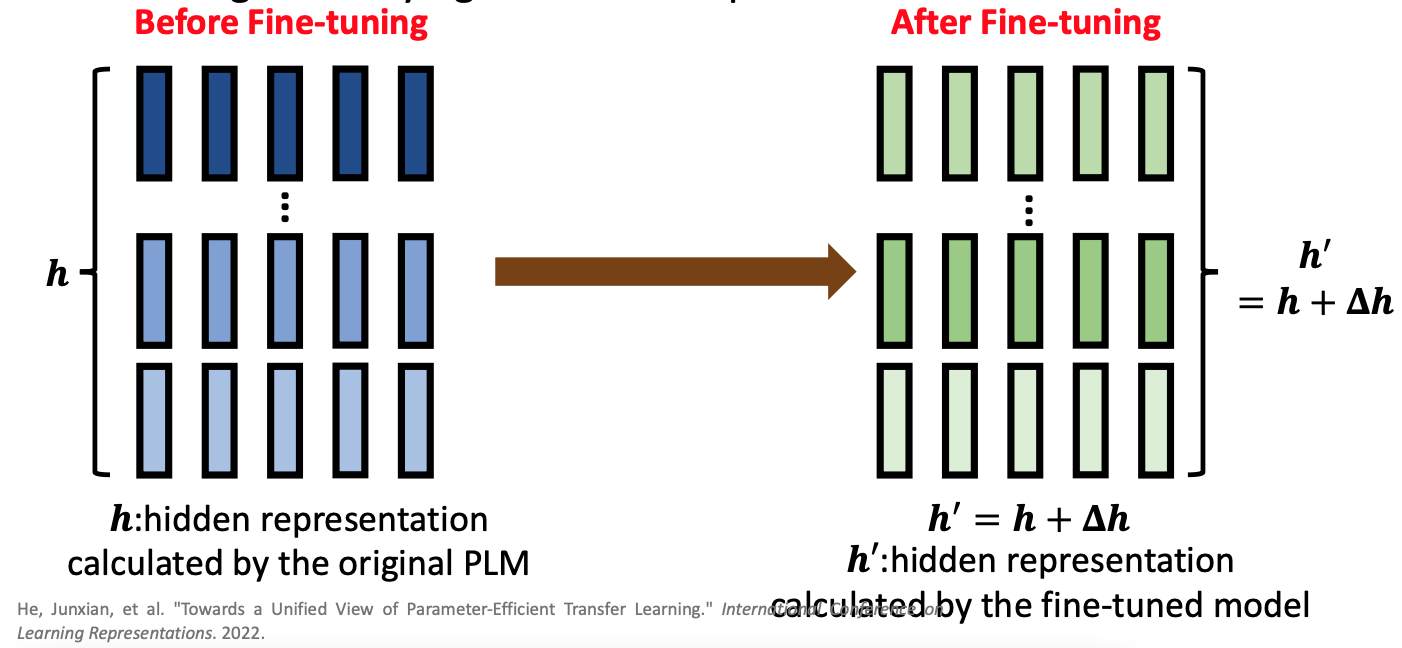
Finetune 是希望改變 Pre-trained Model 的 Representation,使其在下游任務有更好的表現
如同上圖所示,這張圖完美呈現了 Finetune 的意義:原來的 Pretrained Model 的 Representation 是 h,將整個模型進行 Finetune 後,Representation 變成 h_prime。PEFT 的核心思想想是,透過在 Pre-trained Model 中加入額外的模組,使得原來的 Representation h 可以再加上一個額外的 Representation delta_h 變成 h_prime!
PEFT 主要有 4 種實現方法,在以下一一介紹:
- Adpater
- LoRA
- Prefix Tuning
- Soft Prompting
#10: PEFT: Adapter
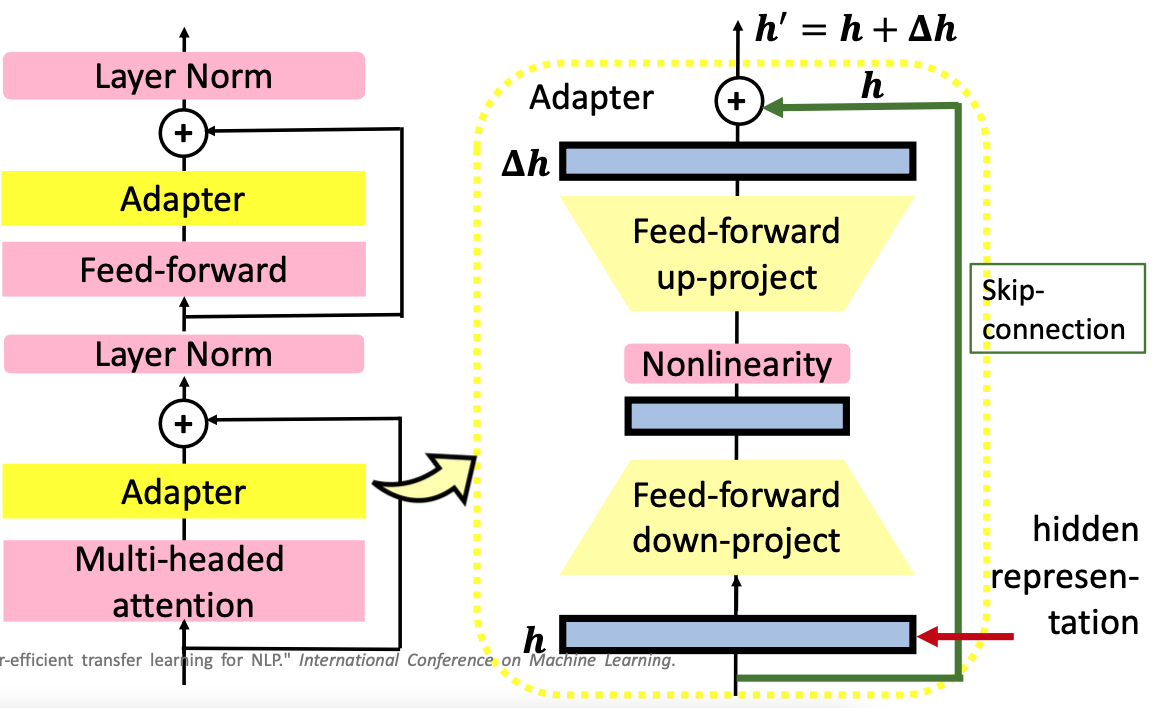
Adapter 示意圖
上圖是 Adapter 的概念,其實就是在一個 Transformer Layer 中的 Multi-Head Self-Attention 後方,以及 Feed-Forward Layer 的後方額外加上一個小模組,這個模組就稱為 Adapter。Adapter 模型架構如上圖右方所示,裡頭包含兩個 Feed-Forward Layer 中間夾一個 Non-Linear Layer,外加上一個 Skip Connection。
透過兩個 Feed-Forward Layer 以及 Non-Linear Layer,可以將原來的 Representation h 轉換 delta_h,再透過 Skip Connection 將 h 與 delta_h 相加在一起得到 Finetune 後的 Representation h_prime。
#11: PEFT: LoRA (Low-Rank Adaptation of Large Language Models)
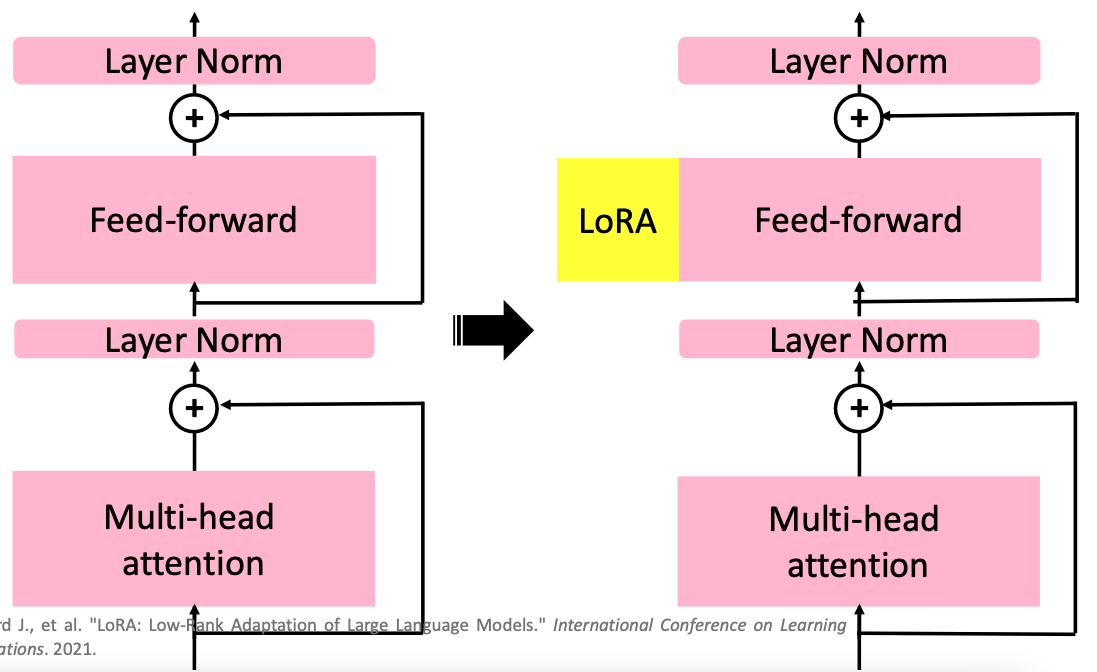
LoRA 示意圖
如上圖所示,LoRA 的作法是在 Transformer Layer 中的 Feed-Forward Layer 旁邊多加上一些模組。
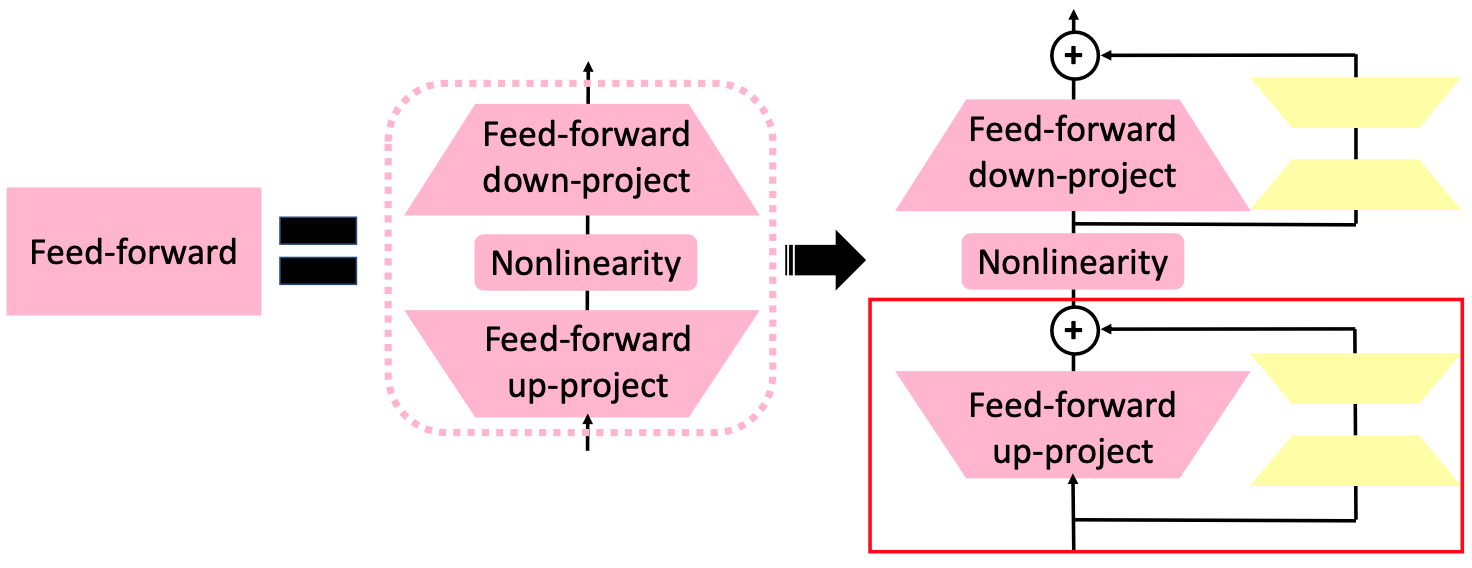
LoRA 的作法是在 Transformer Layer 的 Feed-Forward Layer 旁額外加上一個分支
LoRA 的具體作法如上圖所示,Transformer Layer 中的 Feed-Forward Layer 實際上由兩個 Layer 組成。而 LoRA 就是在這兩個 Layer 的旁邊多加上一個模組,且這個模組也是由兩個 Layer 所組成。
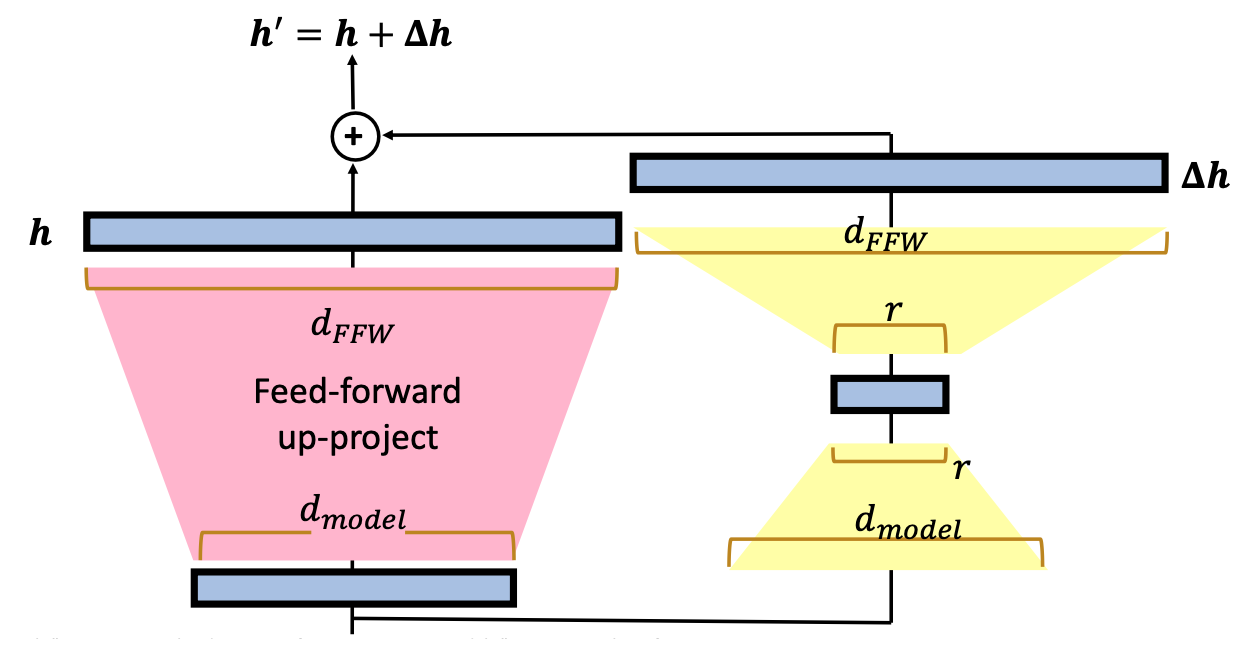
LoRA 模組會將原來的 Representation 投射到一個特別小的維度上後,再放大得到新的 Representation
比較特別的是,LoRA 模組會將原來的 Input 投射到一個特別小的維度上後,再放大得到新的 Representation (delta_h)。再與原來的 Representation (h) 相加後得到 Finetune 後的 Representation (h_prime)。
#12: PEFT: Prefix Tuning
從字面上來看,Prefix 指的是在某個東西的「前方」再加上一些東西,而 Prefix Tuning 其實就是指針對這個加在其他東西「前方」的東西去做 Finetune。
要了解 Prefix Tuning 怎麼實現的,我們需要先複習 Self-Attention 的觀念:
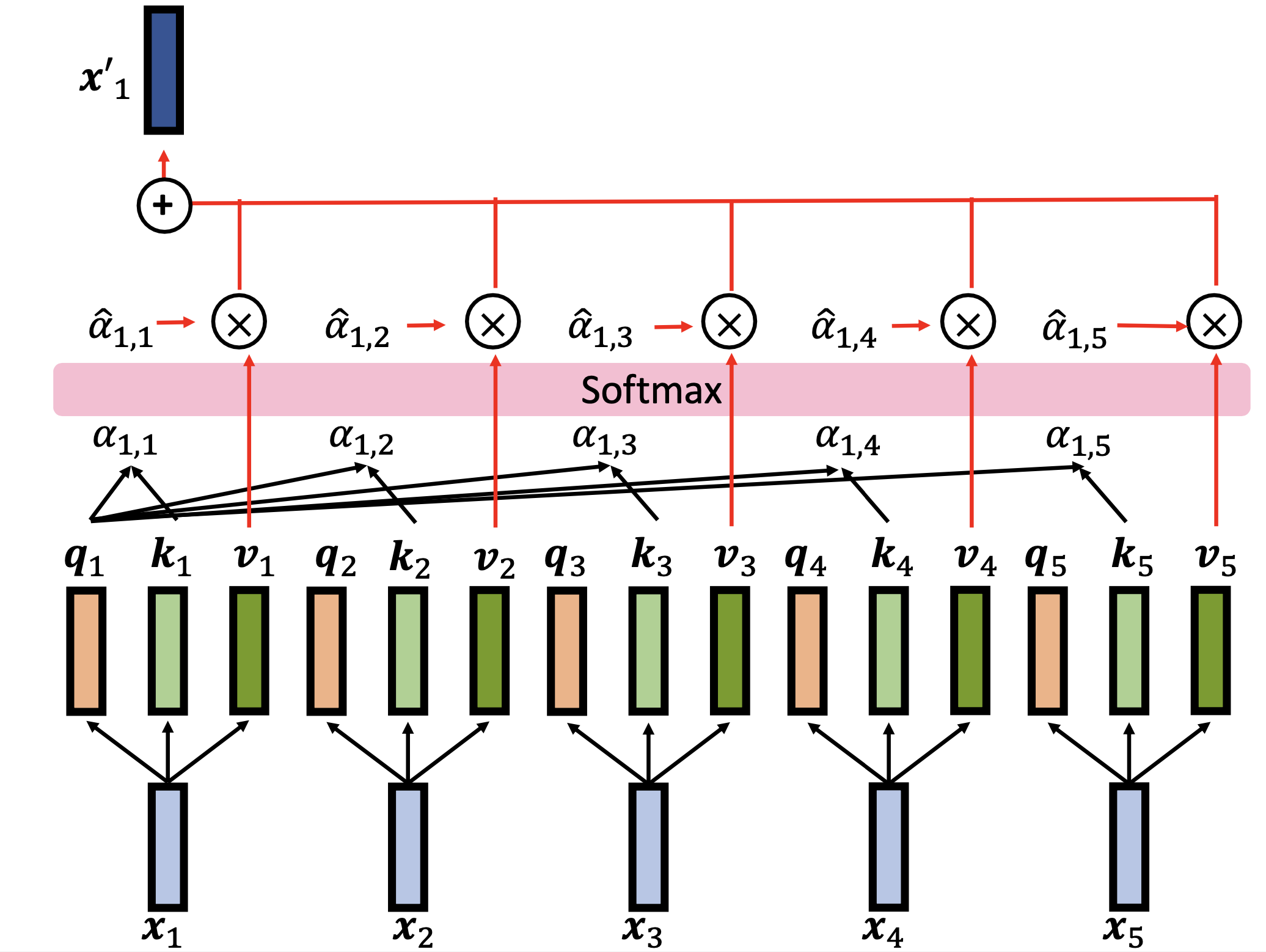
Self-Attention 的原理
上圖呈現的是 Self-Attention 的原理:Sequence 中的每一個 Vector 都會透過一組 Query Projection、Key Projection 與 Value Projection,得到自己的 Query、Key 與 Value。當我們想要計算 x1 的輸出時,就會將 x1 的 Query 與所有 Vector(包含自己) 的 Key 進行運算得到 Attention Score。Attention Score 即表示 x1 與每個 Vector 有多關聯。接著再透過 Attention Score 將所有 Vector 的 Value 進行 Weighted Sum 得到 x1 的輸出。
在 Prefix Tuning 中,我們會在 Self-Attention Layer 的輸入的「前面」多加上一些 Vector,這些 Vector 就被稱為 Prefix:
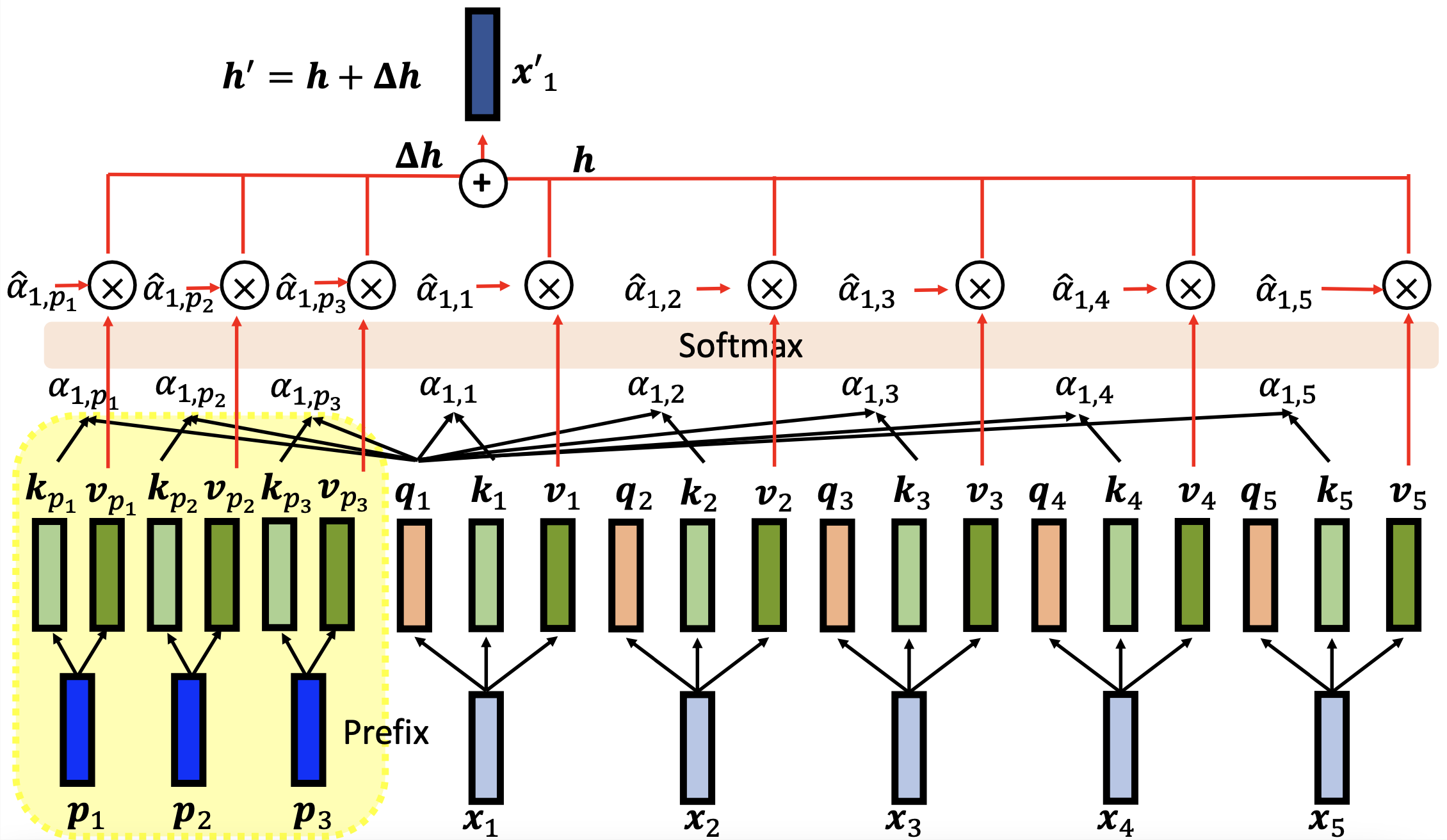
Prefix Tuning 就是在 Self-Attention Layer 的 Input Sequence 的前方再多加入一些 Vector
如上圖所示,透過在 Input Sequence 多加上一些 Prefix,現在我們要計算 x1 的輸出時,就還需要額外把 Prefix 的 Query、Key 和 Value 也考慮進去。將原來的 Vector 的 Value 做 Weighted Sum 得到原來的 Representation (h) 與 Prefix 的 Value 的 Weighted Sum 的 Representation (h_delta) 加總在一起後,最後我們得到一個 Finetune 過後的 Representation (h_prime)。
#13: PEFT:Soft Prompting
Adapter、LoRA 與 Prefix Tuning 算是 PEFT 中最常見的三種手法,第 4 種也是是最常被忽略的方法為 Soft Prompting。
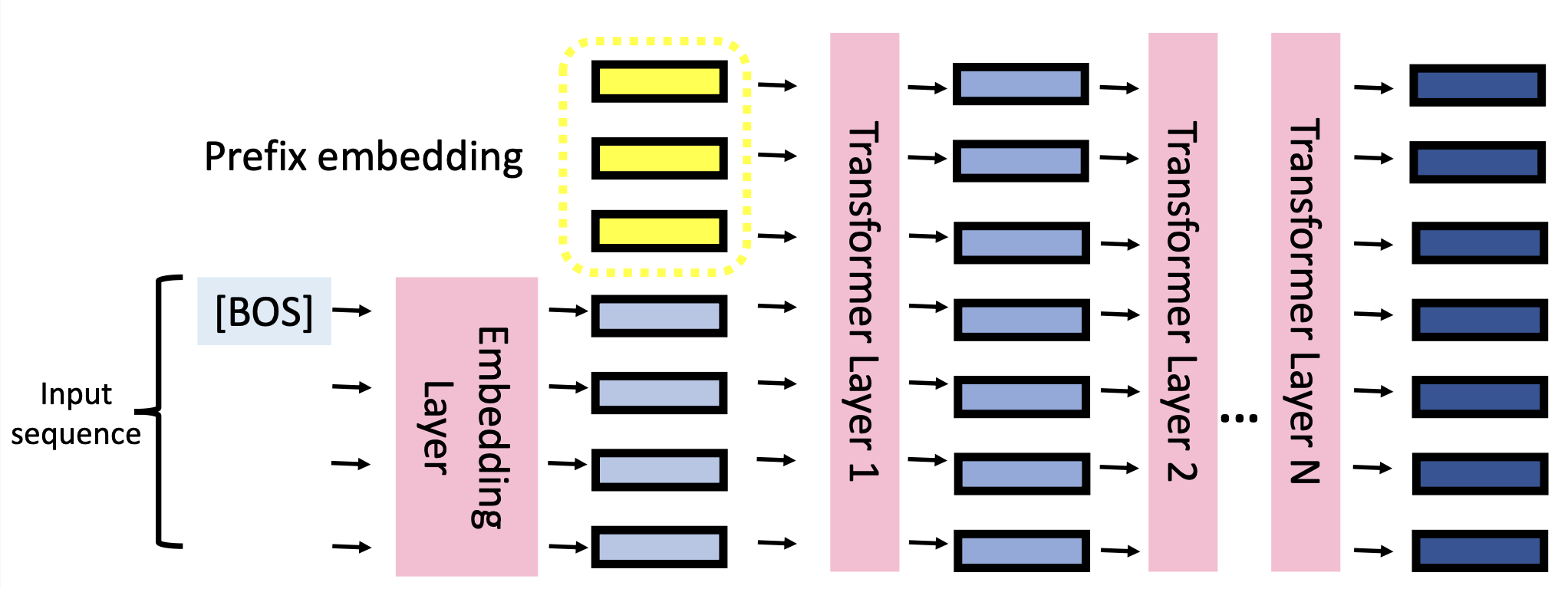
Soft Prompting 就是在 Embedding Layer 的輸出額外加上一些 Prefix Embedding
如上圖所示,Soft Prompting 就是在 Embedding Layer 的輸出額外加上一些 Prefix Embedding:原來的 Input Sequence 經過 Embedding Layer 後會得到藍色的 Embedding。但是我們額外多加上一些 Prefix Embedding,將他們一起輸入到 Transformer 中。
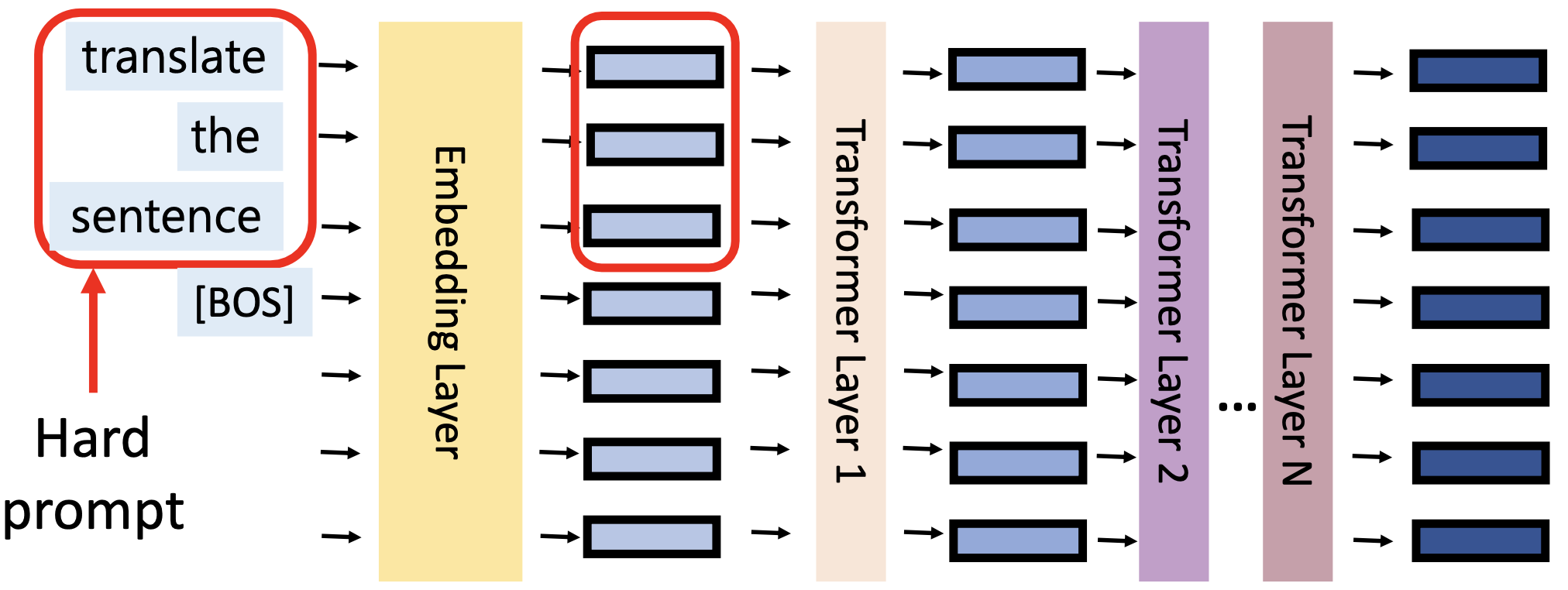
Hard Prompting 則是直接在 Input Sequence 中加入額外的 Word
Soft Prompting 的相反為 Hard Prompting,就是一般我們所認知的 Prompt,就是在最一開始的 Input Sequence 中加入額外的 Word。
結語
本篇文章主要在記錄 AACL-IJCNLP 2022 Tutorial: Recent Advances in Pre-trained Language Models 中所提到的部分知識點,幫助自己和讀者對於 NLP 中的 Pre-trained Model 有一個大方向的理解,因此並不會全面而且詳細的紀錄!當然,本篇文章中大部分的插圖都是節錄自這個 Tutorial 的內容,因此如果你想學習更多、更完整的內容,請再自行觀看影片或是投影片!